Nouvelles fonctionnalités
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de CDP Public Cloud 7.3 avec Spark Universal 3.x (Livy Knox) | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster CDP Public Cloud 7.3, à l'aide de Spark Universal avec Spark 3.x en mode Livy Knox. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop).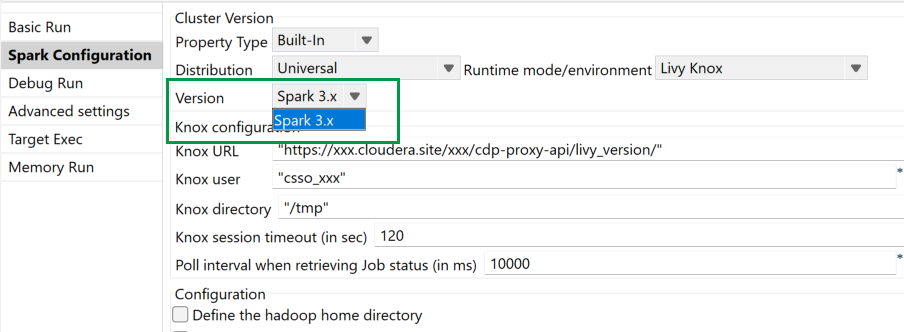 |
| Support de Databricks Unity Catalog dans le composant tIcebergTable | Vous pouvez utiliser Unity Catalog avec les tables gérées dans le composant tIcebergTable.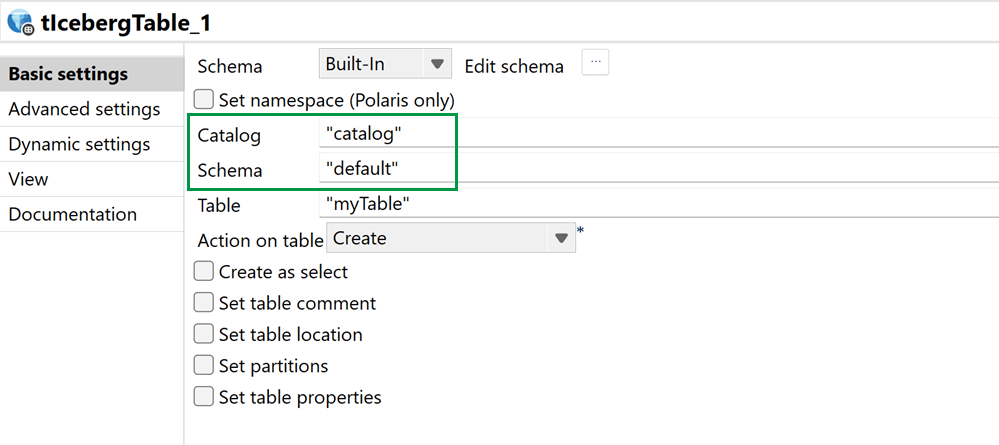 |
| Support de la version 1.17 de Kudu dans les composants Kudu | Vous pouvez à présent utiliser Kudu en version 1.17 dans les composants tKuduConfiguration, tKuduInput et tKuduOutput.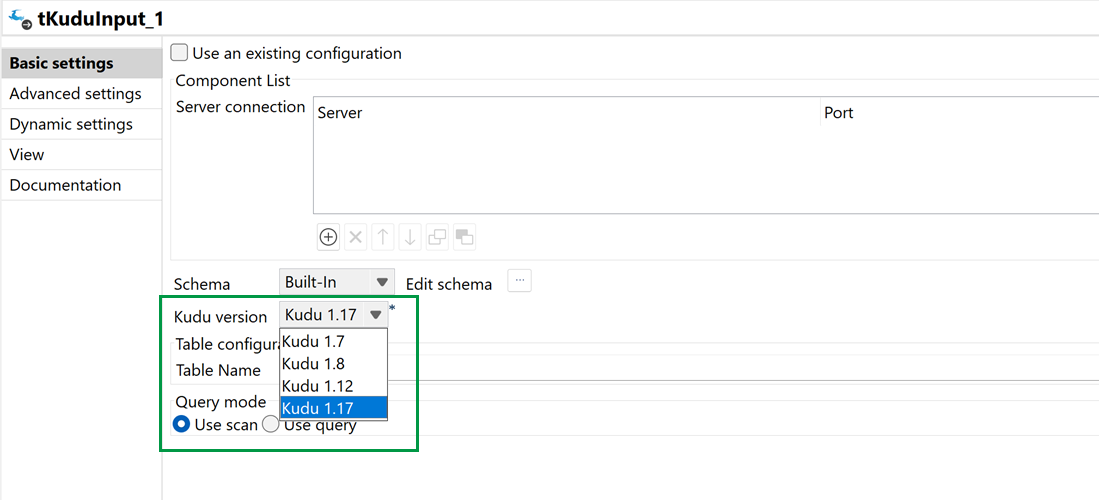 |
Intégration continue
| Fonctionnalité | Description |
|---|---|
|
Mise à niveau du Builder Talend d'intégration continue en version 8.0.26 |
Le Builder Talend d'intégration continue a été mis à niveau, passant de la version 8.0.25 à la version 8.0.26. Utilisez le Builder Talend d'intégration continue 8.0.26 dans vos commandes d'intégration continue ou dans vos scripts de pipelines, à partir de cette version mensuelle et jusqu'à la sortie d'une nouvelle version du Builder Talend d'intégration continue. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
| Nouveau composant tGeminiClient pour Google AI Gemini dans les Jobs Standards |
Le nouveau composant tGeminiClient permet l'intégration avec les modèles d'IA Google Gemini, assurant la connectivité et les interactions avec les services d'IA de Google pour un traitement de données optimisé. |
| Support de Confluent pour les composants Kafka dans les Jobs Standards |
Les composants Kafka supportent à présent Confluent, ce qui vous permet de bénéficier des fonctionnalités spécifiques de Confluent, en plus du support standard d'Apache Kafka. Notez que les tests ont été effectués uniquement avec Confluent Platform, et non avec Confluent Cloud. Pour plus d'informations concernant les versions supportées de Confluent, consultez Confluent Platform and Apache Kafka compatibility (en anglais). |
| Support du protocole HTTP/2 dans le composant tHTTPClient dans les Jobs Standards |
Le composant tHTTPClient a été mis à jour pour supporter le protocole HTTP/2, pour améliorer les performances et une compatibilité moderne avec les API. |
| Support des logs WSDL pour les enveloppes SOAP dans les composants NetSuite dans les Jobs Standards |
Vous pouvez à présent activer les logs WSDL pour les enveloppes SOAP dans les paramètres avancés des composants NetSuite, afin de faciliter la traçabilité et le dépannage. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Support de la transformation récursive hiérarchique vers plate dans l'éditeur de maps DSQL | Vous pouvez à présent aplatir une structure récursive dans l'éditeur de maps DSQL. Cette transformation récursive vers plate ajoute les clauses suivantes :
|
| Support de la fonction CondValidateReport dans toutes les parties d'une expression de validation | Vous pouvez à présent utiliser la fonction CondValidateReport comme racine ou paramètre d'une expression de validation afin de fournir un rapport plus riche d'un problème de validation. |
| Support de la fonction ReadMapInput dans le moteur d'exécution non-Eclipse | La fonction ReadMapInput pour les maps Standards est à présent supportée dans le moteur d'exécution non-Eclipse. |
Qualité de données
| Fonctionnalité | Description |
|---|---|
| Renommage, en anglais, de l'élément d'interface user-defined indicators (indicateurs personnalisés) en custom indicators (indicateurs personnalisés). La traduction française reste inchangée. | Les indicateurs personnalisés user-defined indicators ont été renommés, en anglais, dans l'interface, en custom indicators. La traduction française reste inchangée. La fonctionnalité est la même, seul le nom a changé.
|