Unity Catalogを使って管理対象テーブルで作業
このシナリオでは、管理対象のDelta Lakeテーブルに保存されたデータをUnity Catalogを使って準備、分析、変換するSparkバッチジョブについて説明します。
このシナリオでは、Delta Lakeデータセットの中で最もストリーミングされた曲とアルバムが含まれているストリーミング音楽のレコードで作業しています。Databricksの同じテーブルでシームレスに消費できるよう、人気とジャンル別に曲を分析したいと考えています。
以下は、このシナリオで使用するデータセットのサンプルです: 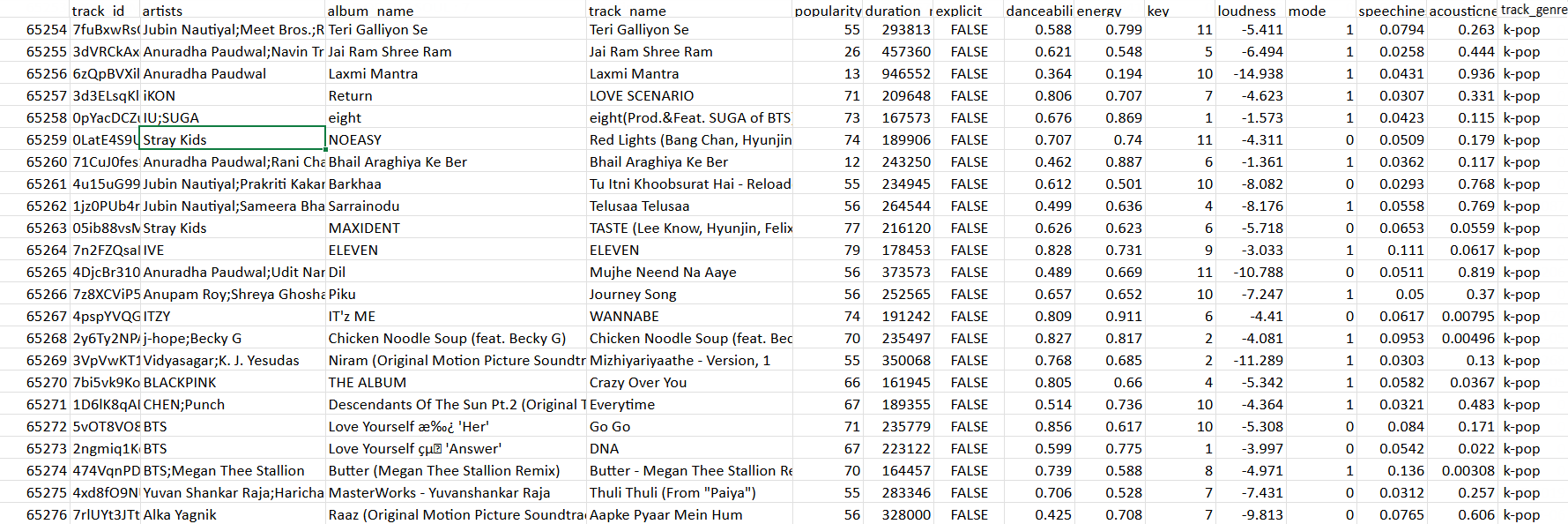
始める前に
Spark Batchジョブを設定
このシナリオでは、サブジョブがいくつか含まれているSpark Batchジョブを作成する必要があります。サブジョブはそれぞれ、異なるアクションを実行するために使われます。 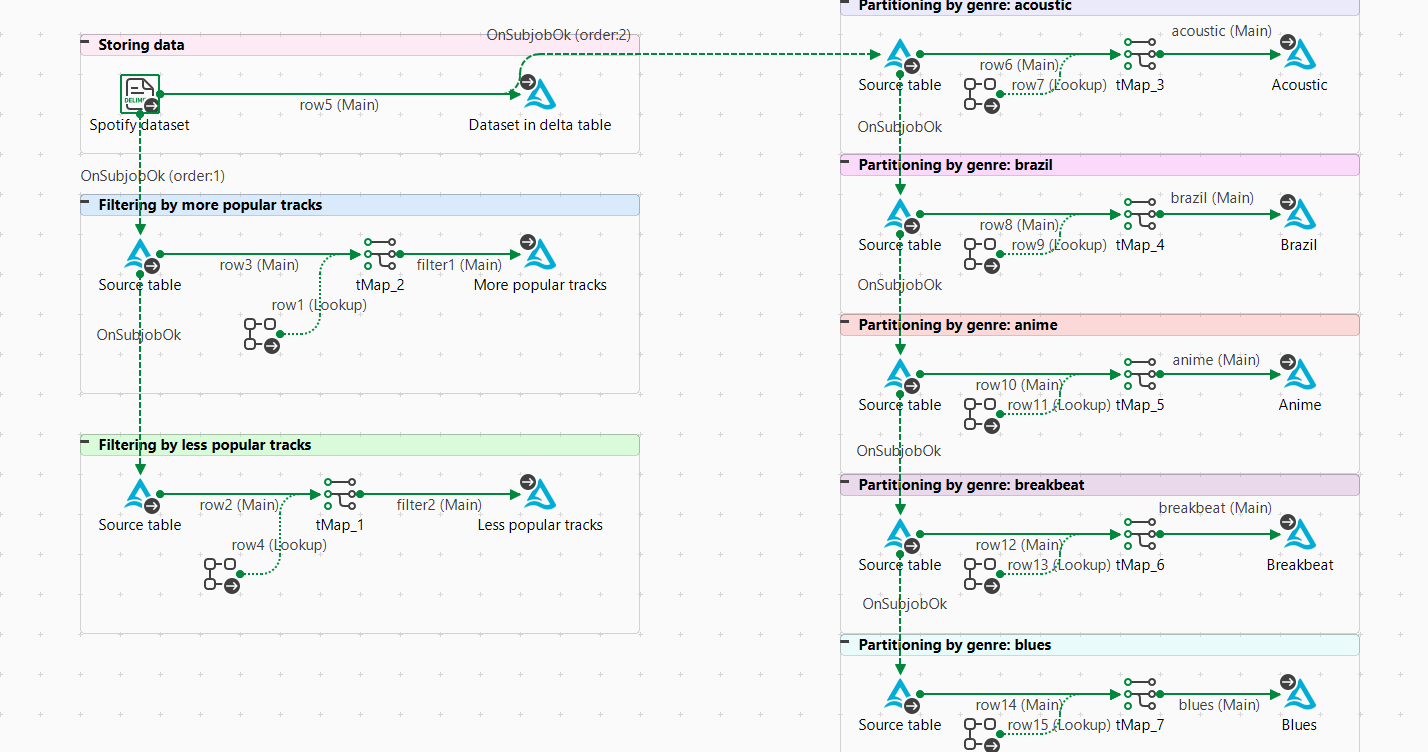
手順
データをUnity Catalogに保存
このシナリオの最初のステップは、ストリーミング音楽のレコードが含まれているCSVファイルをTalend Studioにロードし、データセットをDelta Lakeテーブルに保存することでです。
このタスクについて
手順
-
tFileInputDelimitedの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tFileInputDelimitedの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tfileinputdelimited1.png)
- [Property Type] (プロパティタイプ)ドロップダウンリストと[Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Folder/File] (フォルダー/ファイル)パラメーターに、使用するデータを指すパスを入力します。この例では、CSVファイルです。
- 他のパラメーターはそのままにしておきます。
-
tDeltaLakeOutputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tDeltaLakeOutputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tdeltalakeoutput1.png)
- [Define how to save the dataset] (データセットを保存する方法を定義)ドロップダウンリストから、Unity Catalogを選択します。
- [Property Type] (プロパティタイプ)ドロップダウンリストと[Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Action] (アクション)ドロップダウンリストから、[Overwrite] (上書き)を選択します。
- [Catalog] (カタログ)パラメーターに、データを保存するカタログの名前を入力します。
- [Schema] (スキーマ)パラメーターに、データを保存するスキーマの名前を入力します。
- [Table] (テーブル)パラメーターに、データを保存するテーブルの名前を入力します。この例では、spotify_dataです。
タスクの結果
人気別に曲をフィルタリング
このシナリオの第2ステップは、Delta Lakeデータセットから曲を人気別にフィルタリングすることです。最初のフィルターは最も人気がある曲に適用され、2番目のフィルターはあまり人気がない曲に適用されます。
このタスクについて
手順
-
tDeltaLakeInputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tDeltaLakeInputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tdeltalakeinput2.png)
- [Define how to read the dataset] (データセットを読み取る方法を定義)ドロップダウンリストから、Unity Catalogを選択します。
- [Property Type] (プロパティタイプ)ドロップダウンリストと[Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Action] (アクション)ドロップダウンリストから、[Overwrite] (上書き)を選択します。
- [Catalog] (カタログ)パラメーターに、データを保存するカタログの名前を入力します。
- [Schema] (スキーマ)パラメーターに、データを保存するスキーマの名前を入力します。
- [Table] (テーブル)パラメーターに、データの読み取り元にしたいテーブルの名前を入力します。この例では、spotify_dataです。
-
tFixedFlowInputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tFixedFlowInputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tfixedflowinput1.png)
- [Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Number of rows] (行数)に、生成する行数を入力します。この例では、1です。
- [Use Single Table] (単一のテーブルを使用)モードを選択し、生成したいデータを関連するフィールドに入力します。この例ではcriteriaというカラムで、値は50です。
-
tMapの[Basic settings] (基本設定)ビューから、次のようにマッピングを設定します:
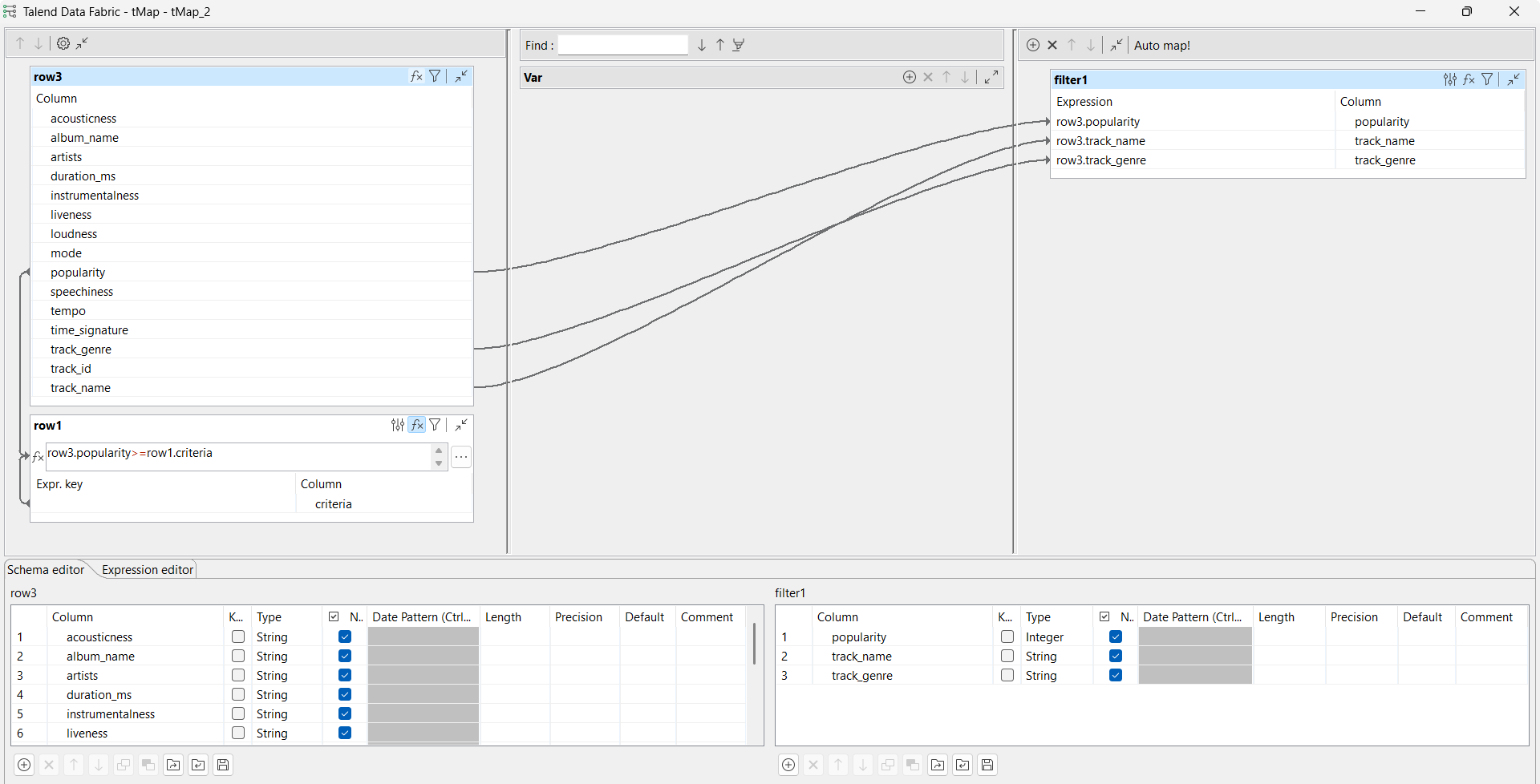
- tMapコンポーネントをダブルクリックして、[Map Editor] (マップエディター)を開きます。
- popularity行の式を作成します。この例では、row3.popularity>=row1.criteriaです。criteriaはtFixedFlowInputコンポーネントで50に設定されているので、この式は、人気が50以上の曲だけをフィルタリングすることを意味しています。
- popularity行、track_name行、track_genre行について、メインの入力フローと新しい入力フローとの結合を作成します。
- [OK]をクリックしてマップ設定を確定し、[Map Editor] (マップエディター)を閉じます。
-
tDeltaLakeOutputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tDeltaLakeOutputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tdeltalakeoutput2.png)
- [Define how to save the dataset] (データセットを保存する方法を定義)ドロップダウンリストから、Unity Catalogを選択します。
- [Property Type] (プロパティタイプ)ドロップダウンリストと[Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Action] (アクション)ドロップダウンリストから、[Overwrite] (上書き)を選択します。
- [Catalog] (カタログ)パラメーターに、データを保存するカタログの名前を入力します。
- [Schema] (スキーマ)パラメーターに、データを保存するスキーマの名前を入力します。
- [Table] (テーブル)パラメーターに、データを保存するテーブルの名前を入力します。この例では、spotify_popularです。
タスクの結果
曲をジャンル別にパーティショニング
このシナリオの第3ステップは、曲を5つのジャンル(この例ではacoustic、brazilian、anime、breakbeat、blues)にパーティショニングすることです。それぞれのジャンルが新しいテーブルを表しています。
このタスクについて
- Partitioning by genre: acoustic
- Partitioning by genre: brazil
- Partitioning by genre: breakbeat
- Partitioning by genre: blues
手順
-
tDeltaLakeInputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tDeltaLakeInputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tdeltalakeinput5.png)
- [Define how to read the dataset] (データセットを読み取る方法を定義)ドロップダウンリストから、Unity Catalogを選択します。
- [Property Type] (プロパティタイプ)ドロップダウンリストと[Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Action] (アクション)ドロップダウンリストから、[Overwrite] (上書き)を選択します。
- [Catalog] (カタログ)パラメーターに、データを保存するカタログの名前を入力します。
- [Schema] (スキーマ)パラメーターに、データを保存するスキーマの名前を入力します。
- [Table] (テーブル)パラメーターに、データの読み取り元にしたいテーブルの名前を入力します。この例では、spotify_dataです。
-
tFixedFlowInputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tFixedFlowInputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tfixedflowinput5.png)
- [Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Number of rows] (行数)に、生成する行数を入力します。この例では、1です。
- [Use Single Table] (単一のテーブルを使用)モードを選択し、生成したいデータを関連するフィールドに入力します。この例ではcriteria3というカラムで、値はanimeです。
-
tMapの[Basic settings] (基本設定)ビューから、次のようにマッピングを設定します:
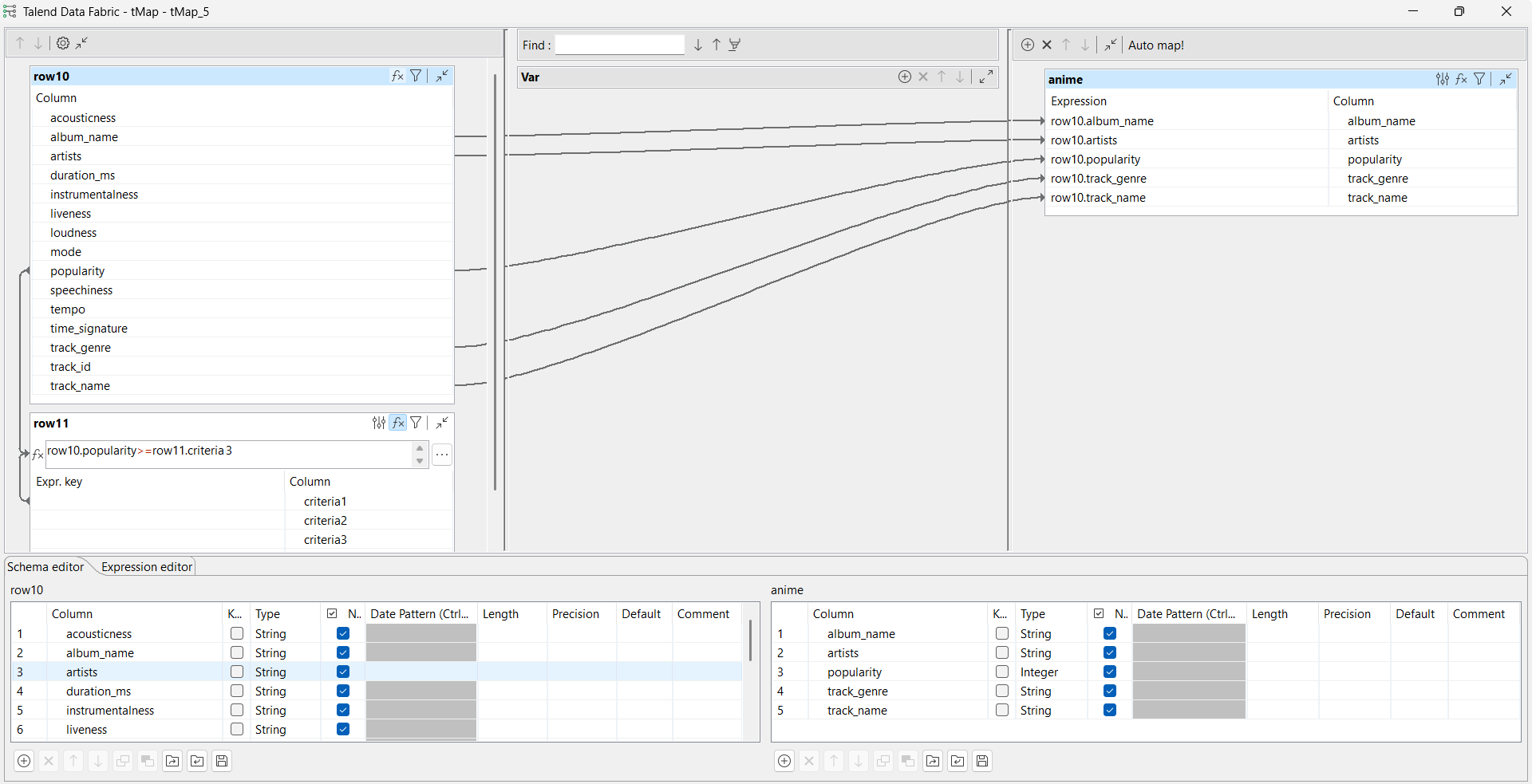
- tMapコンポーネントをダブルクリックして、[Map Editor] (マップエディター)を開きます。
- popularity行の式を作成します。この例では、row10.popularity>=row11.criteria3です。criteria3はtFixedFlowInputコンポーネントでanimeに設定されているので、この式は、ジャンルがアニメである曲だけをフィルタリングすることを意味しています。
- album_name行、artists行、popularity行、track_genre行、track_name行について、メインの入力フローと新しい入力フローとの結合を作成します。
- [OK]をクリックしてマップ設定を確定し、[Map Editor] (マップエディター)を閉じます。
-
tDeltaLakeOutputの[Basic settings] (基本設定)ビューから、次のようにパラメーターを設定します:
![tDeltaLakeOutputの[Basic settings] (基本設定)ビュー。](/talend/ja-JP/components/8.0/Content/Resources/images/unity-catalog-scenario_tdeltalakeoutput6.png)
- [Define how to save the dataset] (データセットを保存する方法を定義)ドロップダウンリストから、Unity Catalogを選択します。
- [Property Type] (プロパティタイプ)ドロップダウンリストと[Schema] (スキーマ)ドロップダウンリストから、[Built-In] (組み込み)を選択します。
- [Action] (アクション)ドロップダウンリストから、[Overwrite] (上書き)を選択します。
- [Catalog] (カタログ)パラメーターに、データを保存するカタログの名前を入力します。
- [Schema] (スキーマ)パラメーターに、データを保存するスキーマの名前を入力します。
- [Table] (テーブル)パラメーターに、データを保存するテーブルの名前を入力します。この例では、spotify_animeです。
タスクの結果
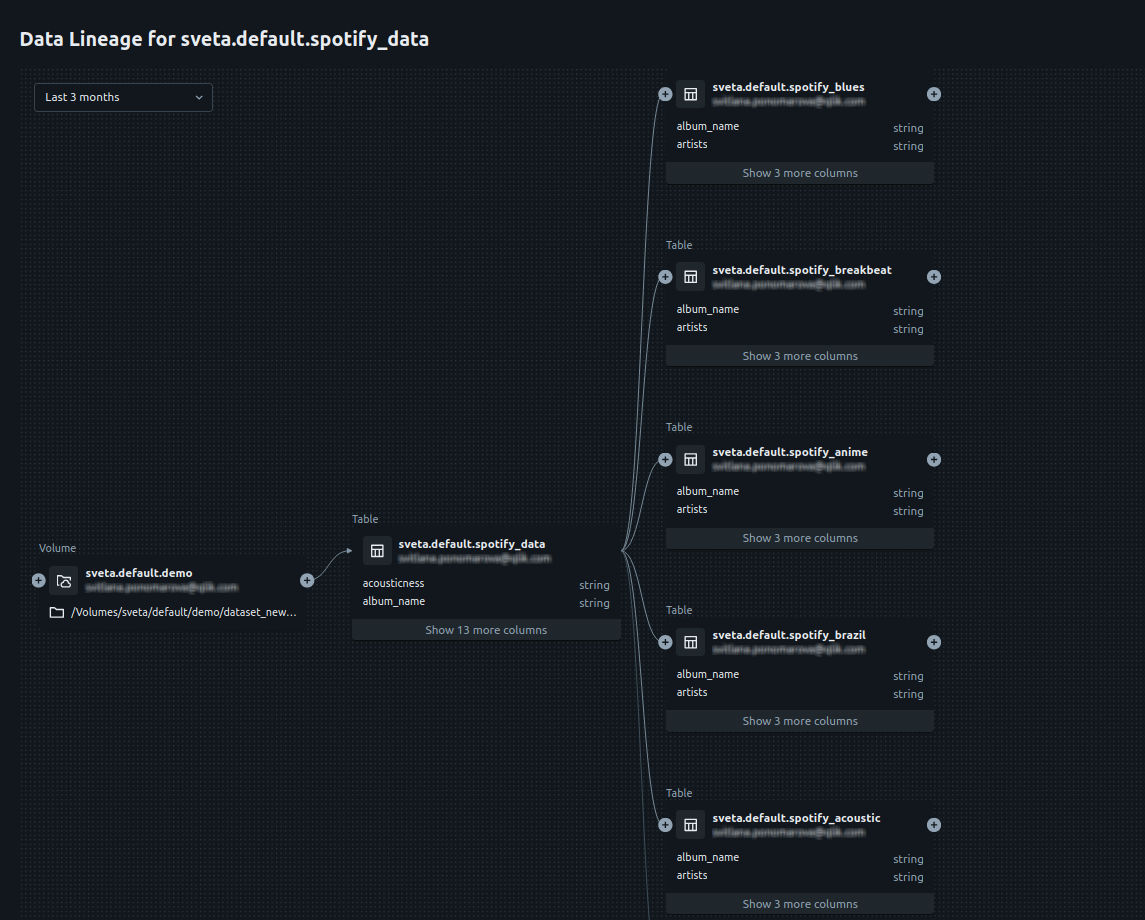
データ来歴を分析
このシナリオの最後のステップは、Unity Catalogのデータ来歴ツールで最終データを分析することです。
手順
-
Databricks側でspotify_dataテーブルを選択し、[Lineage] (来歴)タブに移動します。詳細は、Databricksの公式ドキュメンテーションでCapture and view data lineage using Unity Catalogをご覧ください。
来歴グラフが表示されます。これで、グラフを分析し、CSVファイルから得られる最初のUnity Catalogボリュームに基づいてさまざまなテーブルがどのように作成されたかを確認できます。