
Nouvelles fonctionnalités
Fonctionnalités partagées
| Fonctionnalité | Description |
|---|---|
| Modification de la couleur de fond des sous-Jobs et Joblets par défaut dans l’espace de modélisation graphique | Les sous-Jobs et Joblets sont à présent encadrés dans un rectangle bleu par défaut. Vous pouvez modifier ou supprimer la couleur de fond d'un sous-Job ou Joblet en fonction de vos besoins. |
| Nouveaux modes Select (Sélection) et Move (Déplacement) pour la navigation dans l’espace de modélisation graphique | Le Studio Talend fournit à présent les modes Select (Sélection) et Move (Déplacement) dans l'éditeur graphique des Jobs, Joblets, Routes et Routelets. Pour plus d'informations, consultez Naviguer dans l'espace de modélisation graphique. |
| Support de davantage de composants pour le lignage des Jobs | Le Studio Talend peut à présent générer des jeux de données et des lignages pour davantage de composants dans Qlik Cloud. |
Intégration d'application
| Fonctionnalité | Description |
|---|---|
| Support de l’activation de l’endpoint Prometheus par configuration du microservice | Vous pouvez à présent utiliser le paramètre management.endpoint.prometheus.enabled=true/false dans un fichier de propriétés supplémentaire pour activer ou désactiver l'endpoint Prometheus pour un microservice. Pour plus d'informations, consultez Exécuter un microservice. |
| Support des options Batch Consumer (Consommateur du lot) et de partitionnement dans le composant cKafkaCommit | Le composant cKafkaCommit supporte à présent l'option Batch Consumer (Consommateur du lot) et l'utilisation des partitions. |
| Affichage de la structure des dossiers des définitions d'API dans l'assistant d'import d'API | Lorsque vous importez une définition d'API depuis Talend Cloud API Designer, l'assistant d'import d'API reflète à présent la structure des dossiers dans Talend Cloud API Designer. Pour plus d'informations, consultez Créer une nouvelle métadonnée d'API REST depuis API Designer.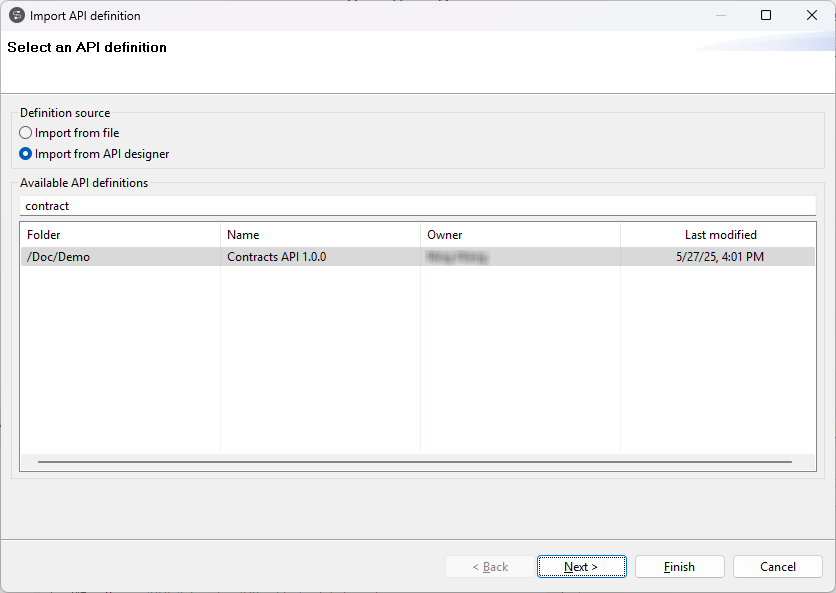 |
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de CDP Private Cloud Base 7.1.7 avec Spark Universal 3.3.x | Le Studio Talend supporte à présent CDP Private Cloud Base 7.1.7 (Spark 3.2) SP1 avec JDK 11, avec Spark Universal 3.3.x dans les Jobs Spark Batch et Standards. |
| Nouveau composant tIcebergSQL dans les Jobs Spark Batch |
Le nouveau composant tIcebergSQL est à présent disponible en version bêta dans les Jobs Spark Batch, vous permettant d'exécuter des requêtes SQL sur des tables Iceberg gérées par Polaris et Snowflake Open Catalog. 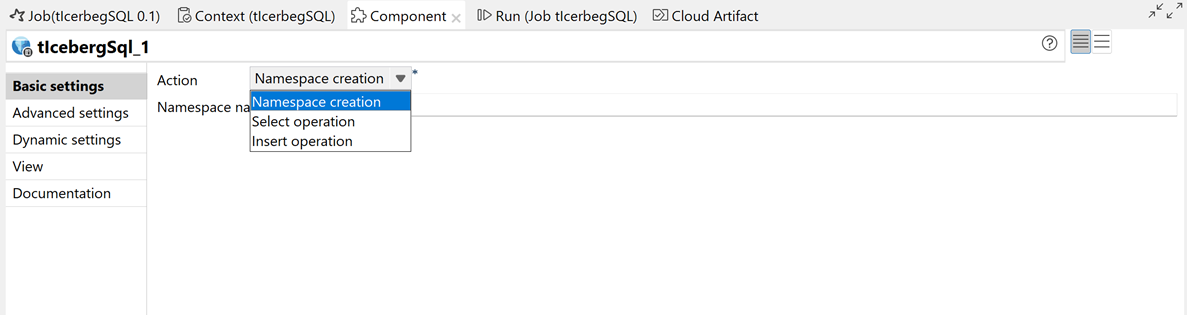 |
| Support de Hive 3 dans les composants Impala | Le Studio Talend supporte à présent Hive 3 dans les composants Impala, dans les Jobs Standards. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
|
Nouveau composant tQVDOutput dans les Jobs Standards |
Le nouveau composant tQVDOutput est à présent disponible dans les Jobs Standards et vous permet de créer des fichiers QVD. |
|
Nouvelles options de partition dans le composant tKafkaInput dans les Jobs Standards |
L'option Use offset partition (Utiliser l'offset de partition) a été ajoutée au composant tKafkaInput, vous permettant de spécifier la partition depuis laquelle lire les données et de spécifier l'offset de départ pour la récupération des messages. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Support de l’opérateur EXISTS dans les maps DSQL | L'opérateur EXISTS, à présent disponible dans les maps DSQL, vous permet de vérifier qu'un argument n'est pas vide ou null. L'argument peut être un tableau, un enregistrement, un primitif, un choix ou une map. |
| Support des opérations arithmétiques entre les opérandes de chaînes de caractères représentant des nombres | Les opérations arithmétiques comme '2' + '1' sont à présent calculées et supportées comme opérandes de chaînes de caractères numériques. |
| Support des expressions paramétrées complexes dans les maps DSQL | Le Studio Talend supporte à présent les expressions paramétrées complexes dans l'éditeur de maps DSQL. Vous pouvez à présent utiliser un bloc dans une expression paramétrée :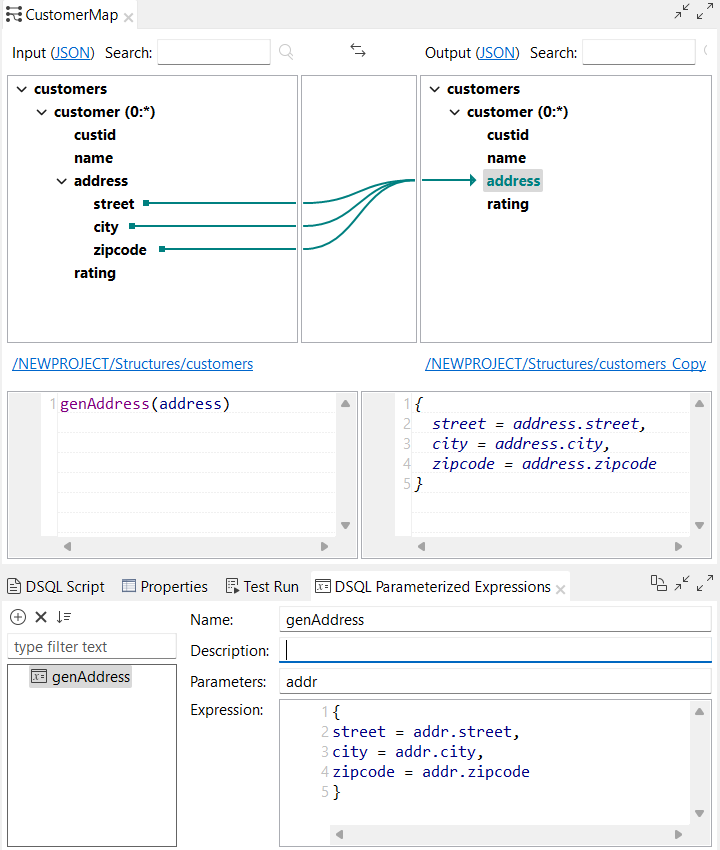 Vous pouvez à présent utiliser un bloc dans une expression paramétrée :
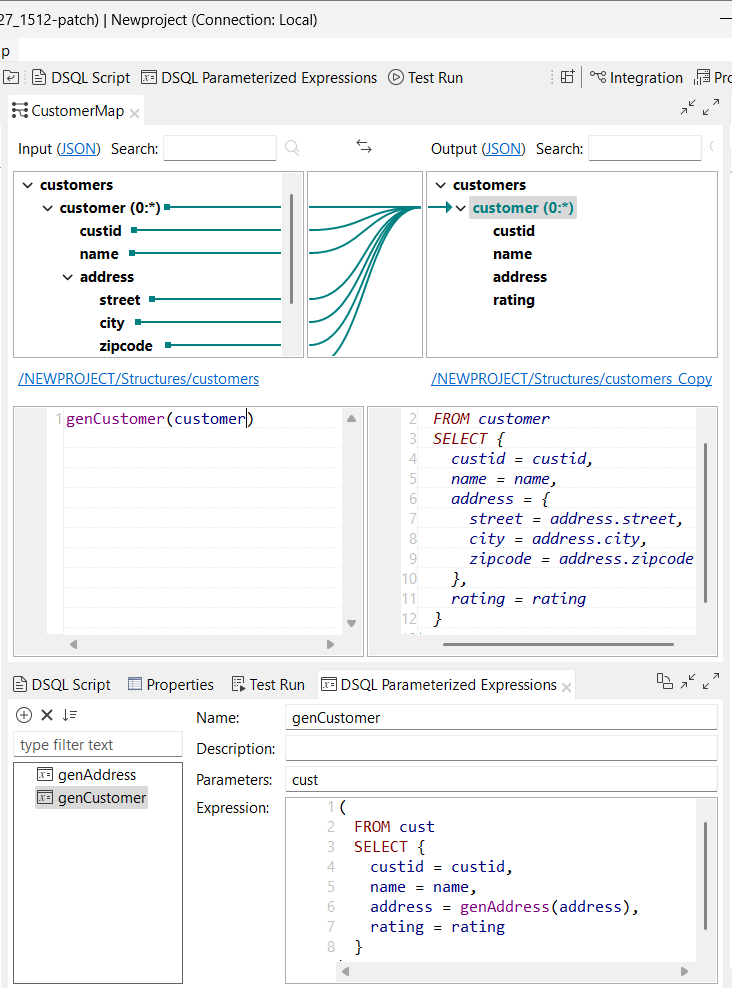 |
| Nouvelles options permettant de copier-coller des expressions dans les maps DSQL | Vous avez à présent la possibilité de copier-coller des expressions lorsque vous cliquez-droit sur un élément de sortie dans l'éditeur de map DSQL.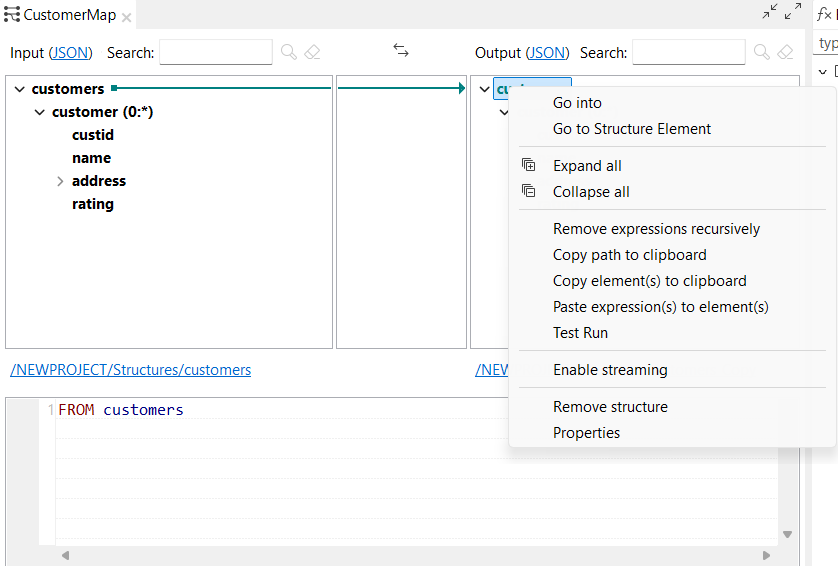 |
| Support de la valeur d’index de départ personnalisée dans les requêtes dans les maps DSQL | Vous pouvez à présent utiliser une valeur d'index de départ personnalisée dans vos requêtes, dans les maps DSQL, en définissent une expression après le mot-clé INDEX. Par exemple, vous pouvez définir votre index pour qu'il commence à 1 : |
| Support de l’opérateur NOT devant les expressions conditionnelles dans les maps DSQL | Les opérateurs NOT et ! peuvent à présent être suivis par une expression conditionnelle : |
Qualité de données
| Fonctionnalité | Description |
|---|---|
| Support de nouvelles méthodes d'authentification pour la connexion à Snowflake | Lorsque vous vous connectez à Snowflake comme connexion à une base de données dans le référentiel, vous pouvez à présent utiliser la méthode d'authentification par paire de clés et la méthode d'authentification par OAuth 2.0. |