
Afficher les résultats du rapprochement
Pourquoi et quand exécuter cette tâche
Pour collecter les doublons du flux d'entrée selon le type de rapprochement défini, Levenshtein et Jaro-Winkler dans cet exemple, procédez comme suit :
Procédure
-
Sauvegardez les paramètres dans l'éditeur d'analyse de rapprochement et appuyez sur la touche F6.
L'analyse est exécutée. La règle de rapprochement et la clé de bloc sont calculées par rapport au jeu de données complet et la vue Analysis Results est ouverte dans l'éditeur.
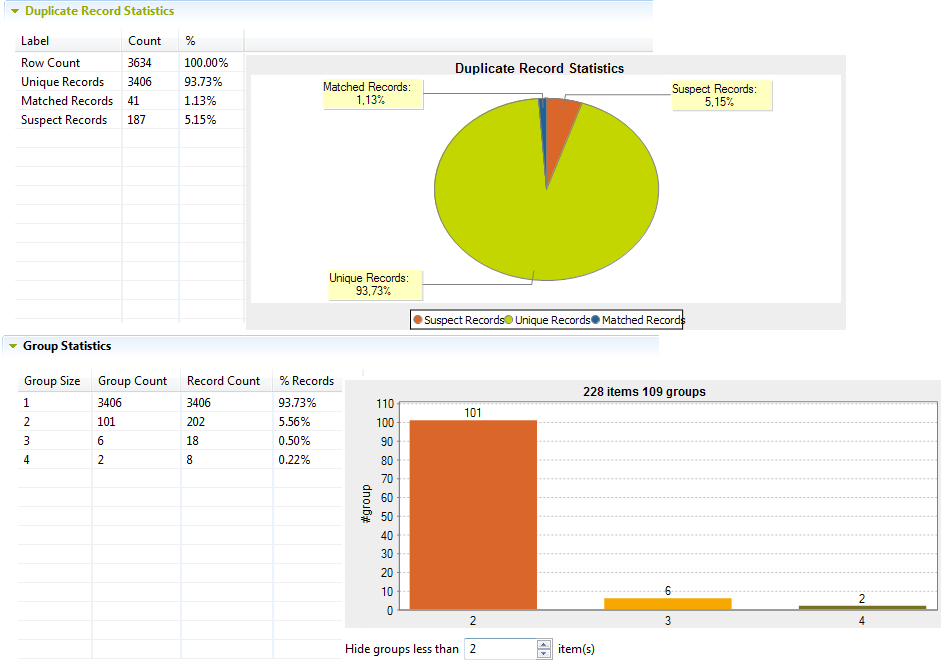 Dans cette vue, le graphique donne une vue d'ensemble concernant les doublons dans les données analysées. Dans la première table, vous pouvez voir les statistiques concernant le nombre d'enregistrements traités, les enregistrements distincts ayant une seule occurrence, les enregistrements en doublon (enregistrements rapprochés) et les enregistrements suspects ne correspondant pas à la règle. Les enregistrements en doublon représentent les enregistrements rapprochés avec un bon score - sous le seuil de confiance. L'un des enregistrement de la paire rapprochée est un doublon et devrait être supprimée, tandis que l'autre est l'enregistrement consolidé.Dans la seconde table, vous pouvez voir les statistiques concernant le nombre de chaque groupe et le nombre d'enregistrements dans chaque groupe. Vous pouvez cliquez sur la colonne de la table de votre choix pour trier les résultats.
Dans cette vue, le graphique donne une vue d'ensemble concernant les doublons dans les données analysées. Dans la première table, vous pouvez voir les statistiques concernant le nombre d'enregistrements traités, les enregistrements distincts ayant une seule occurrence, les enregistrements en doublon (enregistrements rapprochés) et les enregistrements suspects ne correspondant pas à la règle. Les enregistrements en doublon représentent les enregistrements rapprochés avec un bon score - sous le seuil de confiance. L'un des enregistrement de la paire rapprochée est un doublon et devrait être supprimée, tandis que l'autre est l'enregistrement consolidé.Dans la seconde table, vous pouvez voir les statistiques concernant le nombre de chaque groupe et le nombre d'enregistrements dans chaque groupe. Vous pouvez cliquez sur la colonne de la table de votre choix pour trier les résultats.