
Nouvelles fonctionnalités
Fonctionnalités partagées
| Fonctionnalité | Description |
|---|---|
| Nouvelle page d'accueil pour le Studio Talend | La page d'accueil du Studio Talend a été modifiée de sorte à offrir une meilleure expérience, plus simple, aux nouveaux utilisateurs comme aux utilisateurs existants. La nouvelle page d'accueil inclut les vignettes suivantes :
Note InformationsConseil : Si vous ne voyez pas la page d'accueil de Bienvenue lors du démarrage, vous pouvez cliquer sur et cocher la case Show welcome page on startup (Afficher la page de bienvenue au démarrage).
 |
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de Databricks 17.3 LTS avec Spark Universal 4.x dans les Jobs Spark Batch | Vous pouvez désormais exécuter vos Jobs Spark Batch sur des clusters de Jobs et des clusters universels Databricks, sur AWS et Azure, à l'aide de Spark Universal avec Spark 4.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec Databricks 17.3 LTS. 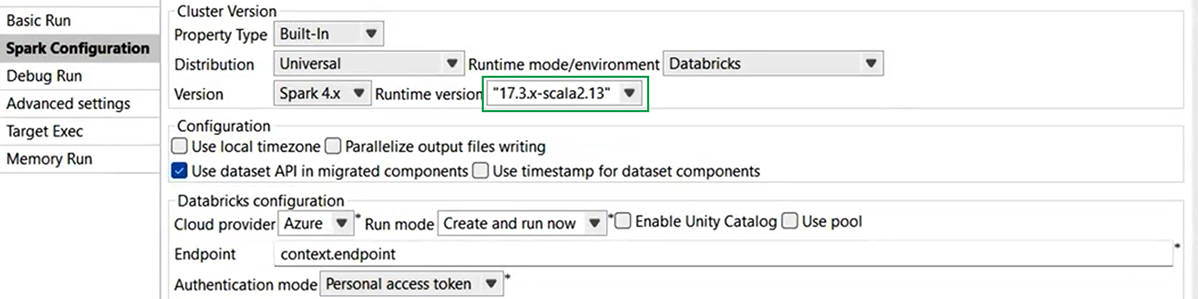 |
Intégration continue
| Fonctionnalité | Description |
|---|---|
|
Mise à niveau du CI Builder (Builder d'intégration continue) Talend à la version 8.0.30 |
Le CI Builder (Builder d'intégration continue) Talend a été mis à niveau à la version 8.0.30 Utilisez le Builder Talend d'intégration continue 8.0.30 dans vos commandes d'intégration continue ou dans vos scripts de pipelines, à partir de cette version mensuelle et jusqu'à la sortie d'une nouvelle version du Builder Talend d'intégration continue. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
| Support d’Amazon RDS pour PostgreSQL avec pgvector pour les composants PostgreSQL dans les Jobs Standards | Les composants PostgreSQL supportent désormais Amazon RDS pour PostgreSQL avec pgvector, ce qui vous permet de stocker et d'interroger des intégrations vectorielles. |
| Support de Microsoft OneLake pour les composants MSSQL et Azure Synapse dans les Jobs Standards | Les composants MSSql et Azure Synapse supportent désormais la lecture de données depuis Microsoft OneLake via le mode d'authentification Azure Active Directory. Changement majeur : Le pilote JDBC Microsoft SQL Server est désormais défini par défaut sur encrypt=true et sur trustServerCertificate=false. Pour les certificats auto-signés, utilisez trustServerCertificate=true ou un TrustStore ; pour les serveurs de test ou de développement non sécurisés, définissez encrypt=false dans les paramètres JDBC supplémentaires. |
| Support des API v3 dans les composants Jira pour supporter Jira Cloud dans les Jobs Standards | Les composants tJIRAInput et tJIRAOutput supportent désormais les API v3 pour Jira Cloud, ce qui améliore la compatibilité avec les opérations Jira Cloud actuelles. |
| Support de l’authentification Kerberos pour le tKafkaCreateTopic dans les Jobs Standards | Le composant tKafkaCreateTopic supporte désormais l'authentification Kerberos, ce qui permet la création de topic en toute sécurité dans les environnements Kafka compatibles avec Kerberos. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
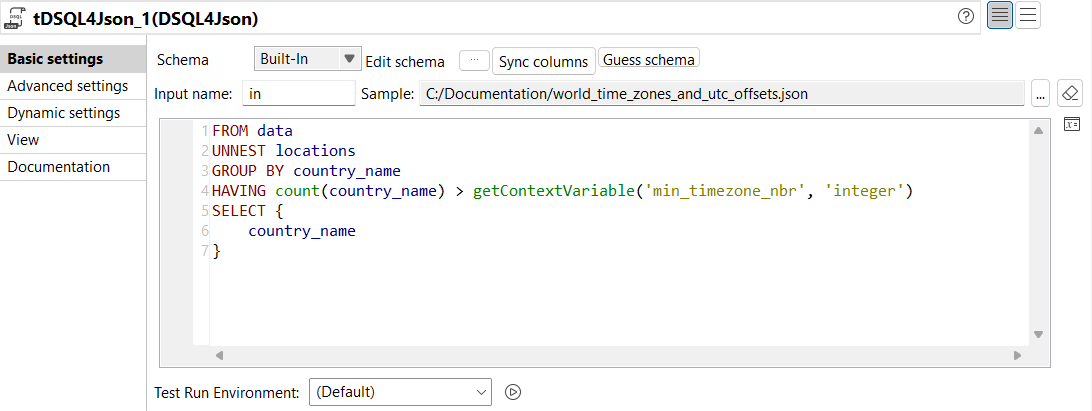
| Nouvel éditeur DSQL pour le composant tDSQL4JSON | Le composant tDSQL4JSON supporte désormais un nouvel éditeur DSQL fournissant les fonctionnalités suivantes :
 |
Qualité de données
| Fonctionnalité | Description |
|---|---|
| Amélioration de l'expérience utilisateur et de l'interface utilisateur de la perspective Profiling | L'expérience utilisateur et l'interface utilisateur de la perspective Profiling ont été améliorées pour offrir une meilleure navigation et une plus grande facilité d'utilisation. |
| Support de la dernière version MySQL 8.x | MySQL a été mis à niveau à la dernière version 8.x. |
| Support de plus d'opérateurs dans le tDQRules | Vous pouvez à présent utiliser les opérateurs suivants dans le composant tDQRules :
|
| Support de Databricks avec Universal Spark 3.x | Vous pouvez désormais exécuter tous les composants DQ sur Databricks avec Universal Spark 3.x. |
| Support d'Apache Spark 4.0 en mode local | Vous pouvez désormais exécuter tous les composants DQ avec Apache Spark 4.0 en mode local. |