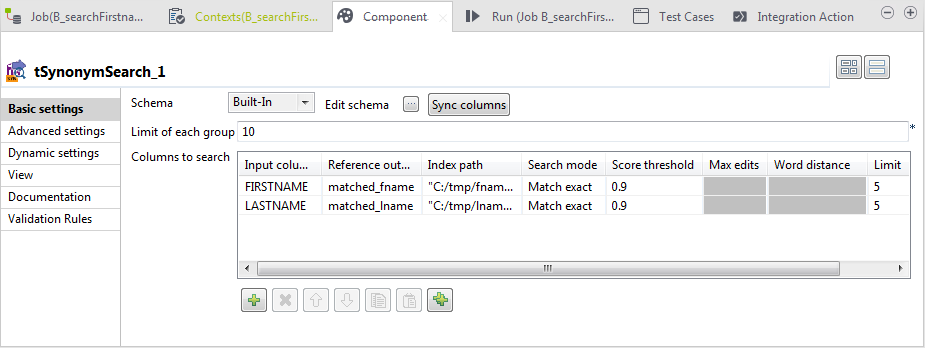
コンポーネントを設定
手順
-
tFixedFlowInputをダブルクリックして、[Basic settings] (基本設定)ビューを開きます。
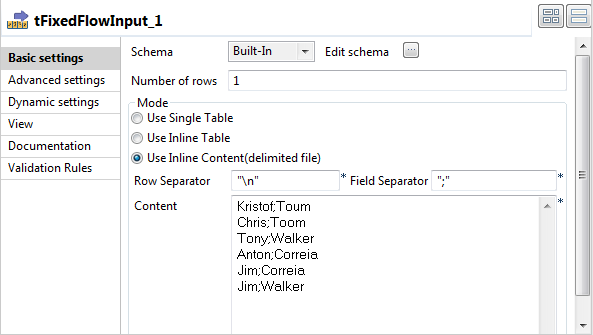
-
[Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックして[Schema] (スキーマ)ダイアログボックスを開き、前のシナリオで定義したFIRSTNAMEカラムの横に2番目のカラムLASTNAMEを追加します。
次に[OK]をクリックしてこの変更を確定し、ダイアログボックスを閉じます。
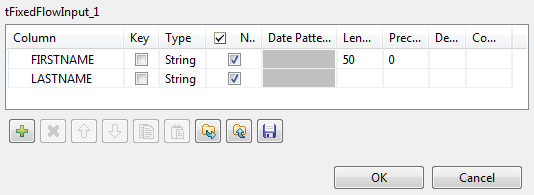
-
tSynonymSearchをダブルクリックして[Basic settings] (基本設定)ビューを開きます。