
Configurer une analyse de rapprochement
Procédure
-
Dans le champ Limit, définissez le nombre d'enregistrements de données à utiliser comme échantillon de données.
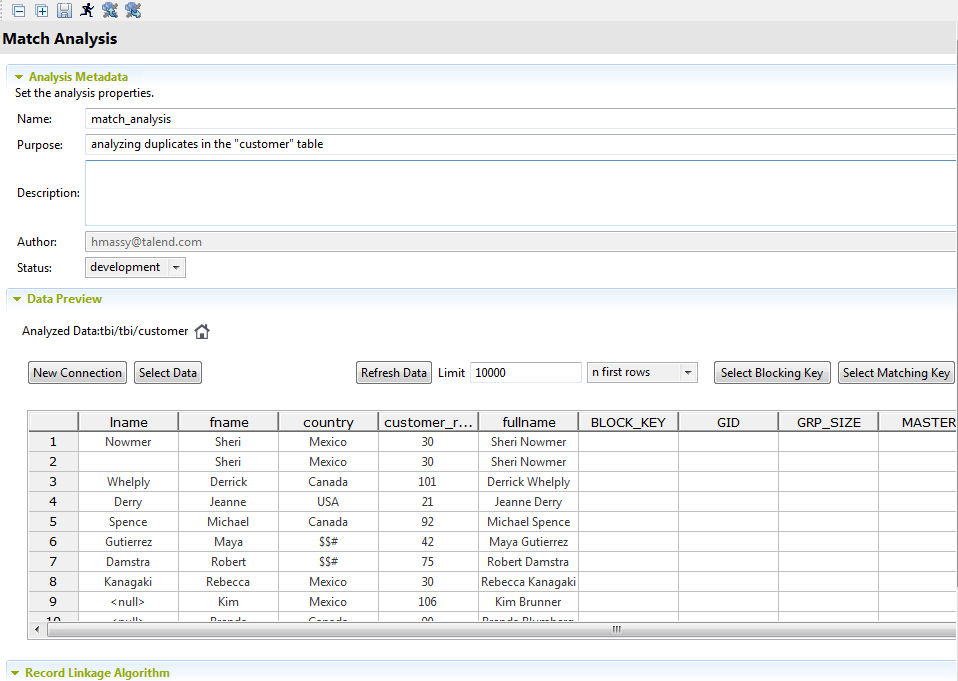
-
Dans l'éditeur d'analyse de rapprochement, sélectionnez :
Option
Pour...

sélectionner la table sous le nœud Metadata de l'arborescence.
New Connection
créer une connexion à une base de données ou à un fichier depuis l'éditeur d'analyse de rapprochement dans lequel vous pouvez développer cette nouvelle connexion et sélectionnez les colonnes sur lesquelles effectuer le rapprochement.
Pour plus d'informations concernant la création d'une connexion à des sources de données, consultez Créer des connexions aux différentes sources de données.
Select Data
mettre à jour la sélection des colonnes listées dans la table.
Si vous modifiez le jeu de données pour une analyse, les diagrammes affichant les résultats de rapprochement des données d'exemple sont automatiquement effacés. Vous devez cliquer sur Chart afin de calculer les résultats de rapprochement pour le nouveau jeu de données défini.
Refresh Data (Actualiser les données)
Actualiser la vue des colonnes listées dans la table. n first rows
ou
n random rows
lister dans la table les N premiers enregistrements des colonnes sélectionnées ou lister N enregistrements aléatoires des colonnes sélectionnées. Select Blocking Key
définir les colonnes du flux d'entrée selon lesquelles vous souhaitez partitionner les données traitées en blocs.
Pour plus d'informations, consultez Définir une règle de rapprochement.
Select Matching Key
définir les règles de rapprochement et les colonnes du flux d'entrée sur lesquelles vous souhaitez appliquer l'algorithme de rapprochement.
Pour plus d'informations, consultez Définir une règle de rapprochement.
Store on disk
stocker les blocs de données traités sur le disque afin d'optimiser les performances système.
Max buffer size : Saisissez la taille de la mémoire physique que vous souhaitez allouer aux données traitées.
Temporary data directory path : Configurez le chemin d'accès au répertoire où stocker le fichier temporaire.
Résultats
La table Data contient des colonnes supplémentaires affichant les résultats des données en correspondance. Les indications de ces colonnes sont les suivantes :
|
Colonne |
Description |
|
GID |
représente l'identifiant du groupe. |
|
GRP_SIZE |
compte le nombre d'enregistrements dans le groupe. Le calcul se fait uniquement sur l'enregistrement maître. |
|
MASTER |
indique, par true ou false, si l'enregistrement utilisé dans la comparaison est un enregistrement maître. Il y a au moins un enregistrement maître par groupe. Chaque enregistrement d'entrée est comparé à l'enregistrement maître. |
|
SCORE |
mesure la distance entre l'enregistrement d'entrée et l'enregistrement maître selon l'algorithme de rapprochement utilisé. |
|
GRP_QUALITY |
seul l'enregistrement maître possède un score de qualité représentant la valeur minimale du groupe. |
|
ATTRIBUTE_SCORE |
liste le score de rapprochement et le nom des colonnes utilisées comme attributs de clés dans les règles appliquées. |