Load
L'instruction LOAD charge des champs à partir d'un fichier, de données définies dans le script, d'une table déjà chargée, d'une page Web, du résultat d'une instruction SELECT ultérieure ou via la génération automatique de données. Il est également possible de charger des données à partir de connexions analytiques.
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]|
inline data [ format-spec ] |
resident table-label |
autogenerate size ) |extension pluginname.functionname([script] tabledescription)]
[ where criterion | while criterion ]
[order by orderbyfieldlist ]
| Argument | Description |
|---|---|
| distinct |
Vous pouvez utiliser distinct en tant que prédicat si vous ne souhaitez charger que des enregistrements uniques. En cas d'enregistrements en double, seule la première instance sera chargée. Si vous utilisez des instructions de chargement antérieures, vous devez placer distinct dans la première instruction LOAD, car distinct n'affecte que la table de destination. |
| fieldlist |
fieldlist ::= ( * | field {, * | field } )
Liste des champs à charger. L'utilisation du symbole * comme liste de champs signifie inclure tous les champs de la table. field ::= ( fieldref | expression ) [as aliasname ]La définition du champ doit toujours contenir un littéral, une référence à un champ existant ou une expression. fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname est un texte identique à un nom de champ dans la table. Notez que le nom du champ doit être mis entre guillemets doubles droits ou entre crochets s'il contient des espaces, par exemple. Les noms des champs ne sont pas toujours disponibles de manière explicite. Une notation différente est alors utilisée : @fieldnumber représente le numéro du champ dans un fichier de table délimité. Il doit s'agir d'un entier positif précédé d'un arobase (@). La numérotation est toujours effectuée de 1 jusqu'au nombre total de champs. @startpos:endpos représente les positions de début et de fin d'un champ dans un fichier contenant des enregistrements de longueur fixe. Ces positions doivent être toutes deux des entiers positifs. Les deux nombres doivent être précédés d'un arobase (@) et séparés par deux-points. La numérotation est toujours effectuée de 1 jusqu'au nombre total de positions. Dans le dernier champ, n est utilisé comme position de fin.
expression peut correspondre à une fonction numérique ou une fonction de chaîne basée sur un ou plusieurs autres champs de la même table. Pour plus d'informations, voir la syntaxe des expressions. |
| from |
from est utilisé si les données doivent être chargées à partir d'un fichier au moyen d'une connexion de données de type Dossier ou Fichier Web. file ::= [ path ] filename 'lib://Table Files/' Si le chemin d'accès est omis, Qlik Sense recherche le fichier dans le répertoire que lui indique l'instruction Directory. En l'absence d'instruction Directory, Qlik Sense effectue une recherche dans le répertoire de travail, C:\Users\{user}\Documents\Qlik\Sense\Apps. Note InformationsDans une installation de serveur Qlik Sense, le répertoire de travail est spécifié dans Qlik Sense Repository Service ; par défaut, il s'agit de C:\ProgramData\Qlik\Sense\Apps. Consultez l'aide de Console de gestion Qlik pour plus d'informations.
L'argument filename peut contenir les caractères génériques DOS standard (* et ?). Tous les fichiers correspondants sont alors chargés dans le répertoire indiqué. format-spec ::= ( fspec-item { , fspec-item } )La spécification du format se compose d'une liste de plusieurs éléments de spécification du format, mis entre parenthèses. Éléments de spécification du format Note ConseilVous pouvez utiliser la spécification de format URL is pour remplacer l'URL d'une connexion de données de type Fichier Web, notamment lorsque vous devez créer une URL dynamique basée sur d'autres données déjà chargées.
Mode de script hérité En langage de script, les formats de chemin d'accès suivants sont également pris en charge en mode hérité :
|
| from_field | from_field est utilisé si les données doivent être chargées à partir d'un champ précédemment chargé. fieldassource::=(tablename, fieldname) Le champ correspond au nom des arguments tablename et fieldname précédemment chargés. format-spec ::= ( fspec-item {, fspec-item } )La spécification du format se compose d'une liste de plusieurs éléments de spécification du format, mis entre parenthèses. |
| inline | inline est utilisé si les données doivent être saisies dans le script au lieu d'être chargées à partir d'un fichier. data ::= [ text ] Les données saisies à l'aide d'une clause inline doivent être mises entre guillemets ou entre crochets. Le texte placé entre ces guillemets ou crochets est interprété de la même manière que le contenu d'un fichier. C'est pourquoi vous devez également insérer une nouvelle ligne dans la clause inline, là où vous en auriez inséré une dans un fichier texte. Pour ce faire, appuyez sur la touche Entrée lors de la saisie du script. Le nombre de colonnes est défini dans la première ligne. format-spec ::= ( fspec-item {, fspec-item } )La spécification du format se compose d'une liste de plusieurs éléments de spécification du format, mis entre parenthèses. |
| resident | resident est utilisé si les données doivent être chargées à partir d'une table précédemment chargée. table label est une étiquette précédant l'instruction LOAD ou SELECT ayant créé la table de départ. L'étiquette doit être saisie avec deux-points à la fin. |
| autogenerate | autogenerate est utilisé si les données doivent être générées automatiquement par Qlik Sense. size ::= number Number est un entier indiquant le nombre d'enregistrements à générer. La liste de champs ne doit pas contenir d'expressions nécessitant des données provenant d'une source de données externe ou d'une table chargée précédemment, à moins que vous ne fassiez référence à une valeur de champ unique dans une table chargée au préalable à l'aide de la fonction Peek. |
| extension |
Vous pouvez charger des données à partir de connexions analytiques. Vous devez utiliser la clause extension pour appeler une fonction définie dans le plug-in SSE (Server-Side Extension) ou pour évaluer un script. Il est possible d'envoyer une seule table au plug-in SSE ; une seule table de données est alors renvoyée. Si le plug-in ne précise pas les noms des champs renvoyés, les champs seront nommés Field1, Field2, et ainsi de suite. Extension pluginname.functionname( tabledescription );
Gestion des types de données dans la définition des champs de table Les types de données sont automatiquement détectés dans les connexions analytiques. Si les données ne comportent aucune valeur numérique et comprennent au moins une chaîne de texte non NULLE, le champ est interprété comme du texte. Dans tous les autres cas, il est considéré comme de type numérique. Vous pouvez appliquer un type de données forcé en encadrant le nom d'un champ à l'aide de String() ou de Mixed().
Il est impossible d'utiliser String() ou Mixed() en dehors des définitions de champ de table extension. De plus, vous ne pouvez pas utiliser d'autres fonctions Qlik Sense dans une définition de champ de table. Informations complémentaires sur les connexions analytiques Avant de pouvoir utiliser des connexions analytiques, vous devez les configurer. Qlik Sense Enterprise: Création d'une connexion analytique (uniquement en anglais) Qlik Sense Desktop: Configuration de connexions analytiques dans Qlik Sense Desktop Vous trouverez des informations complémentaires sur les connexions analytiques dans le référentiel GitHub : qlik-oss/server-side-extension. |
| where | where est une clause utilisée pour indiquer si un enregistrement doit être inclus ou pas dans la sélection. La sélection est incluse si l'expression criterion est définie sur True. criterion est une expression logique. |
| while |
while est une clause utilisée pour indiquer si un enregistrement doit être lu plusieurs fois. Le même enregistrement est lu tant que l'expression criterion est définie sur True. Pour être utile, une clause while doit généralement inclure la fonction IterNo( ). criterion est une expression logique. |
| group by |
group by est une clause utilisée pour déterminer les champs sur lesquels les données doivent être agrégées (groupées). Les champs d'agrégation doivent être inclus d'une manière ou d'une autre dans les expressions chargées. Aucun autre champ que les champs d'agrégation ne peut être utilisé en dehors des fonctions d'agrégation dans les expressions chargées. groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order by | order by est une clause utilisée pour trier les enregistrements d'une table résidente avant qu'ils ne soient traités par l'instruction load. La table résidente peut être triée par un ou plusieurs champs, par ordre croissant ou décroissant. Le tri est principalement effectué par valeur numérique, puis par valeur de paramètres régionaux de classement national. Cette clause peut uniquement être utilisée lorsque la source de données est une table résidente. Les champs de tri indiquent les champs selon lesquels la table résidente est triée. Le champ peut être spécifié par son nom ou par son numéro dans la table résidente (le premier champ est le numéro 1). orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder correspond soit à asc pour un ordre croissant, soit à desc pour un ordre décroissant. Si aucun argument sortorder n'est spécifié, c'est asc qui est utilisé. fieldname, path, filename et aliasname sont des chaînes textuelles représentant ce que ces noms désignent. N'importe quel champ de la table source peut être utilisé comme fieldname. Toutefois, les champs créés via la clause as (aliasname) ne sont pas concernés et ne peuvent pas être utilisés dans la même instruction load. |
Si aucune source de données n'est fournie par les clauses from, inline, resident, from_field, extension ou autogenerate, les données sont chargées à partir du résultat de l'instruction SELECT ou LOAD qui suit immédiatement. L'instruction qui suit ne doit pas comporter de préfixe.
Chargement de données à partir d'une table déjà chargée
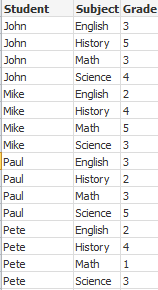
Dans cet exemple, soit un fichier d'entrée nommé Grades.csv contenant les notes des étudiants condensées dans un champ :
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
Les notes, comprises sur une échelle de 1 à 5, représentent les matières Math, English, Science et History (maths, anglais, sciences et histoire). Nous pouvons séparer les notes en valeurs distinctes en lisant chaque enregistrement plusieurs fois à l'aide d'une clause while au moyen de la fonction de décompte IterNo( ). Lors de chaque lecture, la note est extraite au moyen de la fonction Mid et stockée dans Grade tandis que la matière est sélectionnée à l'aide de la fonction pick et conservée dans Subject. La clause while finale contient le test permettant de vérifier que toutes les notes ont été lues (quatre par étudiant dans ce cas), ce qui signifie que l'enregistrement d'étudiant suivant doit être lu.
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from Grades.csv
while IsNum(mid(Grades,IterNo(),1));
Le résultat est une table contenant les données suivantes :