Neue Funktionen
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für CDP Public Cloud 7.3 mit Spark Universal 3.x (Livy Knox) | Sie können jetzt Ihre Spark-Jobs in einem CDP Public Cloud 7.3-Cluster unter Verwendung von Spark Universal mit Spark 3.x im Livy Knox-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung).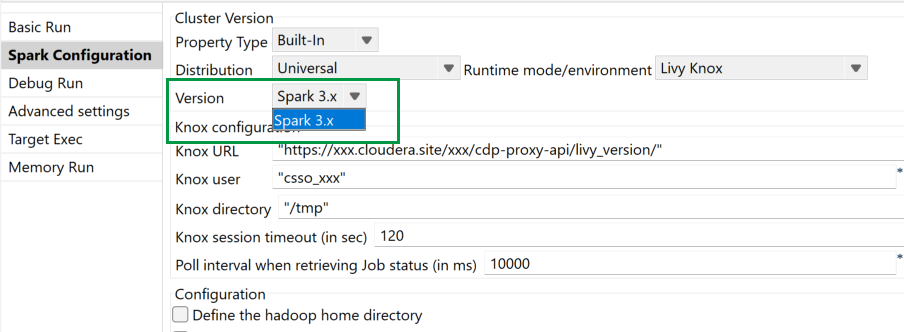 |
| Unterstützung für Databricks Unity Catalog in tIcebergTable | Sie können Unity Catalog jetzt verwenden, um mit verwalteten Tabellen in der Komponente „tIcebergTable“ zu arbeiten.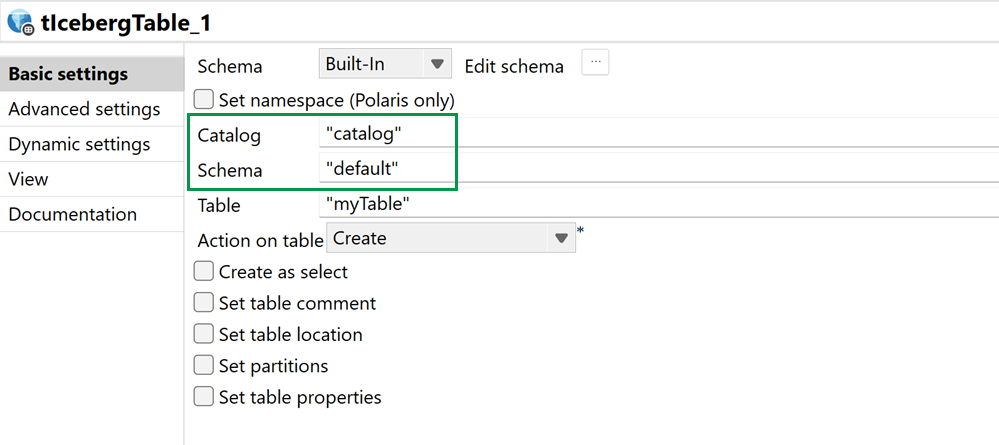 |
| Unterstützung für Kudu Version 1.17 in den Kudu-Komponenten | Sie können jetzt mit Version 1.17 in den Komponenten „tKuduConfiguration“, „tKuduInput“ und „tKuduOutput“ arbeiten.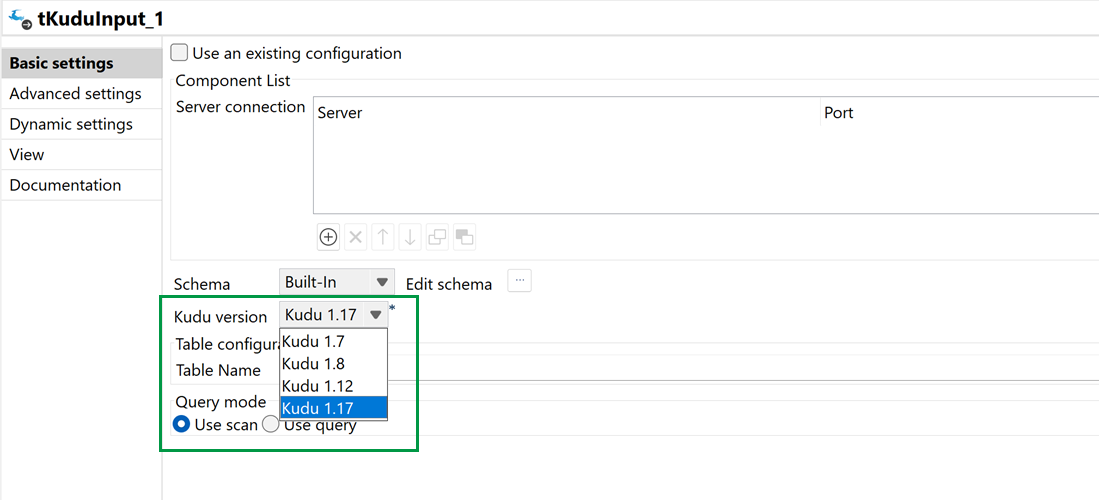 |
Kontinuierliche Integration (CI = Continuous Integration)
| Funktion | Beschreibung |
|---|---|
|
Upgrade von Talend CI Builder auf Version 8.0.26 |
Talend CI Builder wurde von Version 8.0.25 auf Version 8.0.26 aktualisiert. Verwenden Sie ab dieser monatlichen Version Talend CI Builder 8.0.26 in Ihren CI-Befehlen (Continuous Integration: Kontinuierliche Integration) oder Pipeline-Skripten bis zur Veröffentlichung einer neuen Version von Talend CI Builder. |
Datenintegration
| Funktion | Beschreibung |
|---|---|
| Neue Komponente „tGeminiClient“ für Google-KI Gemini in Standard-Jobs |
Die neue Komponente „tGeminiClient“ ermöglicht die Integration in KI-Modelle von Google Gemini, was die Verbindung und Interaktion mit den KI-Diensten von Google und erweiterte Datenverarbeitung ermöglicht. |
| Unterstützung für „Confluent for Kafka“-Komponenten in Standard-Jobs |
Die Kafka-Komponenten unterstützen jetzt Confluent. Damit können Sie Confluent-spezifische Funktionen zusätzlich zur Standard-Unterstützung für Apache Kafka nutzen. Beachten Sie, dass die Tests nur auf der Confluent Platform durchgeführt wurden, nicht mit Confluent Cloud. Weitere Informationen zu den unterstützten Confluent-Versionen finden Sie unter Confluent Platform and Apache Kafka compatibility. |
| Unterstützung für HTTP/2-Protokoll für die Komponente „tHTTPClient“ in Standard-Jobs |
Die Komponente „tHTTPClient“ wurde aktualisiert und unterstützt jetzt das HTTP/2-Protokoll, was für bessere Leistung und Kompatibilität mit modernen APIs sorgt. |
| Unterstützung für WSDL-Protokollierung für SOAP Envelopes für NetSuite-Komponenten in Standard-Jobs |
Sie können jetzt WSDL-Protokollierung für SOAP Envelopes in den erweiterten Einstellungen der NetSuite-Komponenten aktivieren, um die Nachverfolgbarkeit und Fehlerbehebung zu vereinfachen. |
Data Mapper
| Funktion | Beschreibung |
|---|---|
| Unterstützung der Umwandlung von hierarchisch rekursiv zu flach im DSQL-Map-Editor | Sie können jetzt die rekursive Struktur im DSQL-Map-Editor abflachen. Mit dieser Umwandlung von rekursiv zu flach werden die folgenden neuen Befehle eingeführt:
|
| Unterstützung der Funktion „CondValidateReport“ in allen Teilen eines Validierungsausdrucks | Sie können die Funktion „CondValidateReport“ jetzt entweder als Root oder als Parameter eines Validierungsausdrucks verwenden, um umfangreichere Berichte zu einem Validierungsproblem bereitzustellen. |
| Unterstützung für die Funktion „ReadMapInput“ in der Nicht-Eclipse-Laufzeit | Die Funktion „ReadMapInput“ für Standard-Map wird jetzt in der Nicht-Eclipse-Laufzeit unterstützt. |
Datenqualität
| Funktion | Beschreibung |
|---|---|
| Benutzerdefinierte Indikatoren wurden in angepasste Indikatoren umbenannt | Die benutzerdefinierten Indikatoren (UDI) wurden in der Benutzeroberfläche in angepasste Indikatoren umbenannt. Die Funktion ist die gleiche, nur der Name wurde geändert
|