
Définir une clé de bloc
Pourquoi et quand exécuter cette tâche
Définir une clé de bloc n'est pas obligatoire mais fortement conseillé. Utiliser une clé de bloc pour partitionner des données en blocs réduit le nombre d'enregistrements nécessitant d'être comparés à des paires d'enregistrements dans chaque bloc. Utiliser des colonnes de bloc est très utile lors du traitement d'un jeu de données volumineux.
Procédure
-
Cliquez sur le nom des colonnes que vous souhaitez utiliser pour partitionner les données traitées en blocs.
Des clés de bloc ayant exactement le même nom que la colonne sélectionnée sont listées dans la table Blocking Key.
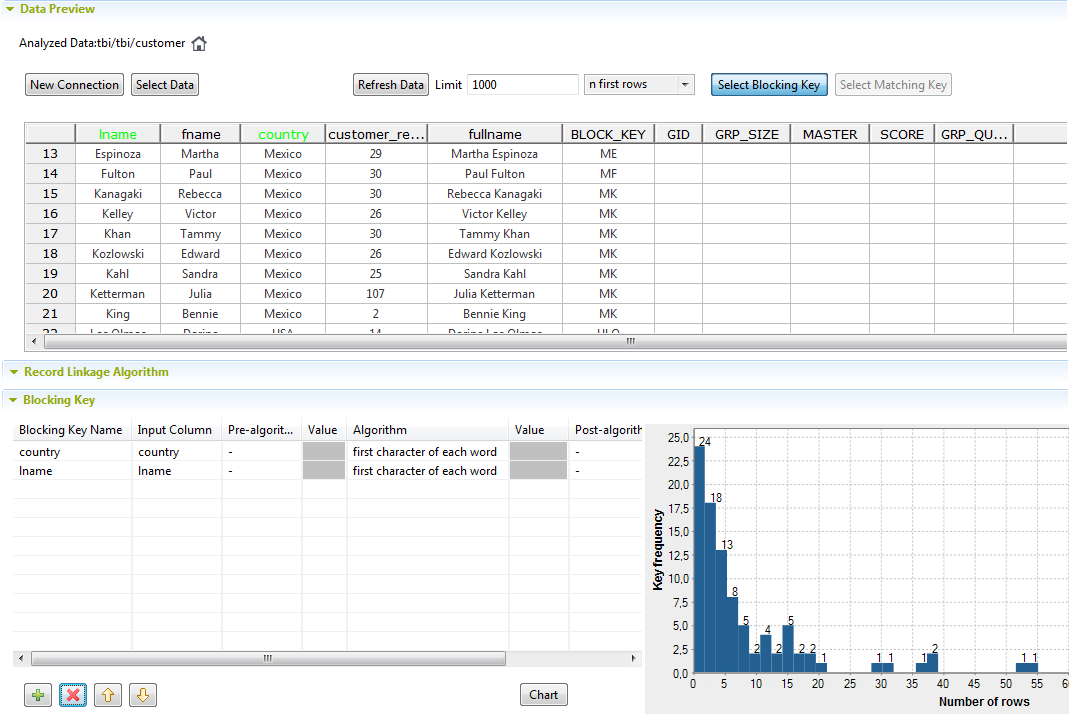 Cependant, une seule clé de bloc est générée et listée dans la colonne BLOCK_KEY de la table Data.Par exemple, si vous utilisez un algorithme sur les colonnes country et lname afin de traiter les enregistrements ayant le même caractère de départ, les enregistrements de données ayant la même première lettre dans le nom du pays ou dans le nom de famille sont groupés dans le même bloc. La comparaison est restreinte à chaque enregistrement dans chaque bloc.Pour supprimer une colonne de la table Blocking key, cliquez-droit dessus et sélectionnez Delete ou cliquez sur son nom dans la table Data.
Cependant, une seule clé de bloc est générée et listée dans la colonne BLOCK_KEY de la table Data.Par exemple, si vous utilisez un algorithme sur les colonnes country et lname afin de traiter les enregistrements ayant le même caractère de départ, les enregistrements de données ayant la même première lettre dans le nom du pays ou dans le nom de famille sont groupés dans le même bloc. La comparaison est restreinte à chaque enregistrement dans chaque bloc.Pour supprimer une colonne de la table Blocking key, cliquez-droit dessus et sélectionnez Delete ou cliquez sur son nom dans la table Data.