
Een project voor een gegevenspijplijn maken
U kunt een gegevenspijplijn maken om al uw data-integratie binnen een project uit te voeren met behulp van gegevenstaken. Onboarding verplaatst gegevens naar het project vanuit gegevensbronnen die on-premises of in de cloud zijn en slaat de gegevens op in direct te gebruiken gegevensverzamelingen. U kunt gegevens onboarden naar een datawarehouse of naar Qlik Open Lakehouse.
Wanneer u gegevens onboardt naar een datawarehouse, kunt u ook transformaties uitvoeren en datamarts maken om uw gegenereerde en getransformeerde gegevensverzamelingen te benutten. De gegevenspijplijn kan eenvoudig en lineair zijn, of het kan een complexe pijplijn zijn die verschillende gegevensbronnen verbruikt en veel uitvoer genereert.
Alle gegevenstaken worden gemaakt in dezelfde ruimte als het project waartoe ze behoren.
U kunt ook de herkomst bekijken om gegevens en gegevenstransformaties terug te volgen naar de oorspronkelijke bron, en een impactanalyse uitvoeren die de toekomstgerichte, downstream weergave toont van afhankelijkheden van gegevenstaken, gegevensverzamelingen of velden. Zie Werken met herkomst en impactanalyse in Gegevensintegratie voor meer informatie.
Onboarding van gegevens naar een datawarehouse
Dit omvat de tussenopslag van de gegevens in een staging-gebied en vervolgens het opslaan van de gegevensverzamelingen in een clouddatawarehouse. Gegevenstaken voor tussenopslag en opslag worden in één stap gemaakt. Indien nodig kunt u tussenopslag en opslag ook met afzonderlijke taken uitvoeren.
Gegevens onboarden naar Qlik Open Lakehouse
Maak een Qlik Open Lakehouse-pijplijnproject om gegevens van een ondersteunde bron te kopiëren naar de open tabelindeling van Iceberg. Tabellen kunnen worden geopend en opgevraagd vanuit de analyse-engine van uw clouddatawarehouse, zonder gegevens te dupliceren door een Mirror-gegevenstaak te gebruiken.
Gegevens registreren die al op het gegevensplatform bestaan
Registreer gegevens die al op het gegevensplatform bestaan om gegevens te beheren en te transformeren, en datamarts te maken. Hiermee kunt u gegevens gebruiken die zijn ge-onboard met andere tools dan Qlik Talend Data Integration, bijvoorbeeld Qlik Replicate of Stitch.
Gegevens transformeren
Maak herbruikbare transformaties op rijniveau op de ge-onboarde gegevens op basis van regels en aangepaste SQL. Hiermee wordt een taak Gegevens transformeren gemaakt.
Datamarts maken en beheren
Maak een datamart om uw gegevensverzamelingen te benutten. Hiermee wordt een Datamart-gegevenstaak gemaakt.
Knowledgemarts maken
Maak een knowledge mart om uw gestructureerde en ongestructureerde gegevens in te sluiten en op te slaan in een vectordatabase. Hiermee wordt een Knowledge mart-gegevenstaak gemaakt.
Doelgegevensplatforms
Het project is gekoppeld aan een gegevensplatform dat wordt gebruikt als doel voor alle uitvoer.
Zie Verbindingen naar doelen instellen voor meer informatie over ondersteunde gegevensplatforms.
Video-introductie tot projecten
Voorbeeld van het maken van een project
In het volgende voorbeeld worden gegevens ge-onboard, de gegevens getransformeerd en een datamart gemaakt. Hiermee wordt een eenvoudige lineaire gegevenspijplijn gemaakt die u kunt uitbreiden door meer gegevensbronnen te onboarden, meer transformaties te maken en de gegenereerde gegevenstaken toe te voegen aan de datamart.
Voorbeeld van een lineaire gegevenspijplijn in een project

-
Maak een nieuw project.
Klik in Data Integration > Pijplijnprojecten op Nieuwe maken > Project.
-
Voer een naam en een beschrijving in voor het project.
InformatieAls u later versiebeheer voor het project inschakelt, kunt u de projectnaam niet meer wijzigen zolang deze onder versiebeheer valt. -
Selecteer een ruimte om het project in te maken. Alle gegevenstaken worden gemaakt in de ruimte van het project waartoe ze behoren.
- Selecteer Gegevenspijplijn in Use case.
-
Selecteer welk gegevensplatform u in het project wilt gebruiken.
-
Selecteer een verbinding met het clouddatawarehouse dat u in het project wilt gebruiken. Dit wordt gebruikt voor de tussenopslag van gegevensbestanden en het opslaan van gegevensverzamelingen en weergaven. Als u nog geen verbinding hebt voorbereid, maakt u er een met Nieuwe maken.
-
Als u Google BigQuery, Databricks of Microsoft Azure Synapse Analytics als gegevensplatform hebt geselecteerd, moet u ook verbinding maken met een staging-gebied.
-
Als u Snowflake als gegevensplatform hebt geselecteerd, kunt u ervoor kiezen om gegevens in de cloudopslag te plaatsen (tussenopslag). Zie Tussenopslag in een lakehouse.
-
Als u Qlik Cloud als gegevensplatform hebt geselecteerd:
U kunt gegevens opslaan in door Qlik beheerde opslag of in uw eigen beheerde Amazon S3-bucket. Als u uw eigen Amazon S3-bucket wilt gebruiken, moet u een verbinding met die bucket selecteren.
In beide gevallen moet u ook een verbinding met een Amazon S3-staging-gebied selecteren. Als u dezelfde bucket gebruikt die u in de vorige stap hebt gedefinieerd, zorg er dan voor dat u een andere map in de bucket gebruikt voor staging.
-
-
Klik op Maken.
Het project is gemaakt en u kunt uw gegevenspijplijn maken door gegevenstaken toe te voegen.
-
-
De gegevens onboarden
Klik in het project op Maken en vervolgens op Gegevens onboarden.
Zie Onboarding van gegevens naar een datawarehouse voor meer informatie.
Hiermee wordt een gegevenstaak voor tussenopslag en een opslaggegevenstaak gemaakt. Om te beginnen met het repliceren van gegevens, moet u:
-
De gegevenstaak voor tussenopslag voorbereiden en uitvoeren.
Zie Gegevens tussenoplaan uit gegevensbronnen voor meer informatie.
-
De opslaggegevenstaak voorbereiden en uitvoeren.
Zie Gegevensverzamelingen opslaan voor meer informatie.
-
-
De gegevens transformeren
Wanneer de opslaggegevenstaak is gemaakt, gaat u terug naar het project. U kunt nu transformaties uitvoeren op de gemaakte gegevensverzamelingen.
Klik op ... op de opslaggegevenstaak en selecteer Gegevens transformeren om een transformatiegegevenstaak te maken op basis van deze opslaggegevenstaak. Zie Gegevens transformeren voor instructies over transformaties.
-
Een datamart maken
U kunt een datamart maken op basis van een opslaggegevenstaak of een transformatiegegevenstaak.
Klik op ... op de gegevenstaak en selecteer Datamart maken om een datamart-gegevenstaak te maken. Zie voor instructies over het maken van een datamart:
Wanneer u de eerste volledige lading van de opgeslagen en getransformeerde gegevensverzamelingen en datamarts hebt uitgevoerd, kunt u deze bijvoorbeeld gebruiken in een analytische applicatie. Zie Een analyse-app maken met behulp van gegevensverzamelingen die zijn gegenereerd in Gegevensintegratie voor meer informatie over het maken van analytische applicaties.
U kunt de gegevenspijplijn ook uitbreiden door meer gegevensbronnen te onboarden en deze te combineren in de transformatie of in de datamart.
Projectoverschrijdende pijplijnen bouwen
U kunt projectoverschrijdende pijplijnen bouwen waarbij een taak taken uit een ander project kan verbruiken. Hiermee kunt u op verschillende manieren segmentatie bereiken:
-
U kunt voor elke organisatie-eenheid een afzonderlijke pijplijn voor gegevensverplaatsing maken en de uitvoer in één datamart-pijplijn verbruiken.
-
U kunt één pijplijn voor gegevensverplaatsing maken en de uitvoer in verschillende transformatiepijplijnen verbruiken.
Taken voor transformatie en datamarts kunnen opslag- en transformatietaken verbruiken die zich in een ander project bevinden.
-
U moet ten minste de rol Kan verbruiken hebben in de ruimte van het verbruikte project.
-
Beide projecten moeten zich op hetzelfde gegevensplatform bevinden.
Alle gegevensverzamelingen van een taak worden gedeeld met downstream-projecten. Dit betekent dat als u scheiding van gegevensverzamelingen wilt bereiken, u gegevensverzamelingen in het verbruikte project moet uitfilteren door een transformatietaak te maken.
In de projectweergave kunt u taken bekijken die door een ander project worden verbruikt, en taken uit andere projecten die in het huidige project worden verbruikt. Alle taken buiten het huidige project zijn grijs. De afhankelijkheden zijn op basis van referentie en niet op naam, wat betekent dat u de naam van een taak kunt wijzigen zonder de referentie te verbreken. Dit betekent ook dat als u een taak verwijdert die wordt verbruikt en een nieuwe taak met dezelfde naam maakt, de referentie nog steeds verbroken is.
Er zijn verschillende manieren om bestaande gegevens te hergebruiken:
-
Een nieuw project maken
Selecteer de optie Gegevens uit een ander project gebruiken na het maken van een project.
U kunt een transformatie of een datamart maken, waarbij ge-onboarde gegevens uit een andere pijplijn worden verbruikt.
-
In een transformatietaak of datamart-taak kunt u gegevens uit een ander project selecteren in Brongegevens selecteren.
Selecteer bij het selecteren van brongegevens Project. Als het geselecteerde project onder versiebeheer valt, selecteert u een Branch. De standaardbranch is main. De lijst met gegevenstaken wordt bijgewerkt om de geselecteerde branch weer te geven. Selecteer vervolgens een Gegevenstaak om te zien welke gegevensverzamelingen beschikbaar zijn.
U kunt kiezen of u taken in andere projecten wilt weergeven die een taak in dit project verbruiken.
-
Klik op Lagen en schakel Projectoverschrijdende uitvoer in of uit.
Alle taken buiten het huidige project zijn grijs.
Beperkingen van versiebeheer
Omdat projectoverschrijdende pijplijnen over verschillende projecten zijn verdeeld, voegt dit complexiteit toe bij het gebruik van versiebeheer. In deze voorbeelden wordt Project1 verbruikt door Project2.
Voorbeeld van een projectoverschrijdende pijplijn

-
Project2 kan een specifieke branch van Project1 verbruiken. Selecteer de branch in Brongegevens selecteren in de transformatie- of datamart-taak. De standaardbranch is main. Als het gerefereerde project niet onder versiebeheer valt, wordt de branch-selector niet weergegeven en gebruikt Project2 het project zoals het is.
-
U kunt een branch maken voor Project1, maar de vertakte versie zal niet laten zien dat deze wordt verbruikt door Project2.
-
U kunt Project2 samenvoegen met main, maar de afhankelijkheid blijft bestaan.
Als de geselecteerde branch in Project1 later wordt verwijderd, wordt de referentie op dezelfde manier verbroken als wanneer een gerefereerde taak wordt verwijderd. Als de gerefereerde taak een andere uitvoer heeft op de geselecteerde branch, gedraagt de referentie zich op dezelfde manier als wanneer de uitvoer van de gerefereerde taak verandert.
Best practices
-
Controleer of de taken in het verbruikte project ten minste zijn voorbereid, om er zeker van te zijn dat ze geldig zijn.
-
Als u van plan bent projecten te exporteren en importeren tussen tenants, is het gemakkelijker als u dezelfde namen aanhoudt voor ruimten en projecten in de tenants. Als de namen verschillen, moet u projecten en taken toewijzen bij het importeren van het project.
-
Als u het gegevensplatform wilt wijzigen met behulp van exporteren en importeren, moeten alle projecten met afhankelijkheden zich op hetzelfde platform bevinden.
Volg deze stappen voor een veilige en eenvoudige platformwijziging. In dit voorbeeld heet het project dat wordt verbruikt Consumed, en het project dat leest uit Consumed heet Consumer.
-
Exporteer Consumed en Consumer.
-
Importeer Consumed naar Consumed_New, waarbij u overschakelt naar het nieuwe gegevensplatform.
-
Importeer Consumer naar Consumer_New, waarbij u overschakelt naar hetzelfde gegevensplatform als Consumed_New, en het bronproject (Consumed) vervangt door Consumed_New.
-
Bewerkingen in een project voor een gegevenspijplijn
U kunt dezelfde bewerkingen die beschikbaar zijn voor een gegevenstaak uitvoeren als projectbewerkingen. Hiermee kunt u de bewerkingen in de gegevenspijplijn orkestreren.
-
Schema's in- en uitschakelen
-
Ontwerpbewerkingen uitvoeren
-
Uitvoering van gegevenstaken starten en stoppen
-
Gegevenstaken verwijderen
Klik op Bewerkingen om de status van een bewerking in uitvoering of de laatst uitgevoerde bewerking te bekijken.
U kunt een bewerking in uitvoering stoppen door op Bewerking stoppen te klikken. Gegevenstaken die in uitvoering zijn, worden niet gestopt, maar het annuleert elke taak die nog niet is gestart.
Schema's in- en uitschakelen
U kunt de schema's voor gegevenstaken op projectniveau beheren.
-
Klik op ... en vervolgens op Schema.
U kunt het schema in- of uitschakelen voor alle gegevenstaken of een selectie van taken. Alleen taken met een gedefinieerd schema worden weergegeven.
InformatieDeze optie is niet beschikbaar voor projecten met Qlik Cloud als gegevensplatform.
Zie voor meer informatie over het plannen van individuele gegevenstaken:
Ontwerpbewerkingen uitvoeren
U kunt ontwerpbewerkingen uitvoeren op alle gegevenstaken in het project of op een selectie van taken. Dit maakt het gemakkelijker om de taken voor gegevensverzamelingen in het project te beheren, in plaats van de ontwerpbewerkingen afzonderlijk in elke taak uit te voeren.
-
Valideren
Klik op Valideren om alle taken of een selectie van taken te valideren. Gegevenstaken die zijn gewijzigd sinds de laatste validatiebewerking, zijn vooraf geselecteerd.
De gegevenstaken worden gevalideerd in de volgorde van de pijplijn.
-
Voorbereiden
Klik op Voorbereiden om alle taken of een selectie van taken voor te bereiden. Gegevenstaken die zijn gewijzigd sinds de laatste voorbereidingsbewerking, zijn vooraf geselecteerd.
U kunt ervoor kiezen om gegevensverzamelingen opnieuw te maken die een structuurwijziging vereisen die niet wordt ondersteund door het gegevensplatform. Dit kan leiden tot gegevensverlies.
-
Opnieuw maken
Klik op ... en vervolgens op Tabellen opnieuw maken om de gegevensverzamelingen vanaf de bron opnieuw te maken voor alle taken of voor een selectie van taken.
InformatieAls er problemen met afzonderlijke tabellen zijn, wordt aanbevolen om eerst de tabellen opnieuw te laden voordat u ze opnieuw maakt. Door het opnieuw maken van de tabellen kunnen historische gegevens verloren gaan. Als er grote wijzigingen zijn, moet u ook downstream gegevenstaken voorbereiden die gebruikmaken van de opnieuw gemaakte gegevenstaken om de gegevens te laden.
Gegevenstaken uitvoeren
U kunt de uitvoering van alle gegevenstaken in het project of van een selectie van taken initiëren, in plaats van taken afzonderlijk uit te voeren. U kunt bijvoorbeeld alle taken met een op tijd gebaseerd schema uitvoeren. Dit initieert downstream-taken met een op gebeurtenissen gebaseerd schema.
-
Uitvoeren
Klik op Uitvoeren om de uitvoering van alle taken of een selectie van taken te initiëren. Dit initieert de uitvoering van alle geselecteerde taken en is voltooid zodra ze beginnen met uitvoeren.
U kunt kiezen uit alle taken die klaar zijn om te worden uitgevoerd. Taken met een op tijd gebaseerd schema en taken die CDC gebruiken, zijn vooraf geselecteerd. Taken met een op gebeurtenissen gebaseerd schema zijn niet vooraf geselecteerd, omdat ze worden uitgevoerd wanneer ze gegevens te verwerken hebben.
In een project met Qlik Cloud als gegevensplatform zijn alle taken voor tussenopslag en opslag vooraf geselecteerd.
InformatieAlle gegevenstaken worden parallel uitgevoerd. Dit betekent dat afhankelijkheidscontroles kunnen voorkomen dat sommige taken worden uitgevoerd. -
Stoppen
Klik op Stoppen om alle taken of een selectie van taken te stoppen.
U kunt kiezen uit taken die worden uitgevoerd.
Gegevenstaken verwijderen
-
Klik op Verwijderen om alle gegevenstaken in het project of een selectie van taken te verwijderen.
Het is niet mogelijk om taken te verwijderen die worden uitgevoerd of taken die door andere taken worden gebruikt.
De weergave van een project wijzigen
Er zijn twee verschillende weergaven van een project. U kunt tussen de weergaven schakelen door op Pijplijnweergave te klikken.
-
De pijplijnweergave toont de gegevensstroom van de gegevenstaken.
U kunt kiezen hoeveel informatie u voor de gegevenstaken wilt weergeven door op Lagen te klikken. Schakel de volgende informatie in of uit:
-
Status
-
Actualiteit van gegevens
-
Schema
-
Projectoverschrijdende uitvoer
Hiermee worden taken in andere projecten weergegeven die een taak in dit project verbruiken. Alle taken buiten het huidige project zijn grijs.
-
-
De kaartweergave toont een kaartweergave met informatie over de gegevenstaak.
U kunt filteren op assettype en eigenaar.
Een project verwijderen
-
Klik in de weergave Pijplijnprojecten op
 bij een project en selecteer Verwijderen.
bij een project en selecteer Verwijderen.
U kunt ervoor kiezen om artefacten (tabellen en weergaven) die door een taak zijn gemaakt, voor elke afzonderlijke taak te behouden, behalve voor de volgende typen waarbij artefacten altijd worden behouden:
-
Taken voor tussenopslag
-
Taken voor tussenopslag in lake
-
Replicatietaken
Gegevens bekijken
U kunt een voorbeeld van de gegevens bekijken om de vorm van uw gegevens te zien en te valideren terwijl u uw gegevenspijplijn ontwerpt.
De volgende machtigingen zijn vereist:
-
Het bekijken van gegevens is ingeschakeld op tenantniveau in Beheer.
Schakel Instellingen > Functiebeheer > Gegevens bekijken in Gegevensintegratie in.
-
U hebt de rol Kan gegevens bekijken toegewezen gekregen in de ruimte waar de verbinding zich bevindt.
-
U hebt de rol Kan bekijken toegewezen gekregen in de ruimte waar het project zich bevindt.
Om voorbeeldgegevens in de gegevenspijplijnweergave te bekijken:
-
Klik op
 in de preview-banner onderaan de pijplijnweergave.
in de preview-banner onderaan de pijplijnweergave. -
Selecteer voor welke gegevenstaak u een voorbeeld van de gegevens wilt bekijken.
Er wordt een voorbeeld van de gegevens weergegeven. U kunt instellen hoeveel gegevensrijen in het voorbeeld moeten worden opgenomen met Aantal rijen.
Projecten exporteren en importeren
U kunt een project exporteren naar een JSON-bestand dat alles bevat wat nodig is om het project te reconstrueren. Het geëxporteerde JSON-bestand kan op dezelfde tenant of op een andere tenant worden geïmporteerd. U kunt dit bijvoorbeeld gebruiken om projecten van de ene tenant naar de andere te verplaatsen, of om back-upkopieën van projecten te maken.
Zie Gegevenspijplijnen exporteren en importeren voor meer informatie.
Eigenaar van een project wijzigen
Gegevenstaken werken in de context van de eigenaar van het project waartoe ze behoren. U kunt de eigenaar van een project wijzigen om de controle over alle taken in het gegevensproject over te dragen aan een andere gebruiker. Dit is bijvoorbeeld handig als er projecten zijn die eigendom zijn van een gebruiker die is verwijderd.
-
Klik in de projectweergave op ... en vervolgens op Eigenaar wijzigen.
De wijziging van eigendom is van toepassing op alle taken in het project. Alle gecatalogiseerde gegevensverzamelingen die door taken in het project zijn gemaakt, veranderen ook van eigenaar.
Verbinding met gegevensplatform wijzigen
Als u de verbinding met het Gegevensplatform voor een project wijzigt, moet u:
-
Tabellen opnieuw maken in alle taken voor tussenopslag.
-
Alle andere taken in het project voorbereiden.
Projectinformatie bekijken
Klik op ![]() in de menubalk om projectinformatie te bekijken, zoals:
in de menubalk om projectinformatie te bekijken, zoals:
-
Eigenaar
-
Ruimte
-
Gegevensplatform
-
Project-id
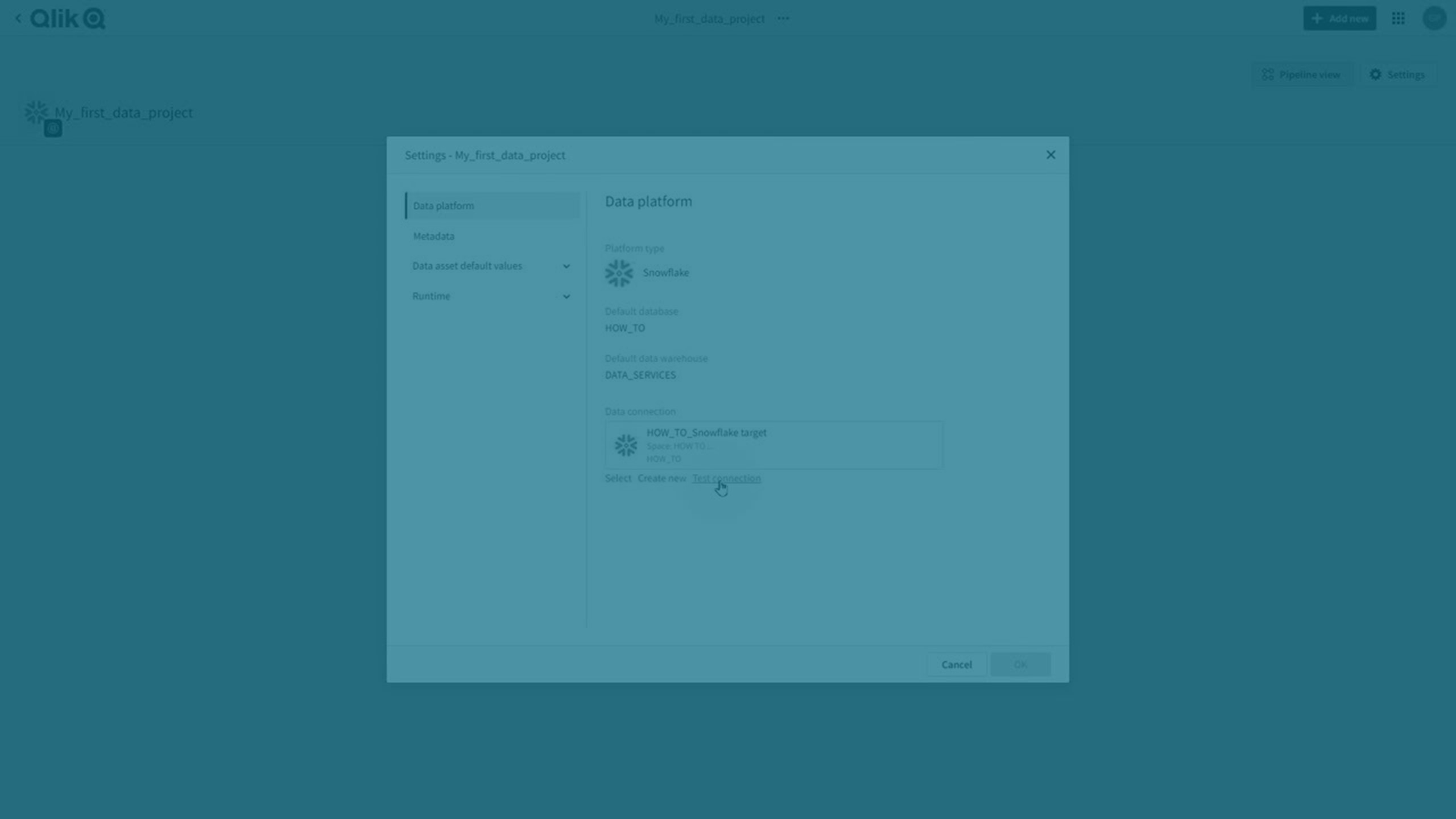
Projectinstellingen
U kunt eigenschappen instellen die gemeenschappelijk zijn voor het project en alle opgenomen gegevenstaken.
-
Klik op Instellingen.
Zie Projectinstellingen voor datapijplijn voor meer informatie.