
Finaliser et exécuter l'analyse d'un ensemble de colonnes
Avant d'exécuter l'analyse de cet ensemble de colonne, il vous reste à définir les indicateurs, le filtre sur les données et les paramètres d'analyse.
Avant de commencer
Procédure
-
Dans la zone Analysis Parameters :
- Dans le champ Number of connections per analysis, configurez le nombre de connexions concourantes autorisées par analyse pour la base de données sélectionnée.
Vous pouvez configurer ce nombre selon les ressources disponibles de la base de données, c'est-à-dire le nombre de connexions concourantes que chaque base de données peut supporter.
- Dans la liste Execution engine, sélectionnez le moteur, Java ou SQL, à utiliser pour exécuter l'analyse.
- Si vous sélectionnez le moteur Java, la case Store data est cochée par défaut et ne peut être décochée. Une fois l'analyse exécutée, les résultats du profiling sont disponibles localement. Vous pouvez les explorer via la vue .
Exécuter l'analyse avec le moteur Java utilise de l'espace disque car toutes les données sont récupérées et stockées localement. Si vous souhaitez libérer de l'espace, vous pouvez supprimer les données stockées dans le répertoire Studio Talend suivant du Studio : Talend-Studio>workspace>project_name>Work_MapDB.
- Si vous sélectionnez le moteur SQL, vous pouvez utiliser la case Store data pour décider de stocker localement les données analysées et y accéder via la vue .Note InformationsRemarque : Si les données en cours d'analyse sont très volumineuses, il est recommandé de ne pas cocher la case Store data pour ne pas stocker les résultats à la fin des calculs de l'analyse.
- Si vous sélectionnez le moteur Java, la case Store data est cochée par défaut et ne peut être décochée. Une fois l'analyse exécutée, les résultats du profiling sont disponibles localement. Vous pouvez les explorer via la vue .
- Dans le champ Number of connections per analysis, configurez le nombre de connexions concourantes autorisées par analyse pour la base de données sélectionnée.
-
Sauvegardez l'analyse et appuyez sur F6 pour l'exécuter.
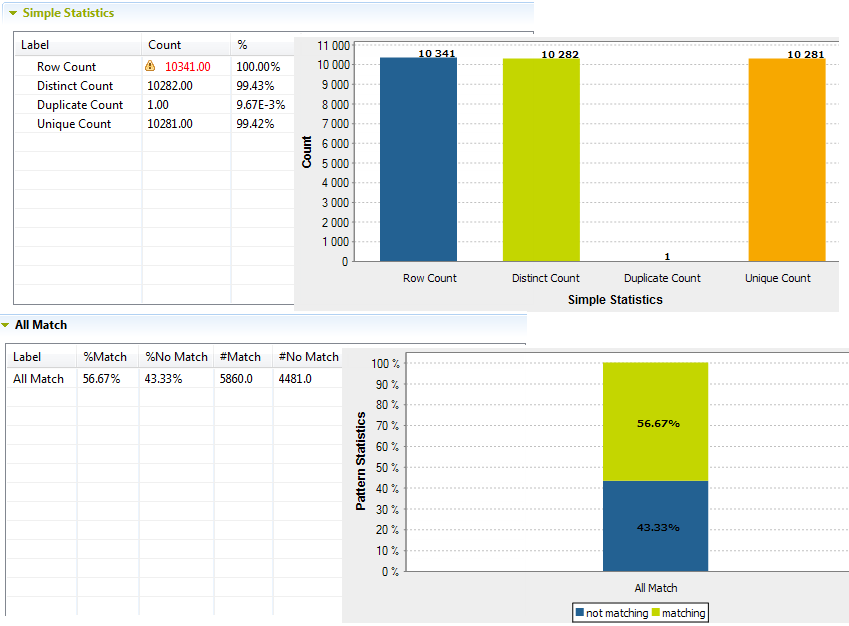
L'éditeur d'analyse passe à la vue Analysis Results dans laquelle vous pouvez lire les résultats d'analyse dans des tables et des diagrammes. Les résultats graphiques fournissent les statistiques simples sur les enregistrements complets de l'ensemble de colonnes analysées et non sur les valeurs au sein de chaque colonne séparément.
Lorsque vous utilisez des modèles afin de rapprocher le contenu de l'ensemble de colonnes, un autre diagramme est affiché pour illustrer les résultats qui correspondent et qui ne correspondent pas par rapport à la totalité des modèles utilisés.