
Nouvelles fonctionnalités
Intégration d'application
| Fonctionnalité | Description |
|---|---|
|
Nouveaux exemples IA ajoutés aux démos d'intégration d'applications |
Nouveaux exemples IA pour les Routes ajoutés aux démos d'intégration d'applications. |
|
Nouveau composant cTextTemplate pour les Routes |
Le nouveau composant cTextTemplate est à présent disponible dans les Routes. Il vous permet de traiter des mesages à l'aide de modèles. |
|
Amélioration du cRabbitMQ pour supporter l'option de déclaration automatique et les champs orientés contexte |
L'option Auto declare (Déclaration auto) est à présent disponible dans le composant cRabbitMQ. Elle vous permet de déclarer automatiquement une liaison entre l'échange, la file d'attente et la clé de routage. Vous pouvez à présent définir tous les paramètres du cRabbitMQ via des variables de contexte. 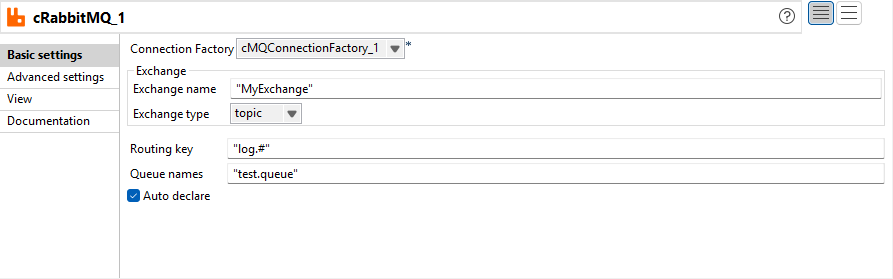 |
|
Amélioration du cSetHeader afin de supporter l'ordre de suppression des en-têtes configurables |
Vous pouvez à présent configurer l'ordre des suppressions et ajouts d'en-têtes dans le cSetHeader grâce aux nouvelles options Cleanup order (Ordre de nettoyage). 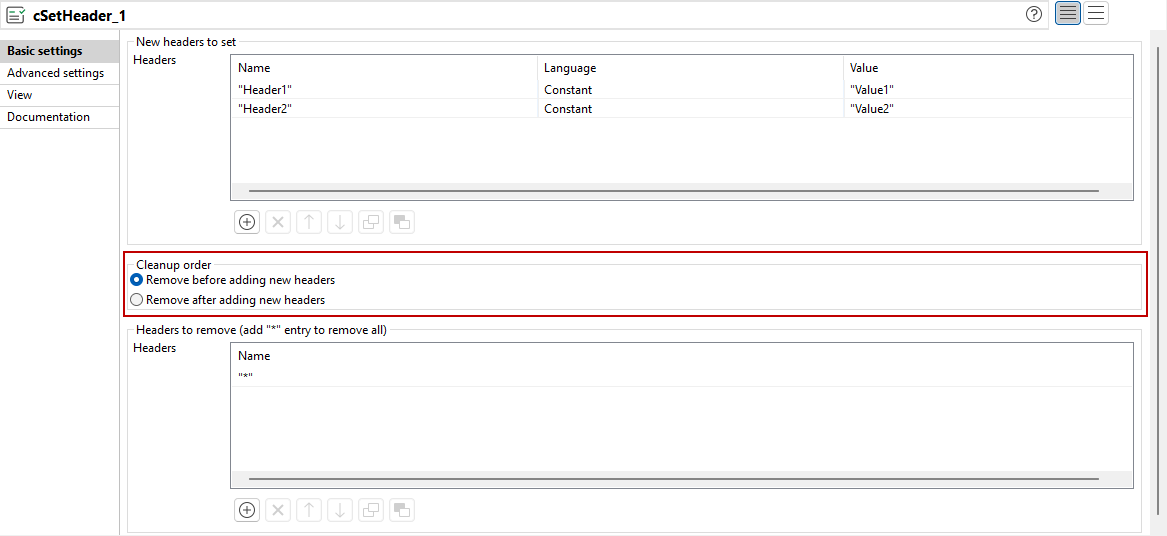 |
|
Amélioration du cMail pour IMAP/POP3 afin d'améliorer les filtres et le nettoyage de la configuration |
Les options de configuration pour les protocoles IMAP et POP3 dans le composant cMail ont été mises à jour :
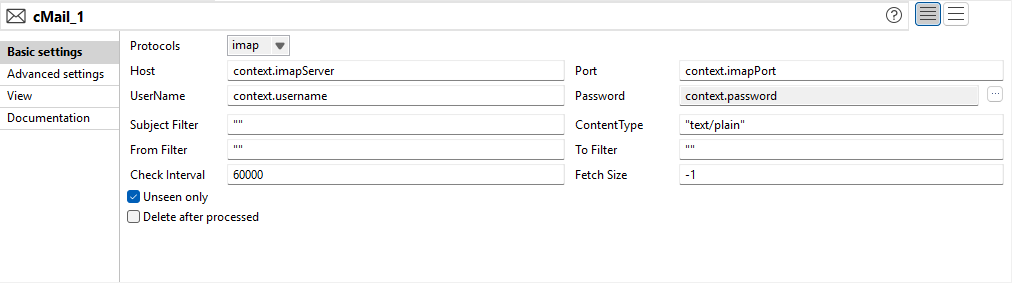 |
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de CDP Private Cloud Base 7.3.1 avec Spark Universal 3.x | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster CDP Private Cloud Base 7.3.1 avec la JDK 17, à l'aide de Spark Universal avec Spark 3.x en mode Yarn cluster (Cluster YARN). Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop).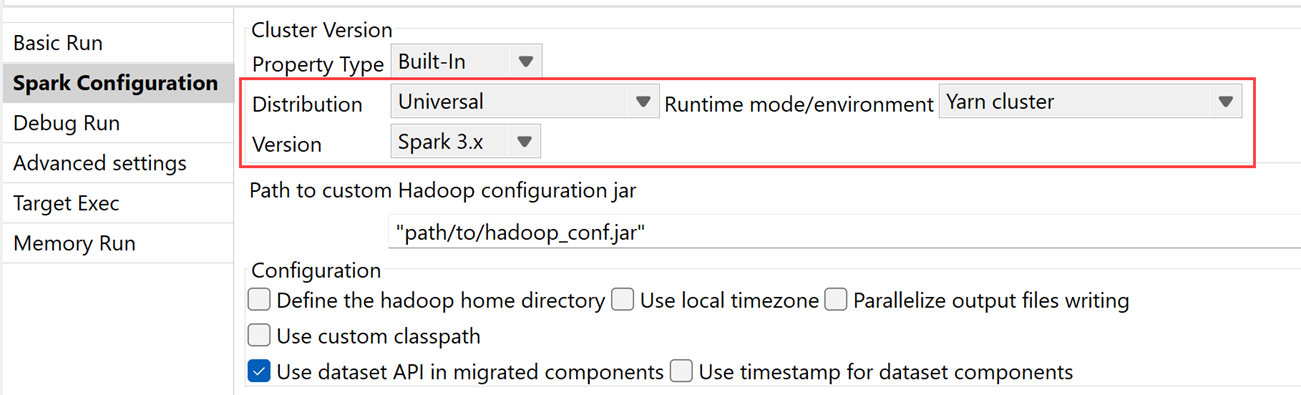 |
|
Support du mode runtime de Cloudera dans l'interface de Spark Universal |
Vous pouvez à présent utiliser le mode runtime de Cloudera pour vos Jobs Spark dans l'interface de Spark Universal, avec le support de Spark 3.x uniquement. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
|
Support de l'API Salesforce version 64 pour les composants Salesforce dans les Jobs Standards |
Les composants Salesforce ont été mis à jour pour supporter l'API en version 64, permettant la compatibilité avec les dernières améliorations et fonctionnalités Salesforce. |
|
Support de la base de données Azure pour MySQL - Flexible Server pour les composants MySQL dans les Jobs Standards |
Les composants MySQL ont été mis à jour pour supporter la base de données Azure pour MySQL - Flexible Server, développant ainsi la compatibilité Cloud et les options de déploiement. |
|
Nouvelle option pour convertir les valeurs numériques NULL à 0 pour le tSAPADSOInput dans les Jobs Standards |
La nouvelle option Convert NULL numeric values to zero (Convertir les valeurs numériques NULL en zéros) a été ajoutée au composant tSAPADSOInput pour permettre la conversion automatique des champs numériques NULL vers zéro au cours de l'extraction de données. |
|
Le jeton d'authentification est à présent envoyé dans l'en-tête pour conformité aux prérequis de l'API Marketo mis à jour dans les Jobs Standards |
Les composants Marketo ont été mis à jour pour envoyer le jeton d'authentification dans l'en-tête au lieu des paramètres de requête, assurant ainsi la conformité aux derniers prérequis de l'API Marketo. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Support de l'éditeur de maps DSQL comme éditeur de maps par défaut | L'éditeur de maps DSQL est à présent l'éditeur de maps par défaut dans Talend Data Mapper. Lorsque vous créez une nouvelle map ou utilisez des composants de mapping de données, l'option DSQL map (Map DSQL) est sélectionnée par défaut, mais vous pouvez sélectionner manuellement l'option Standard map (Map Standard). |
| Support des expressions paramétrées récursives dans les maps DSQL | Les expressions paramétrées supportent à présent la récursivité, ce qui signifie que vous pouvez appeler une expression paramétrée dans l'expression paramétrée même. |
| Support de la fonctionnalité d'exécution de test sur les éléments enroulés et déroulés dans les maps DSQL | Vous pouvez à présent utiliser l'option Test Run (Exécution de test) sur des éléments spécifiques déroulés et scindés dans les maps DSQL. |
| Possibilité de glisser-déposer les fonctions et de mapper les éléments dans des expressions paramétrées dans les maps DSQL | Vous pouvez à présent glisser-déposer une fonction et un élément de map d'entrée dans le contenu d'une expression paramétrée. |
| Possibilité de glisser-déposer les expressions paramétrées dans l'éditeur d'expressions dans les maps DSQL | Vous pouvez à présent glisser-déposer une expression paramétrée dans l'éditeur d'expressions de votre map DSQL. Le comportement est le même que lorsque vous glissez-déposez une fonction dans l'éditeur d'expressions.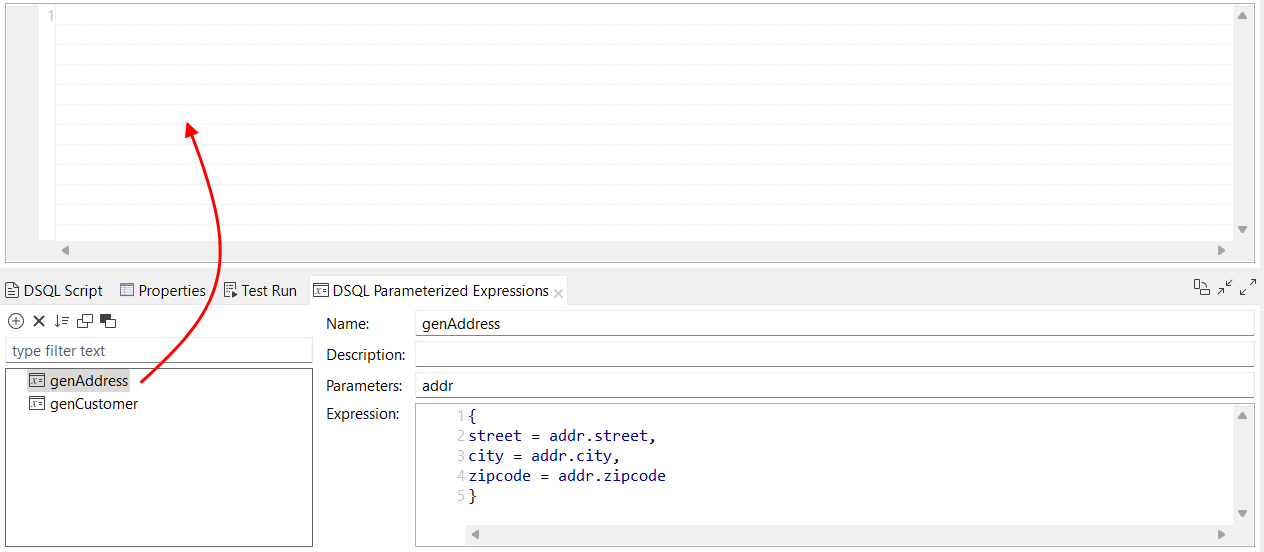 |
| Nouvelles options permettant de copier-coller des expressions paramétrées dans les maps DSQL | Vous avez à présent la possibilité de copier des expressions paramétrées et de les coller dans votre map DSQL courante ou dans une autre map DSQL. Les options Name (Nom), Description, Parameters (Paramètres) et Expression sont copiées. Si une expression paramétrée du même nom existe déjà dans la map de destination, la copie est automatiquement renommée avec un suffixe, par exemple genAddress_2. 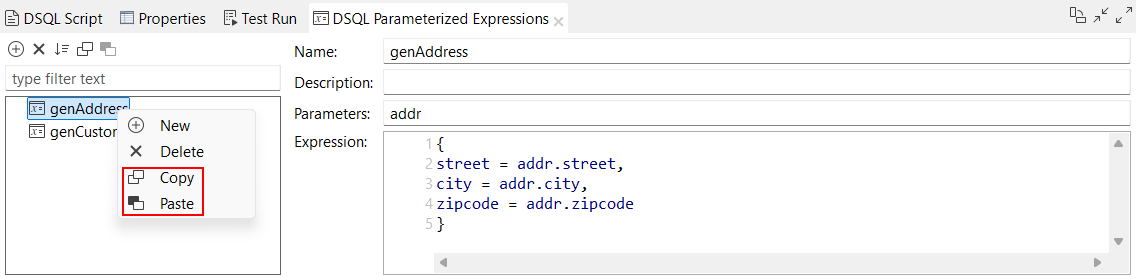 |
| Nouvelle option Create Parameterized Expression (Créer une expression paramétrée) disponible pour l'erreur Unknown function (Fonction inconnue) dans les maps DSQL | Lorsqu'une map DSQL contient un fragment avec une erreur Unknown function (Fonction inconnue), une option Create Parameterized Expression (Créer une expression paramétrée) est à présent disponible lorsque vous cliquez-droit sur l'erreur, vous permettant de créer une expression paramétrée avec le nom inconnu. 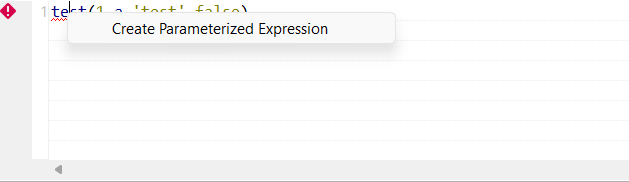 |