
Hubspot
The Hubspot connector allows you to build integrations between Hubspot and 500+ other cloud applications usingQlik Application Automation for OEM. You can read data from Hubspot and write to Hubspot.
Example use cases
- Push company, lead and contact information from various sources into Hubspot.
- VoIP integrations between your cloud telephony platform and Hubpsot, e.g. sync call information to Hubspot as activities. More info
- Extract data from Hubspot for dashboarding, analytics, and applying AI to gain new insights.
Getting started
See the Qlik Application Automation for OEM Getting Started articles for a general introduction toQlik Application Automation for OEM
After logging in, click the New automation
button to start building a workflow (automation). In the automation editor, find and click Hubspot in the left pane, and select one of the building blocks, for example, List contacts
.
The Hubspot List Contacts block.
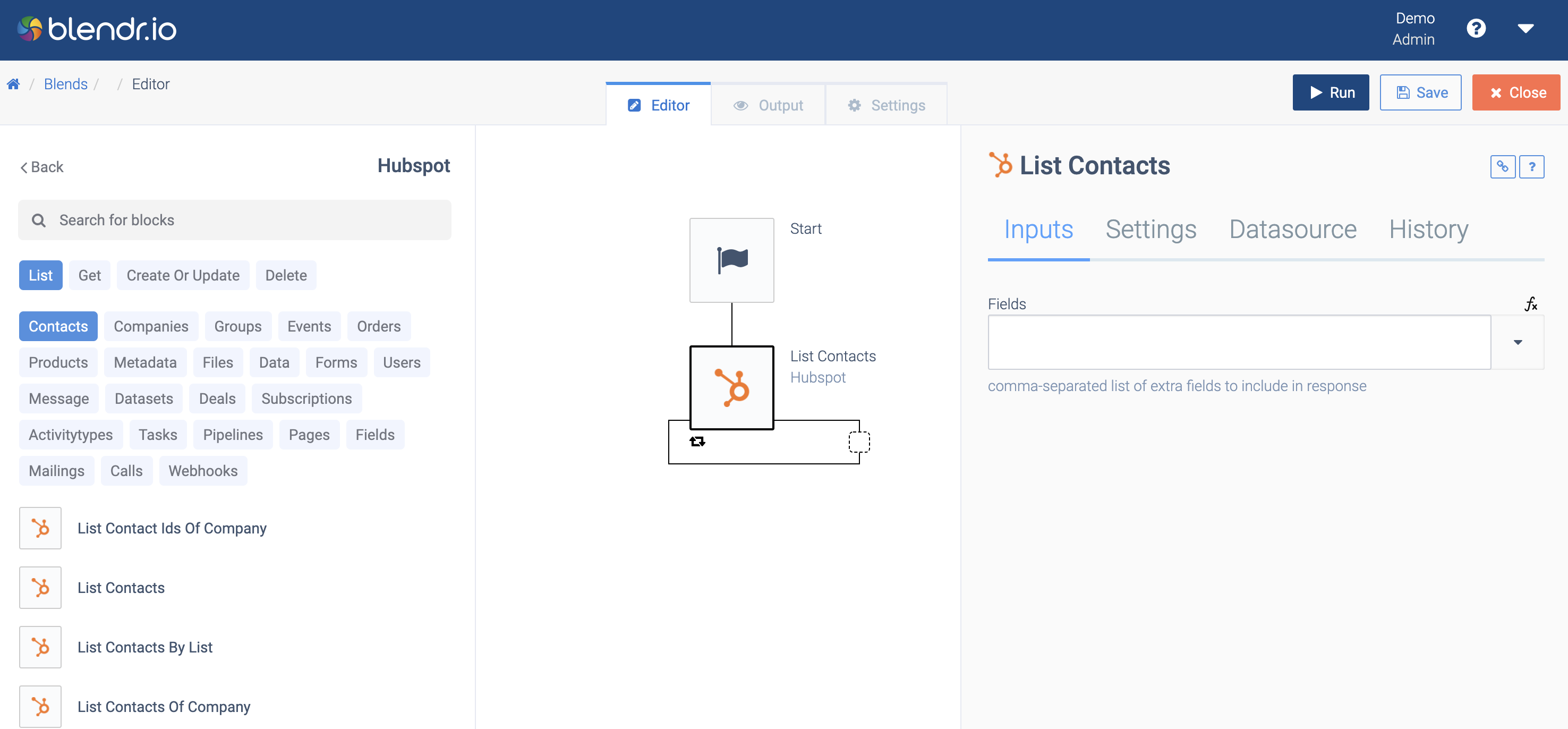
You will have to connect your own Hubspot instance using oAuth. Follow the wizard and authorize access for Qlik Application Automation for OEM to your account.
Next, add a block to send the data to a destination, for example Google Sheet. Add the block inside the loop of the List contacts
block.
A block inside a List Contacts block's loop.
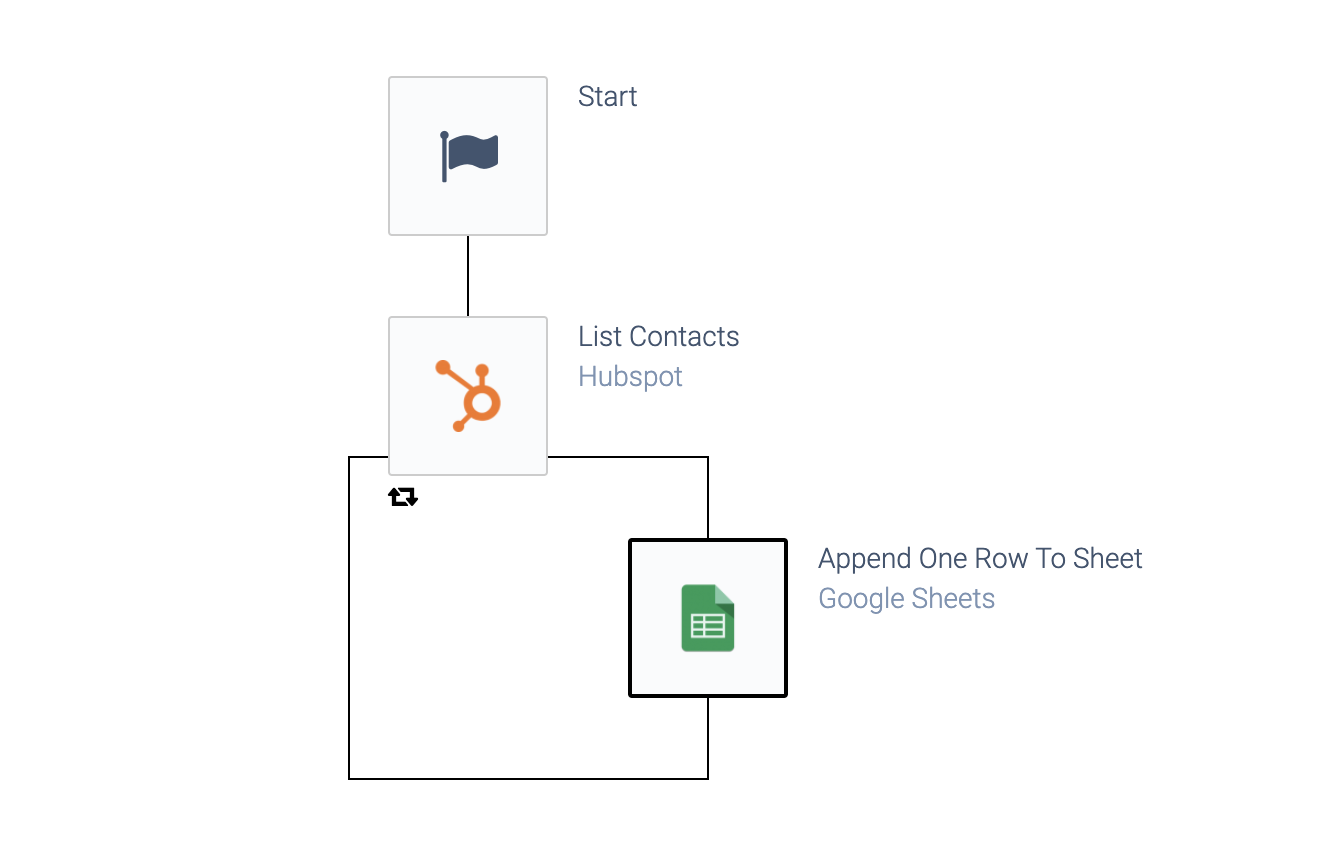
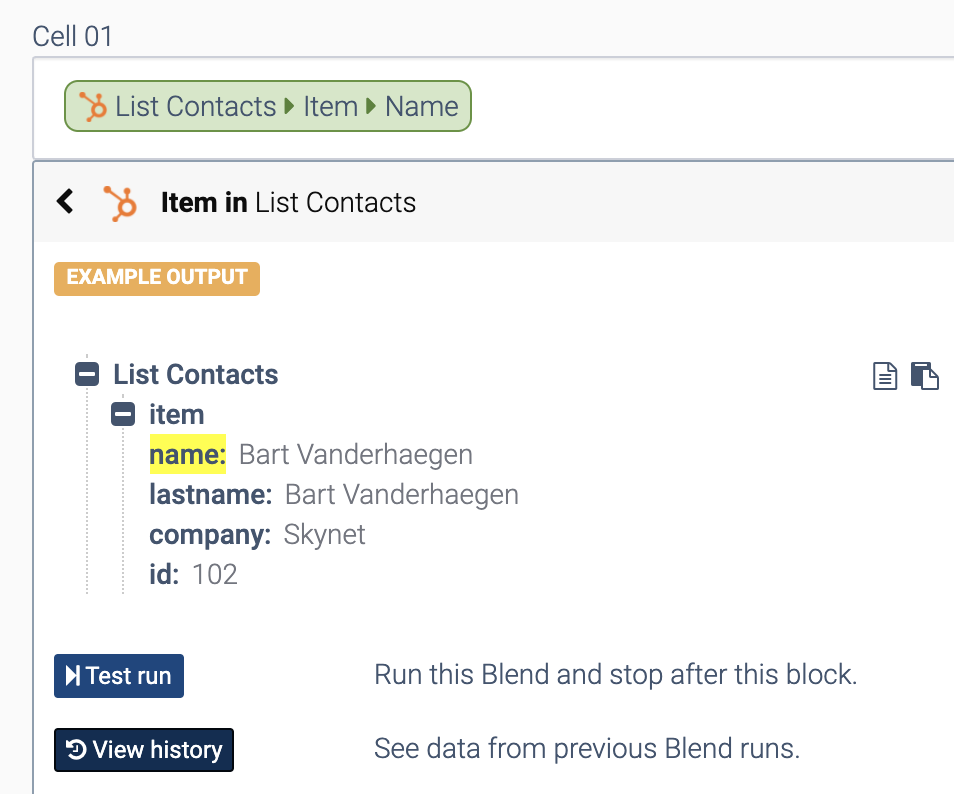
Finally, configure field mapping in the pane on the right hand side, for the various input fields of the Google block. Click in an input field, and use the lookup dropdown to select the desired field from Hubspot.
The lookup dropdown.
Repeat this for multiple fields. The result is that you have multiple field mappings from Hubspot to Google Sheet.
Appending multiple cells per row.
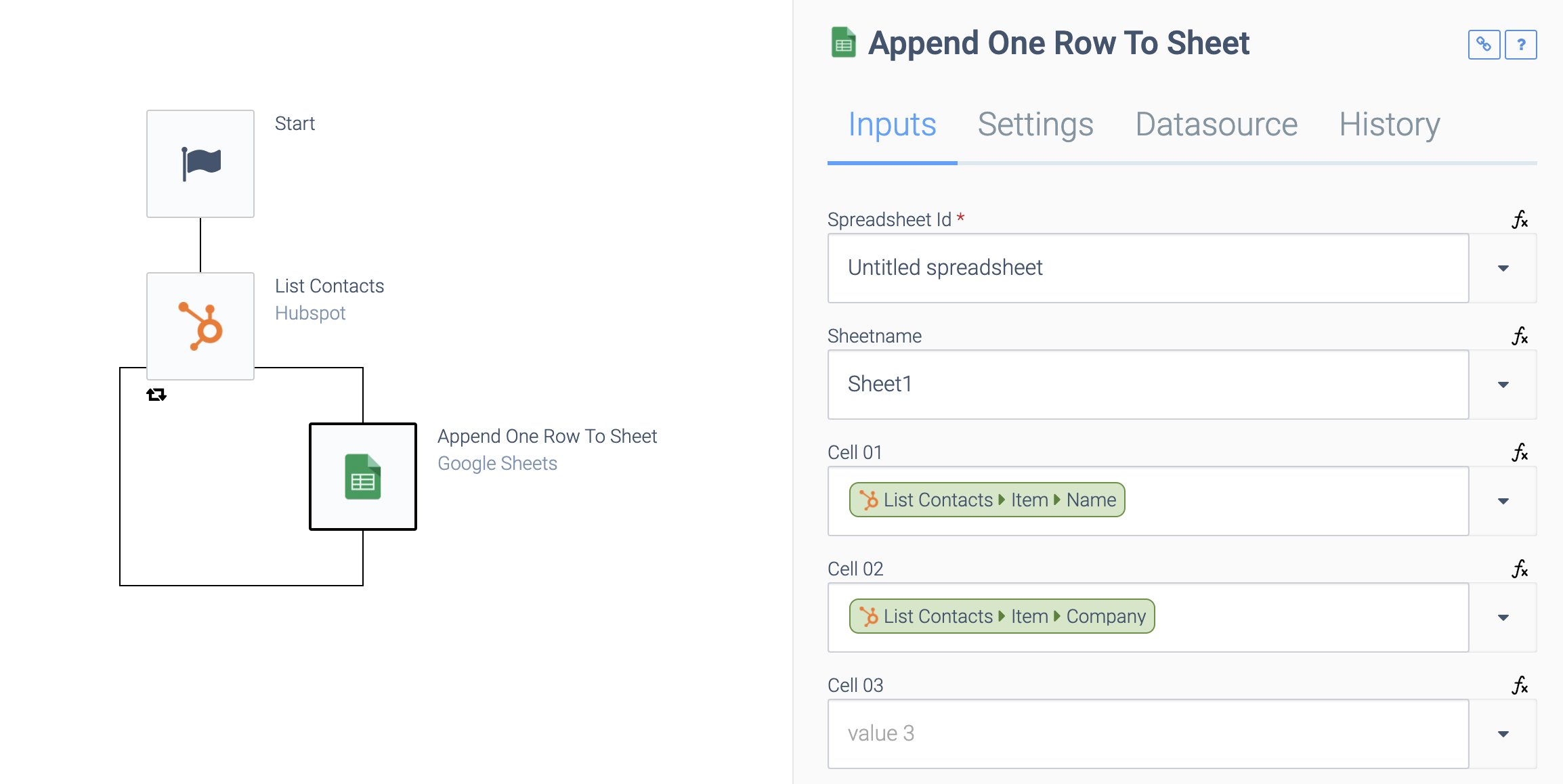
You can now run your automation using the Run
button in the top right corner. Your contacts will now be added to your Google Sheet as new rows.
List new and updated (+10k records)
The Hubspot API doesn't support incremental calls where more than 10k records are returned. This can be a problem when building integrations that sync contacts from Hubspot to another platform. In a contact-sync, this issue can be avoided by doing a full-sync with a List Contacts
endpoint on the first run of the integration. A variable in the Data Store will hold if this full-sync was executed or not. Then a condition block will check that variable, if the full-sync has happened, it will execute the incremental endpoint. If the full-sync hasn't happened, it will execute the full-sync and ignore the incremental endpoint. After the full-sync, the variable's value is changed to indicate that the full-sync happened. The following image illustrates such an approach.
Two automations that perform a full-sync.
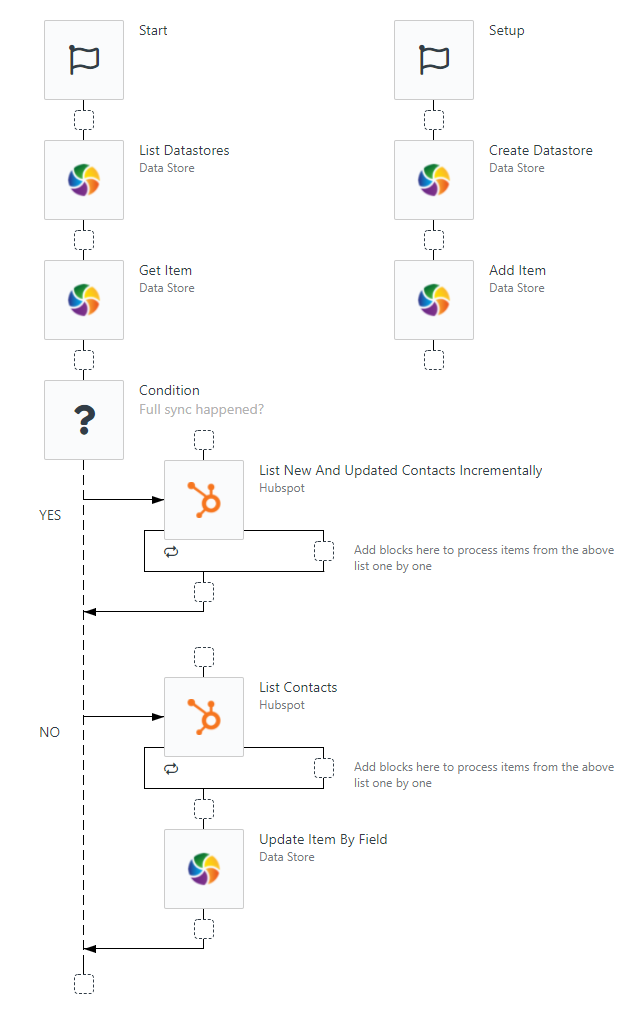
The above example uses the setup flow to create the variable in the datastore please note that the setup flow is only available in templates. An approach without the setup flow would first check if the variable exists in the Data Store and create it if it doesn't.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!