メイン コンテンツをスキップする
補完的コンテンツへスキップ
Qlik.com
Community
Learning
Qlik リソース
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
閉じる
ドキュメント
クラウド
Client-Managed
追加のドキュメント
クラウド
Qlik Cloud
ホーム
紹介
Qlik Cloud の新機能
Qlik Talend Cloud について
分析
データ統合
管理
自動化
Qlik 開発者
Talend Cloud
ホーム
リリース ノート
API Portal
他のクラウド ソリューション
Stitch
Upsolver
Client-Managed
クライアント管理 — 分析
ユーザー向けの Qlik Sense
管理者向け
Qlik Sense
開発者向け
Qlik Sense
Qlik NPrinting
Connectors
Qlik GeoAnalytics
Qlik Alerting
ユーザーと管理者向けの
QlikView
開発者向け
QlikView
Governance Dashboard
クライアント管理 — データ統合
Qlik Replicate
Qlik Compose
Qlik Enterprise Manager
Qlik Gold Client
Qlik Catalog
NodeGraph (legacy)
Qlik Talend
Talend Studio
Talend ESB
Talend Administration Center
Talend Data Catalog
Talend Data Preparation
Talend Data Stewardship
追加のドキュメント
追加のドキュメント
Qlik ドキュメンテーション アーカイブ
Talend ドキュメンテーション アーカイブ
オンボーディング
分析を開始
データ統合を開始する
分析ユーザーのオンボーディング
Qlik Sense で分析を開始
Qlik Cloud Analytics Standard の管理
Qlik Cloud Analytics Premium および Enterprise の管理
Qlik Sense
Business
の管理
Qlik Sense
Enterprise SaaS
の管理
Qlik Cloud Government を管理
Windows 上の
Qlik Sense
Enterprise
の管理
オンボーディング データ統合ユーザー
Qlik Talend Data Integration Cloud を開始する
Talend Cloud を開始する
ビデオ
移行センター
評価ガイド
プレイブック
管理者プレイブック
Qlik Sense 管理者プレイブック
Qlik リソース
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
検索
SearchUnify の検索をロード中
製品に関するサポートが必要な場合は、Qlik Support にお問い合わせください。
Qlik Customer Portal
メニュー
閉じる
SearchUnify の検索をロード中
製品に関するサポートが必要な場合は、Qlik Support にお問い合わせください。
Qlik Customer Portal
こちらにフィードバックをお寄せください
ジョブ用のTalendコンポーネント
Data Qualityのコンポーネント
standardization
Standardizationのシナリオ
ベーシックタイプのルールを使ってデータを正規化する
準拠データと非準拠データを分離する
行を正規化するプロセスを設定する
このページ上
手順
手順
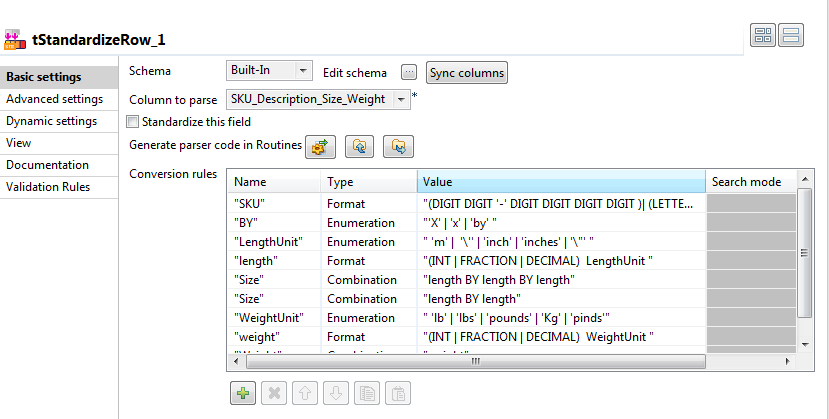
tStandardizeRow
をダブルクリックして、
[Component] (コンポーネント)
ビューを開きます。
[Column to parse] (解析するカラム)
フィールドで、
SKU_Description_Size_Weight
を選択します。これは、受信スキーマに含まれる唯一のカラムです。
[Conversion rules] (変換ルール)
テーブルで、[+]ボタンを8回クリックして、このテーブルに8行を追加します。
これらの行を完成させるには、このシナリオの最初に生データを分析する時に確認したルールを入力します。
2つの
Size
ルールは上から順に実行されます。この例では、この順序により、このコンポーネントは、最初に3つの数値を持つサイズに一致し、次に2つの数値を持つサイズに一致します。この順序を逆にすると、このコンポーネントは、すべてのサイズの最初の2つの数値を最初に一致させ、次に3つの数値のサイズの最後の数を不一致として扱います。
[Generate parser code in routines] (ルーチンでのパーサーコードの生成)
ボタンをクリックします。
[Advanced settings] (詳細設定)
ビューで、
[Output format] (出力形式)
エリアでデフォルトで選択されているオプションをそのまま使います。
[Max edits for fuzzy match] (ファジーマッチの最大編集)
は、デフォルトで
1
に設定されています。
このページは役に立ちましたか?
このページまたはコンテンツにタイポ、ステップの省略、技術的エラーなどの問題が見つかった場合はお知らせください。
こちらにフィードバックをお寄せください
前のトピック
コンポーネントをドロップしてリンク
次のトピック
正規化ジョブを実行する