新しい機能
ビッグデータ
| 機能 | 説明 |
|---|---|
| Spark Universal 3.x (Livy Knox)を使用したCDP Public Cloud 7.3のサポート | Livy KnoxモードのSpark 3.xを搭載したSpark Universalを使用して、CDPパブリッククラウド7.3クラスターでSparkジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。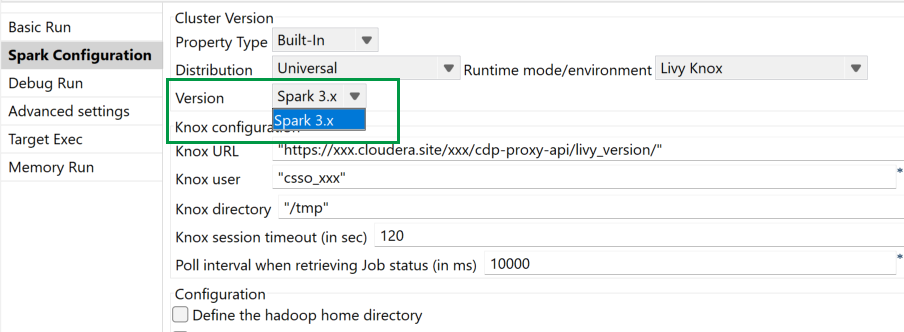 |
| tIcebergTableでのDatabricks Unity Catalogのサポート | Unity Catalogを使用して、tIcebergTableコンポーネント内の管理テーブルを操作できるようになりました。![tIcebergTableコンポーネントの基本設定タブで使用できる[カタログ]および[スキーマ]パラメーター。](/talend/ja-JP/release-notes/8.0/Content/Resources/images/unity-catalog-ticebergtable-component.png) |
| KuduコンポーネントにおけるKuduバージョン1.17のサポート | tKuduConfiguration、tKuduInput、tKuduOutputコンポーネントで、Kuduバージョン 1.17を使用できるようになりました。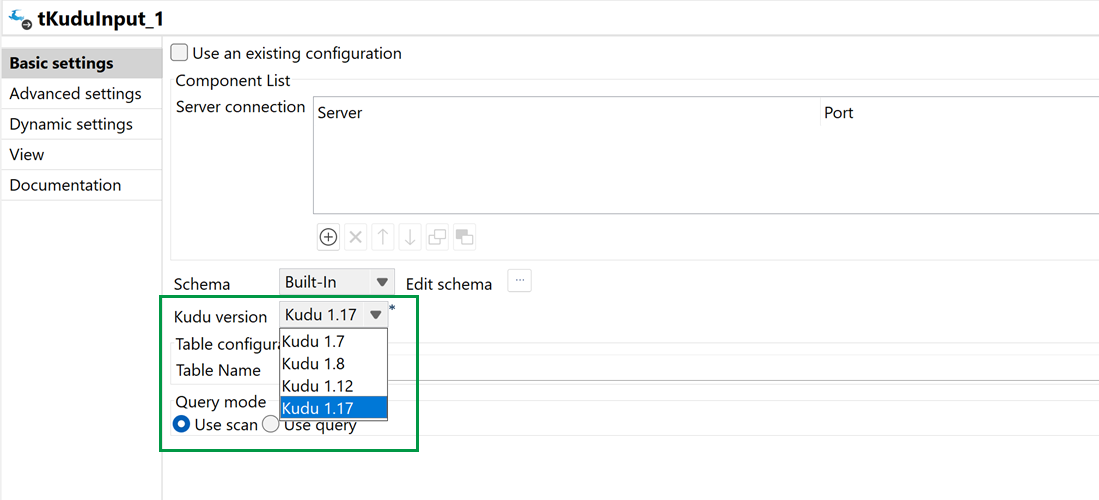 |
継続的インテグレーション
| 機能 | 説明 |
|---|---|
|
Talend CI Builderをバージョン8.0.26にアップグレード |
Talend CI Builderのバージョンが8.0.25 から8.0.26にアップグレードされました。 このマンスリーバージョン以降、Talend CI Builderの新しいバージョンがリリースされるまでCIコマンドやパイプラインスクリプトでTalend CI Builder 8.0.26を使用します。 |
データ統合
| 機能 | 説明 |
|---|---|
| 標準ジョブにおけるGoogle AI Geminiの新しいtGeminiClientコンポーネント |
新しいtGeminiClientコンポーネントにより、Google Gemini AIモデルとの統合が可能になり、GoogleのAIサービスとの接続と対話が可能になり、データ処理が強化されます。 |
| 標準ジョブにおけるKafkaコンポーネントのConfluentのサポート |
KafkaコンポーネントはConfluentをサポートするようになり、標準のApache Kafkaサポートに加えてConfluent固有の機能を活用できるようになりました。テストはConfluent CloudではなくConfluent Platformでのみ実行されていることに注意してください。サポートされているConfluentバージョンの詳細については、Confluent Platform and Apache Kafka compatibilityを参照してください。 |
| 標準ジョブにおけるtHTTPClientコンポーネントのHTTP/2プロトコルのサポート |
tHTTPClientコンポーネントはHTTP/2プロトコルをサポートするように更新され、パフォーマンスの向上と最新のAPI互換性が実現されています。 |
| 標準ジョブにおけるNetSuiteコンポーネントのSOAPエンベロープのWSDLロギングのサポート |
追跡可能性とトラブルシューティングを容易にするために、NetSuiteコンポーネントの詳細設定でSOAPエンベロープのWSDLログを有効にできるようになりました。 |
Data Mapper
| 機能 | 説明 |
|---|---|
| DSQLマップエディターにおける階層型再帰からフラットへの変換のサポート | DSQLマップ エディターで再帰構造をフラット化できるようになりました。この再帰からフラットへの変換では、次の新しい句が導入されます。
|
| 検証式の任意の部分でのCondValidateReport関数のサポート | CondValidateReport関数を検証式のルートまたはパラメーターとして使用して、検証の問題に関するより詳細なレポートを提供できるようになりました。 |
| Eclipse以外のランタイムでのReadMapInput関数のサポート | 標準マップのReadMapInput関数が、Eclipse以外のランタイムでサポートされるようになりました。 |
データクオリティ
| 機能 | 説明 |
|---|---|
| ユーザー定義インジケーターの名前をカスタムインジケーターに変更する | ユーザー定義インジケーター(UDI)の名前がUI上のカスタムインジケーターに変更されました。機能はそのままで、名称のみが変更されました。
|