メイン コンテンツをスキップする
補完的コンテンツへスキップ
Qlik.com
Community
Learning
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
閉じる
ドキュメント
Qlik Talend ドキュメンテーション
リリース ノート
インストールとアップグレード
データ統合
管理と実行
データ品質とガバナンス
アプリケーションと API 統合
追加のリソース
API ドキュメンテーション ポータル
セキュリティ ポータル
Talend アーカイブ
Qlik ヘルプ
Getting Started
Getting started with Talend cloud
Talend Cloud
Talend Cloud API Designer
Talend Cloud Data Inventory
Talend Cloud Data Preparation
Talend Cloud Data Stewardship
Talend Cloud Pipeline Designer
Talend Cloud API Services Platform
Getting started with Talend on premises
Talend Data Fabric
Talend Data Preparation
Talend Data Stewardship
Qlik ヘルプに移動
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
検索
ヘルプを検索
メニュー
閉じる
ヘルプを検索
こちらにフィードバックをお寄せください
Talend Components
Amazon S3
Amazon S3のシナリオ
AWSのDatabricksでS3に対してデータの書き込みと読み取りを実行
Sparkで使うS3サービスに接続を設定
このページ上
手順
手順
tS3Configuration
をダブルクリックして
[Component] (コンポーネント)
ビューを開きます。
Sparkはこのコンポーネントを使って、ジョブが実際のビジネスデータを書き込むS3システムに接続します。Databricks on AWSをサポートする
tS3Configuration
もその他の設定コンポーネントも配置していない場合、このビジネスデータはDatabricksファイルシステム(DBFS)で書かれます。
例
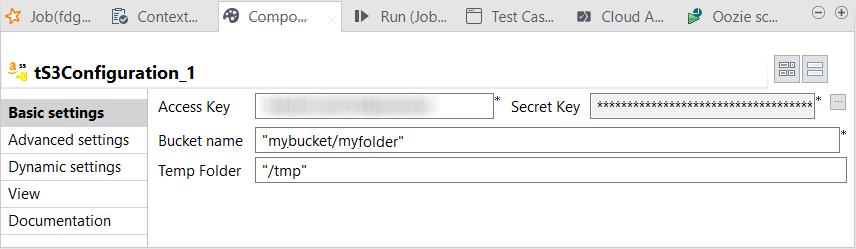
[Access key] (アクセスキー)
と
[Secret key] (シークレットキー)
フィールドに、S3への認証に使うキーを入力します。
[Bucket name] (バケット名)
フィールドに、ビジネスデータの保管に使うバケットとこのバケット内のフォルダーの名前を入力します(例:
mybucket/myfolder
)。このフォルダーが存在しない場合はオンザフライで作成されますが、バケットがランタイムで既に存在している必要があります。
このページは役に立ちましたか?
このページまたはコンテンツにタイポ、ステップの省略、技術的エラーなどの問題が見つかった場合はお知らせください。
こちらにフィードバックをお寄せください
前のトピック
Sparkジョブ用にAWSでのDatabricks接続パラメーターを定義
次のトピック
サンプルデータをS3に書き込む