
Neue Funktionen
Anwendungsintegration
| Funktion | Beschreibung |
|---|---|
|
Neue KI-Beispiele wurden den Anwendungsintegrationsdemos hinzugefügt |
Neue KI-Beispiele für Routen wurden den Anwendungsintegrationsdemos hinzugefügt. |
|
Neue cTextTemplate-Komponente für Routen |
Die neue cTextTemplate-Komponente ist jetzt in Routen verfügbar, mit der sie Nachrichten mithilfe von Vorlagen verarbeiten können. |
|
Verbesserung von cRabbitMQ zur Unterstützung der Option zum automatischen Deklarieren und kontextfähiger Benutzeroberflächenfelder |
Die Option Auto declare (Automatisch deklarieren) ist jetzt in der cRabbitMQ-Komponente verfügbar. Mithilfe dieser Option können Sie die Bindung zwischen Austausch, Warteschlange und Routing-Schlüssel automatisch deklarieren. Sie können jetzt alle Parameter von cRabbitMQ mithilfe von Kontextvariablen definieren. 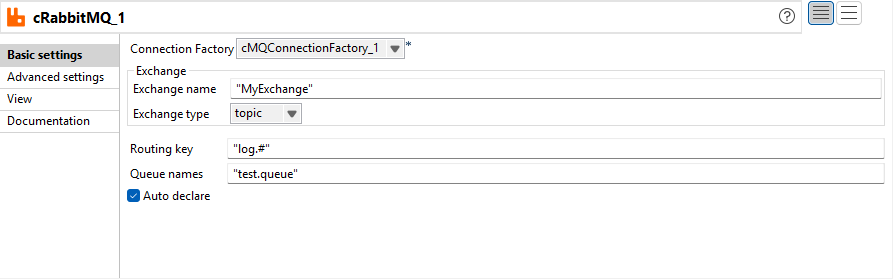 |
|
Verbesserung von cSetHeader zur Unterstützung der Reihenfolge zum Entfernen von Headern |
Die Reihenfolge zum Entfernen und Hinzufügen von Headern kann jetzt in cSetHeader mit der neuen Option vom Typ Cleanup order (Bereinigungsreihenfolge) konfiguriert werden. 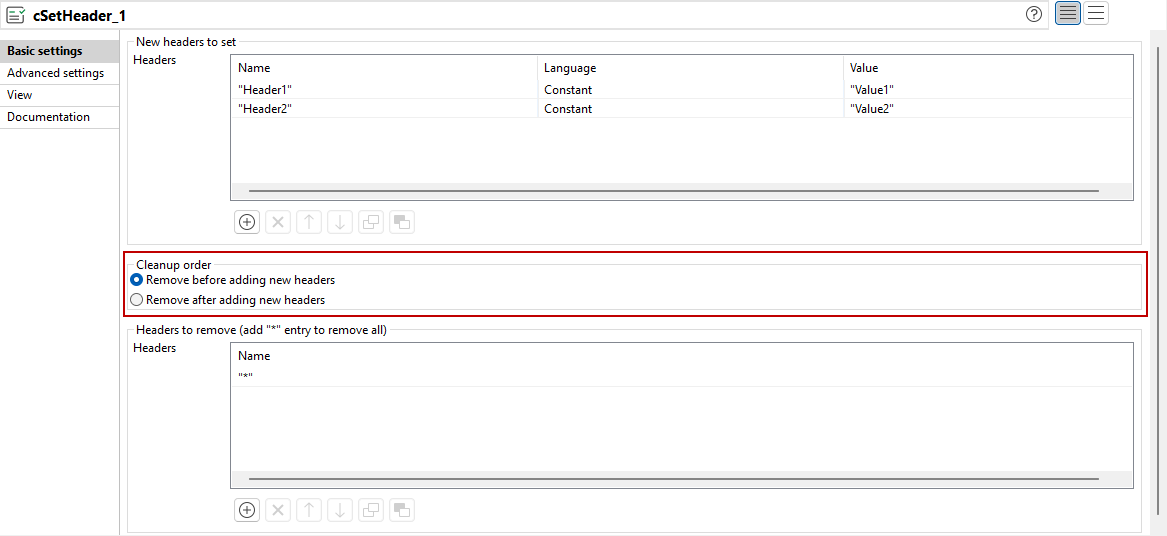 |
|
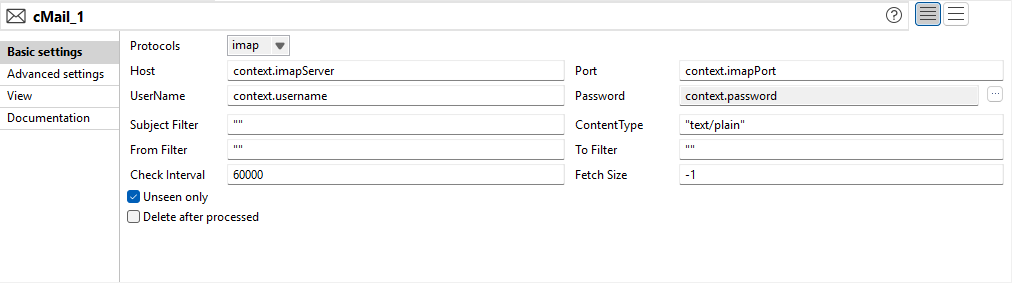
Verbesserung von cMail für IMAP/POP3 zur Verbesserung der Filterung und Konfigurationsbereinigung |
Die Konfigurationsoptionen für die Protokolle IMAP und POP3 in cMail werden aktualisiert:
 |
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für CDP Private Cloud Base 7.3.1 mit Spark Universal 3.x | Sie können Ihre Spark-Jobs jetzt in einem CDP Private Cloud Base 7.3.1-Cluster mit JDK 17 unter Verwendung von Spark Universal mit Spark 3.x im Yarn-Cluster-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung).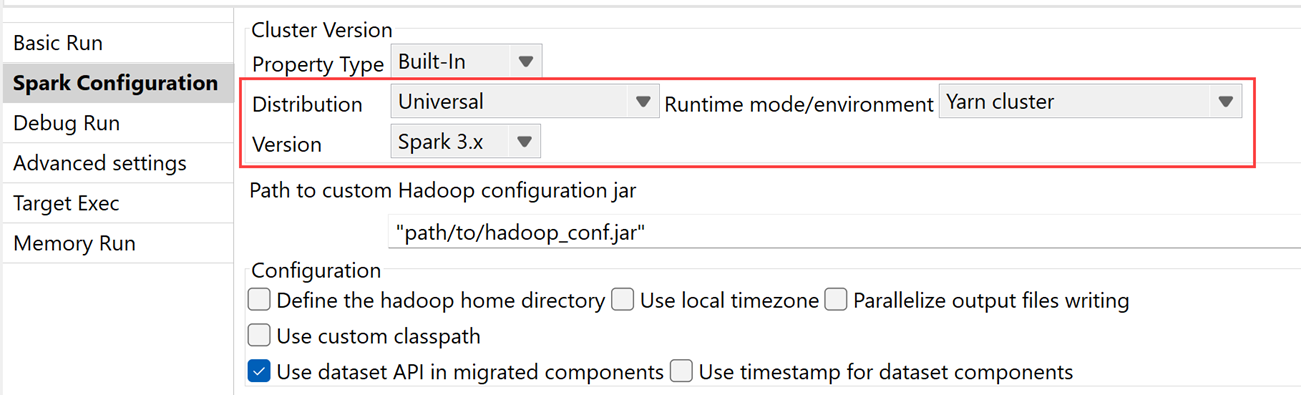 |
|
Unterstützung für den Cloudera-Laufzeitmodus auf der Spark Universal-Benutzeroberfläche |
Sie können den Cloudera-Laufzeitmodus für Ihre Spark-Jobs auf der Spark Universal-Benutzeroberfläche jetzt mit ausschließlicher Unterstützung für Spark 3.x verwenden. |
Datenintegration
| Funktion | Beschreibung |
|---|---|
|
Unterstützung für die Salesforce API-Version 64 für Salesforce-Komponenten in Standard-Jobs |
Die Salesforce-Komponenten wurden aktualisiert, um die API-Version 64 zu unterstützen und so die Kompatibilität mit den aktuellen Salesforce-Funktionen und -Erweiterungen sicherzustellen. |
|
Unterstützung für Azure Database for MySQL – Flexible Server für MySQL-Komponenten in Standard-Jobs |
Die MySQL-Komponenten wurden aktualisiert, um Azure Database for MySQL – Flexible Server zu unterstützen und so die Cloud-Kompatibilität sowie die Bereitstellungsoptionen zu erweitern. |
|
Neue Option zum Konvertieren von numerischen NULL-Werten in 0 für tSAPADSOInput in Standard-Jobs |
Die neue Option Convert NULL numeric values to zero (Numerische NULL-Werte in 0 konvertieren) wurde der tSAPADSOInput-Komponente hinzugefügt, um automatische Konvertierung von nummerischen NULL-Feldern in 0 während der Datenextraktion zu ermöglichen. |
|
Authentifizierungstoken werden jetzt im Header gesendet, um die aktualisierten Marketo-API-Anforderungen in Standard-Jobs zu erfüllen |
Die Marketo-Komponenten wurden aktualisiert, um das Authentifizierungstoken im Header statt in Abfrageparametern zu senden und somit die Einhaltung der aktuellen Marketo-API-Anforderungen sicherzustellen. |
Data Mapper
| Funktion | Beschreibung |
|---|---|
| Unterstützung für DSQL-Map-Editor als Standard-Map-Editor | Der DSQL-Map-Editor fungiert jetzt als Standard-Map-Editor in Talend Data Mapper. Wenn Sie eine neue Map erstellen oder mit Datenmapping-Komponenten arbeiten, wird die DSQL map (DSQL-Map) standardmäßig ausgewählt. Die Standard map (Standard-Map) kann jedoch weiterhin manuell ausgewählt werden. |
| Unterstützung für rekursive parametrisierte Ausdrücke in DSQL-Maps | Die parametrisierten Ausdrücke unterstützen jetzt Rekursion. Dies bedeutet, dass Sie einen parametrisierten Ausdruck innerhalb desselben parametrisierten Ausdrucks aufrufen können. |
| Unterstützung für die Funktion Test run (Testausführung) in ausgerollten und geteilten Elementen in DSQL-Maps | Sie können jetzt die Option Test Run (Testausführung) in bestimmten ausgerollten und geteilten Elementen in DSQL-Maps verwenden.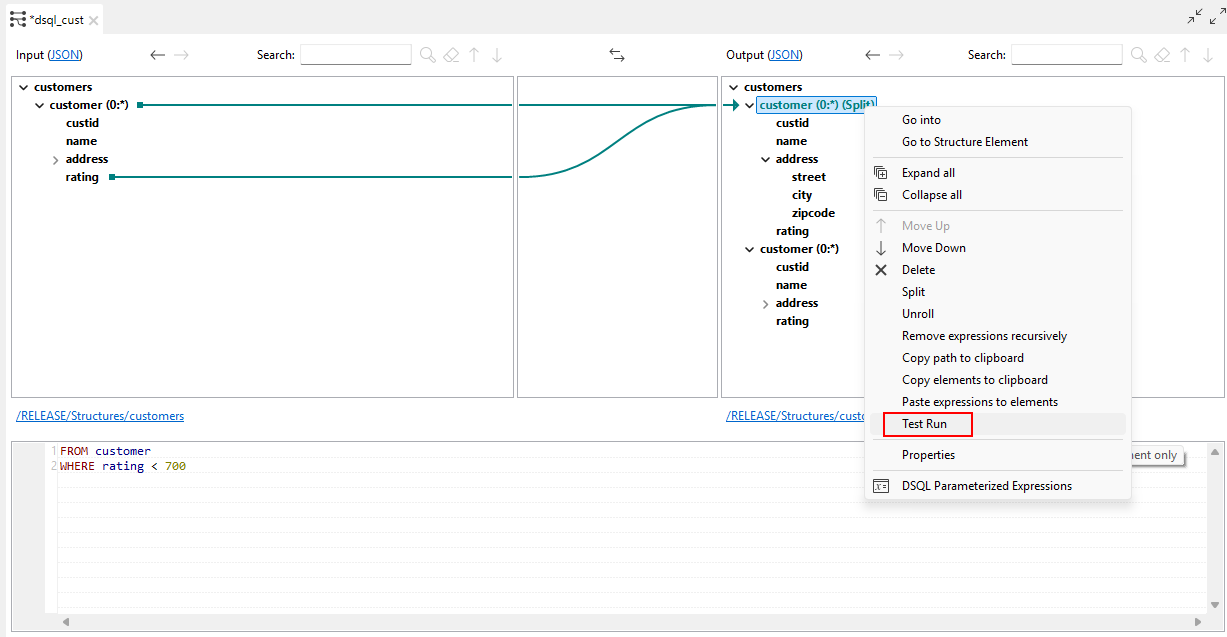 |
| Möglichkeit zum Ziehen und Ablegen von Funktionen und Map-Elementen in parametrisierten Ausdrücken in DSQL-Maps | Sie können jetzt eine Funktion und ein Eingabe-Map-Element in den Inhalt eines parametrisierten Ausdrucks ziehen und dort ablegen. |
| Möglichkeit zum Ziehen und Ablegen parametrisierter Ausdrücke im Ausdruckseditor in DSQL-Maps | Sie können einen parametrisierten Ausdruck jetzt in den Ausdruckseditor Ihrer DSQL-Map ziehen und dort ablegen. Das Verhalten entspricht demjenigen beim Ziehen und Ablegen einer Funktion im Ausdruckseditor.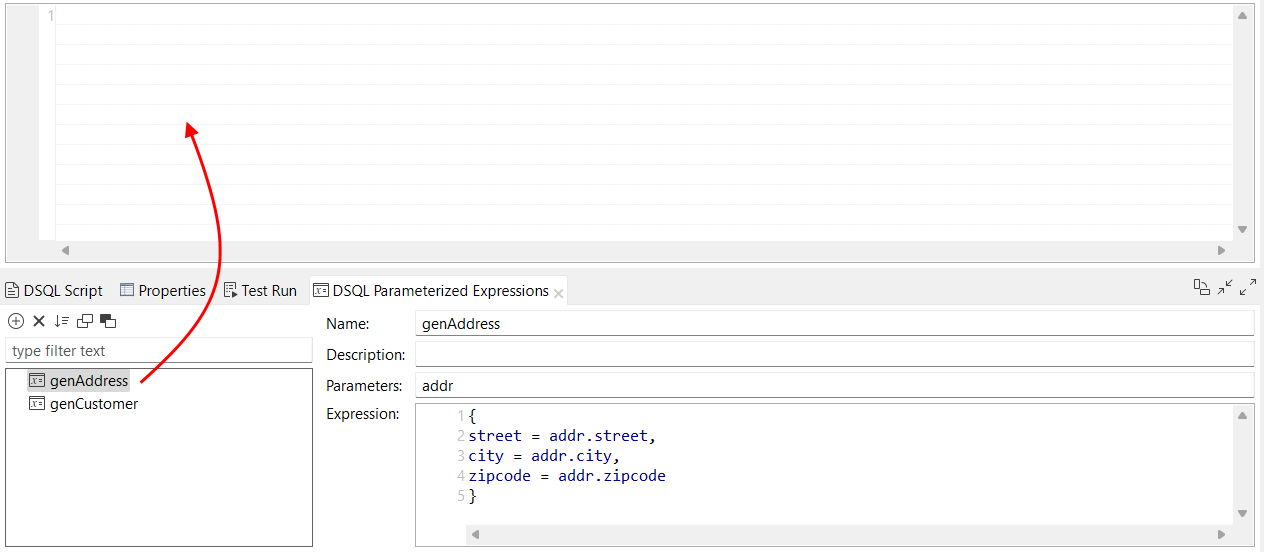 |
| Neue Optionen zum Kopieren und Einfügen von parametrisierten Ausdrücken in DSQL-Maps | Sie können einen oder mehrere parametrisierte Ausdrücke kopieren und diese entweder in Ihre aktuelle DSQL-Map oder in eine andere DSQL-Map einfügen. Die Optionen Name, Description (Beschreibung), Parameters (Parameter) und Expression (Ausdruck) werden kopiert. Wenn ein parametrisierter Ausdruck mit demselben Namen bereits in der Ziel-Map vorhanden ist, wird die Kopie automatisch mit einem Suffix umbenannt, wie z. B. genAddress_2. 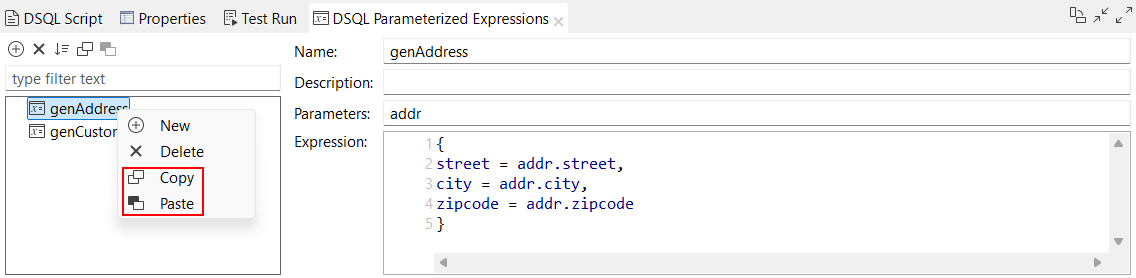 |
| Die neue Option Create Parameterized Expression (Parametrisierten Ausdruck erstellen) ist für den Fehler Unknown function (Unbekannte Funktion) in DSQL-Maps verfügbar | Enthält eine DSQL-Map ein Fragment mit einem Fehler vom Typ Unknown function (Unbekannte Funktion), steht jetzt beim Rechtsklicken auf den Fehler die Funktion Create Parameterized Expression (Parametrisierten Ausdruck erstellen) zur Verfügung, mit der Sie einen parametrisierten Ausdruck mit dem unbekannten Namen erstellen können. 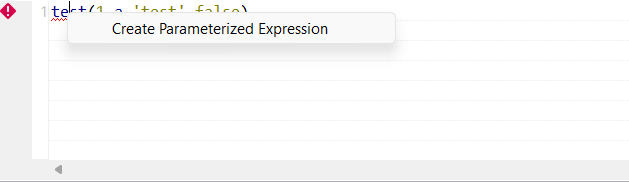 |