
非ストラクチャー化データを標準化するプロセスを設定する
このタスクについて
これを行うには、次の手順に従います。
手順
-
tStandardizeRowコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを表示します。
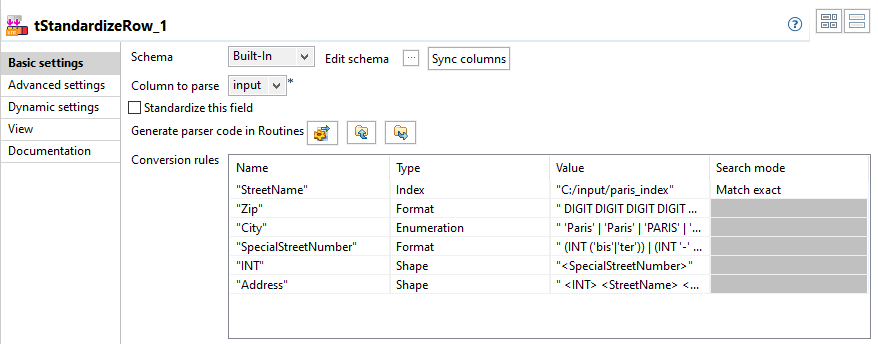 詳細なルールタイプは、ルールの順序に関係なく、常にANTLR固有のルールの後に実行されます。
詳細なルールタイプは、ルールの順序に関係なく、常にANTLR固有のルールの後に実行されます。 -
tStandardizeRowコンポーネントにリンクされているtLogRowコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを表示します。
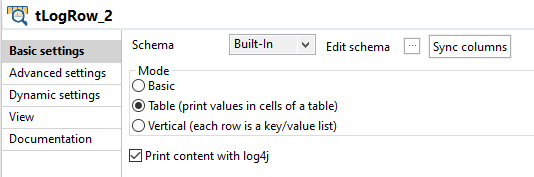
タスクの結果
次に、目的とするデータをフィルタリングおよび抽出するプロセスの設定を続けます。