
Configurer le tHDFSInput
Procédure
-
Double-cliquez sur le tHDFSInput pour ouvrir sa vue Component.
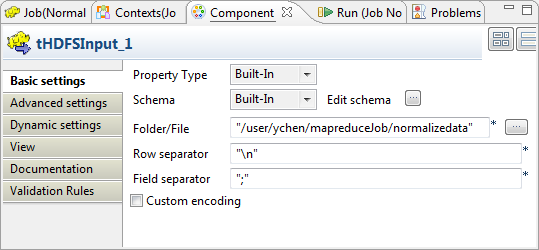
-
Cliquez sur le bouton
 situé à côté du champ Edit schema afin de vérifier si le schéma reçu dans les étapes précédentes a été correctement défini.
situé à côté du champ Edit schema afin de vérifier si le schéma reçu dans les étapes précédentes a été correctement défini.
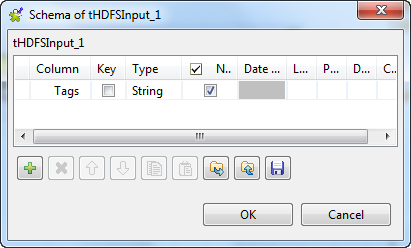 Notez que si vous avez créé ce Job à partir d'un Job vierge, vous devez cliquer sur le bouton
Notez que si vous avez créé ce Job à partir d'un Job vierge, vous devez cliquer sur le bouton afin d'ajouter manuellement ces colonnes au schéma. Si le schéma a été défini dans le Repository, vous pouvez sélectionner l'option Repository dans la liste Schema de la vue Basic settings afin de le réutiliser. Pour plus d'informations concernant la définition d'un schéma dans le Repository, consultez le chapitre décrivant la gestion des métadonnées dans le Guide d'utilisation du Studio Talend ou le chapitre décrivant le nœud Hadoop cluster du Repository, dans le Guide de prise en main de Talend Big Data.
afin d'ajouter manuellement ces colonnes au schéma. Si le schéma a été défini dans le Repository, vous pouvez sélectionner l'option Repository dans la liste Schema de la vue Basic settings afin de le réutiliser. Pour plus d'informations concernant la définition d'un schéma dans le Repository, consultez le chapitre décrivant la gestion des métadonnées dans le Guide d'utilisation du Studio Talend ou le chapitre décrivant le nœud Hadoop cluster du Repository, dans le Guide de prise en main de Talend Big Data.