
Charger/retirer des données dans/de Amazon S3
Ce scénario décrit un Job générant un fichier délimité, le chargeant le fichier dans S3, chargeant des données du fichier de S3 dans Redshift et les affichant dans la console. Ce Job retire ensuite les données de Redshift, les ajoute dans des fichiers S3 pour chaque slice du cluster Redshift, puis liste et obtient les fichiers retirés dans S3.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
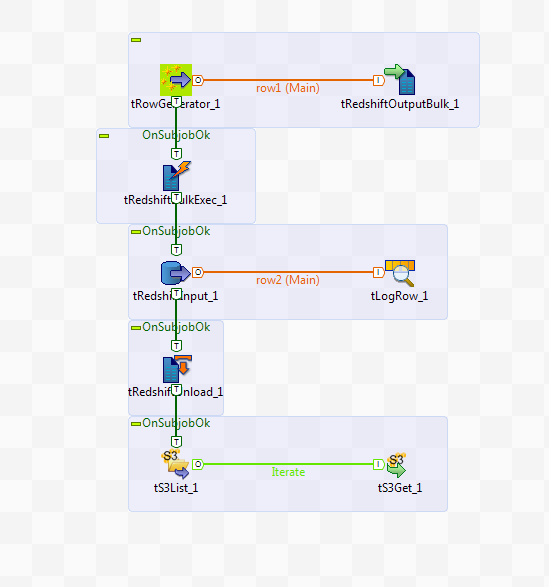
Prérequis :
Les variables de contexte sont créées et sauvegardées dans la vue Repository. Pour plus d'informations concernant les variables de contexte, consultez le Guide d'utilisation du Studio Talend.
-
redshift_host : URL de l'endpoint de connexion au cluster Redshift.
-
redshift_port : numéro du port d'écoute du serveur de la base de données.
-
redshift_database : nom de la base de données.
-
redshift_username : nom de l'utilisateur ou de l'utilisatrice pour l'authentification à la base de données.
-
redshift_password : mot de passe pour l'authentification à la base de données.
-
redshift_schema : nom du schéma.
-
s3_accesskey : clé d'accès à Amazon S3.
-
s3_secretkey : clé secrète pour accéder à Amazon S3.
-
s3_bucket : nom du bucket Amazon S3.

Notez que toutes les valeurs de contexte dans la capture d'écran ci-dessus ont pour seul objectif la démonstration.