
Finaliser et exécuter l'analyse de colonnes
Après avoir défini la (les) colonne(s) à analyser et les indicateurs, il se peut que vous vouliez filtrer les données que vous souhaitez analyser et que vous choisissiez le moteur à utiliser pour exécuter l'analyse de colonne(s).
Avant de commencer
- L'analyse de colonnes doit être ouverte dans l'éditeur d'analyse.
- Les indicateurs système ou personnalisés doivent être définis pour l'analyse de colonne.
- Les bibliothèques SQL Explorer requises pour la qualité de données doivent être installées dans le Studio.
Procédure
-
Dans la vue Analysis Parameters, procédez comme suit :

-
Sauvegardez l'analyse et appuyez sur F6 pour l'exécuter.
L'éditeur passe à la vue Analysis Results.Lorsque vous utilisez le moteur SQL, l'analyse exécute de multiples indicateurs en parallèle et les résultats sont rafraîchis dans les graphiques pendant que l'analyse s'exécute.Voici quelques graphiques représentant les indicateurs Frequency Statistics et Text Statistics pour la colonne fullname.
 Pour plus d'informations concernant les statistiques de fréquence et les statistiques de texte, consultez Statistiques avancées et Statistiques de texte, respectivement.Ci-dessous se trouvent les diagrammes représentant la table de fréquence des modèles et la table de basse fréquence des modèles pour la colonne email.
Pour plus d'informations concernant les statistiques de fréquence et les statistiques de texte, consultez Statistiques avancées et Statistiques de texte, respectivement.Ci-dessous se trouvent les diagrammes représentant la table de fréquence des modèles et la table de basse fréquence des modèles pour la colonne email. Dans la table, les modèles utilisent a et A pour représenter les valeurs des e-mails. Chaque modèle peut avoir jusqu'à 30 caractères. Si le nombre total de caractères dépasse 30, le modèle est représenté comme suit : aaaaaAAAAAaaaaaAAAAAaaaaaAAAAA...<nombre total de caractères>.Pour plus d'informations sur ces indicateurs, consultez Statistiques de fréquence des modèles.Ci-dessous, vous pouvez voir les diagrammes représentant le résumé statistique pour la colonne total_sales.
Dans la table, les modèles utilisent a et A pour représenter les valeurs des e-mails. Chaque modèle peut avoir jusqu'à 30 caractères. Si le nombre total de caractères dépasse 30, le modèle est représenté comme suit : aaaaaAAAAAaaaaaAAAAAaaaaaAAAAA...<nombre total de caractères>.Pour plus d'informations sur ces indicateurs, consultez Statistiques de fréquence des modèles.Ci-dessous, vous pouvez voir les diagrammes représentant le résumé statistique pour la colonne total_sales. Pour plus d'informations sur ces indicateurs, consultez Résumé statistique.Ci-dessous, vous pouvez voir les diagrammes représentant l'ordre de grandeur et les statistiques de fréquence de la loi de Benford pour la colonne total_sales.
Pour plus d'informations sur ces indicateurs, consultez Résumé statistique.Ci-dessous, vous pouvez voir les diagrammes représentant l'ordre de grandeur et les statistiques de fréquence de la loi de Benford pour la colonne total_sales. Pour plus d'informations concernant les statistiques de fréquence de la loi de Benford, utilisées comme indicateur dans des listes ou tables afin de détecter la fraude en comptabilité ou dans des dépenses, consultez Détection de la fraude.
Pour plus d'informations concernant les statistiques de fréquence de la loi de Benford, utilisées comme indicateur dans des listes ou tables afin de détecter la fraude en comptabilité ou dans des dépenses, consultez Détection de la fraude.
Résultats
Lorsque vous choisissez le moteur Java, le système cherche des expressions régulières Java.
Si vous exécutez cette analyse à l'aide du moteur SQL, vous pouvez voir la requête exécutée pour chaque indicateur attaché si vous cliquez-droit sur un indicateur et sélectionnez l'option View executed query dans le menu contextuel. Cependant, lorsque vous utilisez le moteur Java, les requêtes SQL ne sont pas accessibles.
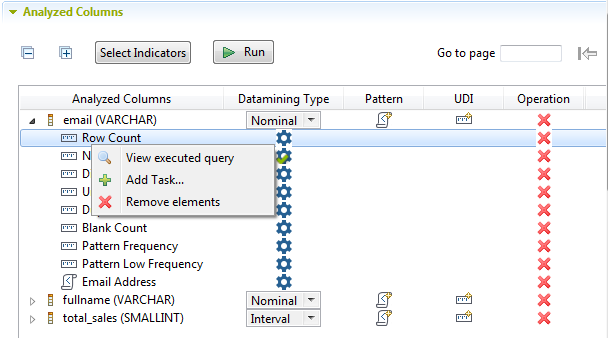
Pour plus d'informations sur le moteur Java, consultez Utiliser le moteur Java ou SQL.