
Neue Funktionen
Freigegebene Funktionen
| Funktion | Beschreibung |
|---|---|
| Neue Landing Page für Talend Studio | Die Talend Studio Landing Page wurde neu designt, um eine vereinfachte und verbesserte Erfahrung für neue und vorhandene Benutzer zu bieten. Die neue Landing Page umfasst die folgenden Kacheln:
InformationshinweisTipp: Wenn Ihnen die Landing Page Welcome (Willkommen) beim Start nicht angezeigt wird, können Sie auf klicken und das Kontrollkästchen Show welcome page on startup (Begrüßungsseite beim Start anzeigen) aktivieren.
 |
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für Databricks 17.3 LTS mit Spark Universal 4.x in Spark Batch-Jobs | Sie können Ihre Spark Batch-Jobs jetzt in jobbasierten und in multifunktionalen Databricks-Clustern in AWS und Azure unter Verwendung von Spark Universal mit Spark 4.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Databricks 17.3 LTS kompatibel. 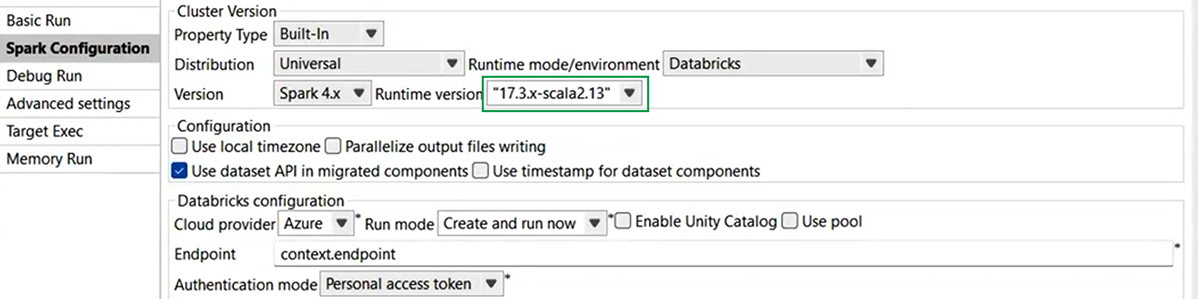 |
Kontinuierliche Integration (CI = Continuous Integration)
| Funktion | Beschreibung |
|---|---|
|
Upgrade von Talend CI Builder auf Version 8.0.30 |
Talend CI Builder wird auf Version 8.0.30 aktualisiert. Verwenden Sie ab dieser monatlichen Version Talend CI Builder 8.0.30 in Ihren CI-Befehlen (Continuous Integration: Kontinuierliche Integration) oder Pipeline-Skripten bis zur Veröffentlichung einer neuen Version von Talend CI Builder. |
Datenintegration
| Funktion | Beschreibung |
|---|---|
| Unterstützung für Amazon RDS für PostgreSQL mit pgvector für PostgreSQL-Komponenten in Standard-Jobs | Die PostgreSQL-Komponenten unterstützen jetzt Amazon RDS für PostgreSQL mit pgvector, sodass Sie Vektor-Einbettungen speichern und abfragen können. |
| Unterstützung für Microsoft OneLake für MSSql und Azure Synapse-Komponenten in Standard-Jobs | Die MSSql- und Azure Synapse-Komponenten unterstützen jetzt das Lesen von Daten aus Microsoft OneLake über den Azure Active Directory-Authentifizierungsmodus. Einschneidende Änderung: Der Microsoft SQL Server JDBC-Treiber wird jetzt standardmäßig auf encrypt=true und trustServerCertificate=false festgelegt. Für selbstsignierte Zertifikate verwenden Sie trustServerCertificate=true oder einen Trust-Store; für nicht sichere Entwicklungs- oder Testserver legen Sie in zusätzlichen JDBC-Parametern encrypt=false fest. |
| Unterstützung für API v3 in Jira-Komponenten zum Unterstützen von Jira Cloud in Standard-Jobs | Die Komponenten tJIRAInput und tJIRAOutput unterstützen jetzt API v3 für Jira Cloud, wodurch die Kompatibilität mit aktuellen Jira Cloud-Vorgängen verbessert wird. |
| Unterstützung für Kerberos-Authentifizierung für tKafkaCreateTopic in Standard-Jobs | Die Komponente tKafkaCreateTopic unterstützt jetzt Kerberos-Authentifizierung, was die sichere Themenerstellung in Kerberos-fähigen Kafka-Umgebungen ermöglicht. |
Data Mapper
| Funktion | Beschreibung |
|---|---|
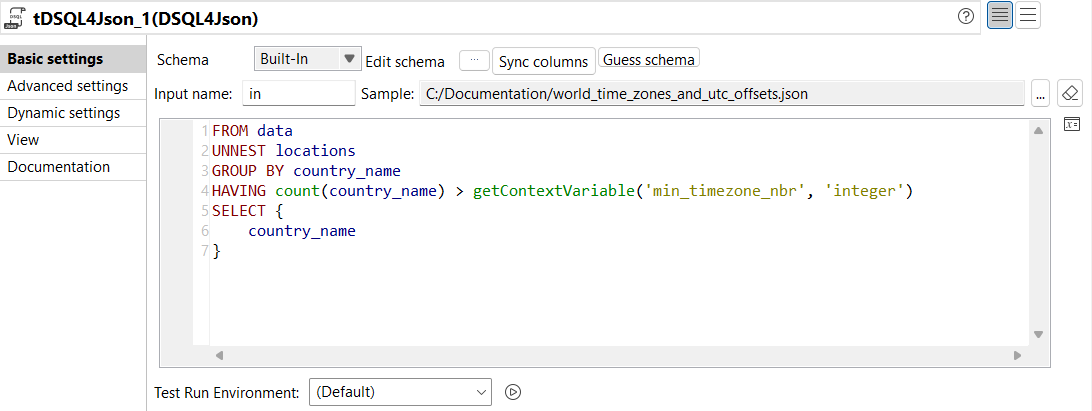
| Neuer DSQL-Editor für die Komponente tDSQL4JSON | Die Komponente tDSQL4JSON unterstützt jetzt einen neuen DSQL-Editor, der Folgendes bietet:
 |
Datenqualität
| Funktion | Beschreibung |
|---|---|
| Verbesserung der Benutzererfahrung und Benutzeroberfläche der Profiling-Perspektive | Die Benutzererfahrung und Benutzeroberfläche der Profiling-Perspektive wurden verbessert und bieten optimierte Navigation und Benutzerfreundlichkeit. |
| Unterstützung der neuesten Version von MySQL 8.x | MySQL wurde auf die neueste Version 8.x aktualisiert. |
| Unterstützung für weitere Operatoren in tDQRules | Sie können jetzt die folgenden Operatoren in der tDQRules-Komponente verwenden:
|
| Unterstützung für Databricks mit Universal Spark 3.x | Sie können jetzt alle DQ-Komponenten in Databricks mit Universal Spark 3.x ausführen. |
| Unterstützung für Apache Spark 4.0 im lokalen Modus | Sie können jetzt alle DQ-Komponenten mit Apache Spark 4.0 im lokalen Modus ausführen. |