
Modifier les règles et afficher les résultats d'exemple
Procédure
-
Cliquez sur
 dans le coin supérieur droit de la zone Matching Key ou Match and Survivor et remplacez le nom par défaut de la règle par le nom de votre choix.
dans le coin supérieur droit de la zone Matching Key ou Match and Survivor et remplacez le nom par défaut de la règle par le nom de votre choix.
 Si vous définissez plus d'une règle dans l'analyse de rapprochement, vous pouvez utiliser les flèches dans la boîte de dialogue afin de modifier l'ordre des règles et décider de la règle à exécuter en premier.
Si vous définissez plus d'une règle dans l'analyse de rapprochement, vous pouvez utiliser les flèches dans la boîte de dialogue afin de modifier l'ordre des règles et décider de la règle à exécuter en premier. -
Cliquez sur Chart afin de calculer les groupes selon la clé de bloc et la règle de rapprochement définies dans l'éditeur et pour afficher les résultats des données d'exemple dans un graphique.
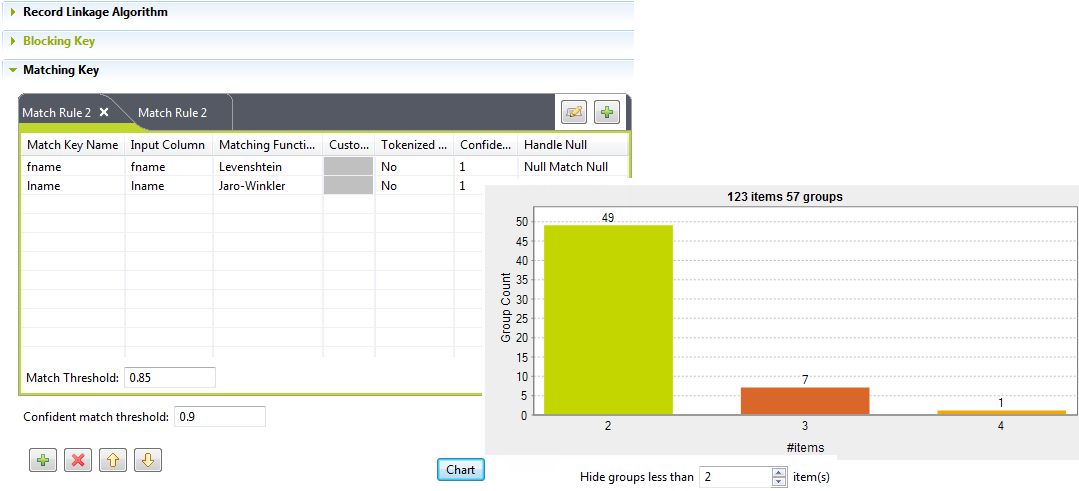 Ce graphique montre une image globale des doublons dans les données analysées. Le paramètre Hide groups less than est configuré à 2 par défaut. Ce paramètre vous permet de décider quel groupe afficher dans le graphique.Le graphique dans l'image ci-dessus indique que, sur les 1000 enregistrements d'exemple examinés et après exclusion des éléments uniques, avec un paramètre Hide groups less than configuré à 2 :
Ce graphique montre une image globale des doublons dans les données analysées. Le paramètre Hide groups less than est configuré à 2 par défaut. Ce paramètre vous permet de décider quel groupe afficher dans le graphique.Le graphique dans l'image ci-dessus indique que, sur les 1000 enregistrements d'exemple examinés et après exclusion des éléments uniques, avec un paramètre Hide groups less than configuré à 2 :-
quatre groupes ont deux éléments chacun. Dans chaque groupe, les deux éléments sont des doublons l'un de l'autre.
-
sept groupes ont trois éléments en doublon et le dernier groupe a quatre éléments en doublon.
La table Data indique les détails de la correspondance des éléments de chaque groupe et colorie les groupes selon leur couleur dans le graphique des correspondances. -