出力コンポーネントの設定およびジョブの実行
手順
-
tFileOutputExcelコンポーネントをダブルクリックして、[Basic settings] (基本設定)ビューを表示し、コンポーネントのプロパティを定義します。
-
出力コンポーネントを右クリックし、[Data Viewer] (データビューアー)を選択して、翻字データを表示します。
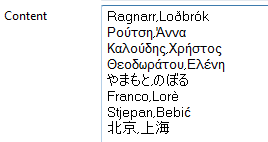
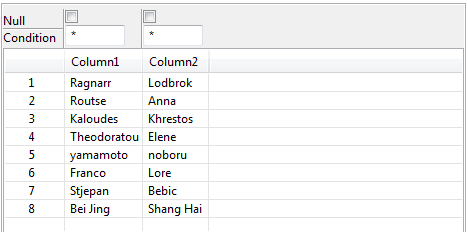 さまざまな言語の文字で書かれた名前はすべてUCS (Universal Coded Character Set)に基づく標準文字セットに音訳されています。たとえば、下の画像の最初と2番目の行の名前は、それぞれRagnarr,LodbrokおよびRoutse,Annaに変更されています。
さまざまな言語の文字で書かれた名前はすべてUCS (Universal Coded Character Set)に基づく標準文字セットに音訳されています。たとえば、下の画像の最初と2番目の行の名前は、それぞれRagnarr,LodbrokおよびRoutse,Annaに変更されています。