
The LOAD statement loads fields from a file, from data defined in the script, from a previously loaded table, from a web page, from the result of a subsequent SELECT statement or by generating data automatically. It is also possible to load data from analytic connections.
Syntax:
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]|
inline data [ format-spec ] |
resident table-label |
autogenerate size ) |extension pluginname.functionname([script] tabledescription)]
[ where criterion | while criterion ]
[order by orderbyfieldlist ]
| Argument | Description |
|---|---|
| distinct |
You can use distinct as a predicate if you only want to load unique records. If there are duplicate records, the first instance will be loaded. If you are using preceding loads, you need to place distinct in the first load statement, as distinct only affects the destination table. |
| fieldlist |
fieldlist ::= ( * | field{, * | field } )
A list of the fields to be loaded. Using * as a field list indicates all fields in the table. field ::= ( fieldref | expression ) [as aliasname ]The field definition must always contain a literal, a reference to an existing field, or an expression. fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname is a text that is identical to a field name in the table. Note that the field name must be enclosed by straight double quotation marks or square brackets if it contains e.g. spaces. Sometimes field names are not explicitly available. Then a different notation is used: @fieldnumber represents the field number in a delimited table file. It must be a positive integer preceded by "@". The numbering is always made from 1 and up to the number of fields. @startpos:endpos represents the start and end positions of a field in a file with fixed length records. The positions must both be positive integers. The two numbers must be preceded by "@" and separated by a colon. The numbering is always made from 1 and up to the number of positions. In the last field, n is used as end position.
expression can be a numeric function or a string function based on one or several other fields in the same table. For further information, see the syntax of expressions. |
| from |
from is used if data should be loaded from a file using a folder. When loading from a file in space in Qlik Cloud Analytics, a valid path must be used. See Rules for valid space folder paths. file ::= [ path ] filename In Qlik Cloud Analytics, hierarchical folder structures are supported and can be referenced in the statement. Examples:
For more information and examples, see Loading files from spaces in Qlik Cloud Analytics. |
| from_field | from_field
is used if data should be loaded from a previously loaded field. fieldassource::=(tablename, fieldname) The field is the name of the previously loaded tablename and fieldname. format-spec ::= ( fspec-item {, fspec-item } )The format specification consists of a list of several format specification items, within brackets. For more information, see Format specification items. Information notefrom_field only supports commas as the list delimiter in when separating fields in tables. |
| inline | inline is used if data should
be typed within the script, and not loaded from a file. data ::= [ text ] Data entered through an inline clause must be enclosed by specific characters – square brackets, quotation marks, or back ticks. The text between these is interpreted in the same way as the content of a file. Hence, where you would insert a new line in a text file, you should also do it in the text of an inline clause: by pressing the Enter key when typing the script. In a simple inline load, the number of columns are defined by the first line. format-spec ::= ( fspec-item {, fspec-item } )You can customize the inline load with many of the same format specification items that are available for other loaded tables. These items are listed in brackets. For more information, see Format specification items. For more information about inline loads, see Using inline loads to load data. |
| resident | resident is used if data
should be loaded from a previously loaded table. table label is a label preceding the LOAD or SELECT statement(s) that created the original table. The label should be given with a colon at the end. |
| autogenerate | autogenerate is used
if data should be automatically generated by Qlik Sense. size ::= number Number is an integer indicating the number of records to be generated. The field list must not contain expressions which require data from an external data source or a previously loaded table, unless you refer to a single field value in a previously loaded table with the Peek function. |
| where | where is a clause used for
stating whether a record should be included in the selection or not. The
selection is included if criterion
is True. criterion is a logical expression. |
| while |
while is a clause used for stating whether a record should be repeatedly read. The same record is read as long as criterion is True. In order to be useful, a while clause must typically include the IterNo( ) function. criterion is a logical expression. |
| group by |
group by is a clause used for defining over which fields the data should be aggregated (grouped). The aggregation fields should be included in some way in the expressions loaded. No other fields than the aggregation fields may be used outside aggregation functions in the loaded expressions. groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order by | order by
is a clause used for sorting the records of a resident table before
they are processed by the load statement. The
resident table can be sorted by one or more fields in ascending or descending
order. The sorting is made primarily by numeric value and secondarily
by national collation order. This clause may only be used when the data source
is a resident table. The ordering fields specify which field the resident table is sorted by. The field can be specified by its name or by its number in the resident table (the first field is number 1). orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder is either asc for ascending or desc for descending. If no sortorder is specified, asc is assumed. fieldname, path, filename and aliasname are text strings representing what the respective names imply. Any field in the source table can be used as fieldname. However, fields created through the as clause (aliasname) are out of scope and cannot be used inside the same load statement. |
If no source of data is given by means of a from, inline, resident, from_field, extension or autogenerate clause, data will be loaded from the result of the immediately succeeding SELECT or LOAD statement. The succeeding statement should not have a prefix.
Loading data from a previously loaded table
Examples:
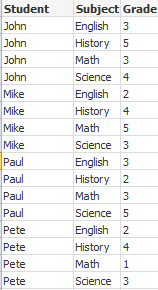
In this example we have a input file Grades.csv containing the grades for each student condensed in one field:
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
The grades, in a 1-5 scale, represent subjects Math, English, Science and History. We can separate the grades into separate values by reading each record several times with a while clause, using the IterNo( ) function as a counter. In each read, the grade is extracted with the Mid function and stored in Grade, and the subject is selected using the pick function and stored in Subject. The final while clause contains the test to check if all grades have been read (four per student in this case), which means next student record should be read.
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from [lib://DataFiles/Grades.csv]
while IsNum(mid(Grades,IterNo(),1));
The result is a table containing this data:
Loading files from spaces in Qlik Cloud Analytics
In Qlik Cloud Analytics, when loading data from a data file within a load script, you can use a LOAD statement or insert QVS code. In both cases, hierarchical space folder structures can be referenced in your script statement. Follow the rules for valid space folder paths. Additionally, the file and all referenced folders need to already exist in the specified location. Otherwise, the reload fails.
Examples: Reference to file at the top-level path of a space
This example loads the file orders.csv from a personal space. The file is not located within any specific folder, but instead is located at the top-level path in the space.
LOAD * FROM [lib://DataFiles/orders.csv];This example loads the file orders.csv from a shared, managed, or data space. The name of the space is TeamSharedSpace. The file is not located within any specific folder, but instead is located at the top-level path in the space.
LOAD * FROM [lib://TeamSharedSpace:DataFiles/orders.csv];Examples: References to specific folder path within a space
This example loads the file orders_Europe.csv from the folder Orders By Region within a personal space.
LOAD * FROM [lib://DataFiles/Orders By Region/orders_Europe.csv];This example loads the file orders_Europe.csv from the folder Orders By Region within a shared, managed, or data space. The name of the space is SalesSpace.
LOAD * FROM [lib://SalesSpace:DataFiles/Orders By Region/orders_Europe.csv];For more information about referencing space folder structure in load scripts, see Referencing space folder structure in application and script development.