
Neue Funktionen
Freigegebene Funktionen
| Funktion | Beschreibung |
|---|---|
| Änderung der Standard-Hintergrundfarbe für subJobs und Joblets auf der Arbeitsfläche | SubJobs und Joblets sind jetzt standardmäßig in einem blauen Quadrat hervorgehoben. Sie können die Hintergrundfarbei eines subJob oder Joblet nach Bedarf ändern oder entfernen. |
| Neue Modi „Auswählen“ und „Verschieben“ für die Arbeitsbereichsnavigation | Talend Studio stellt jetzt die Modi „Auswählen“ und „Verschieben“ für den grafischen Editor von Job, Joblet, Route und Routelet bereit. Weitere Informationen finden Sie unter Navigieren im Arbeitsbereich. |
| Unterstützung weiterer Komponenten für Job-Herkunft | Talend Studio kann jetzt Datensätze und Herkunft für weitere Komponenten in Qlik Cloud generieren. |
Anwendungsintegration
| Funktion | Beschreibung |
|---|---|
| Unterstützung der Prometheus-Endpunktaktivierung über Microservice-Konfiguration | Sie können jetzt den Parameter management.endpoint.prometheus.enabled=true/false in einer zusätzlichen Eigenschaftendatei verwenden, um den Prometheus-Endpunkt für einen Microservice zu aktivieren oder zu deaktivieren. Weitere Informationen finden Sie unter Ausführen eines Microservice. |
| Unterstützung für Batch-Nutzer und Partitionierung in der cKafkaCommit-Komponente | cKafkaCommit unterstützt jetzt Batch-Nutzer und die Verwendung von Partitionen. |
| Anzeigen der Ordnerstruktur von API-Definitionen im API-Importassistenten | Beim Importieren einer API-Definition aus Talend Cloud API Designer übernimmt der API-Importassistent jetzt die Ordnerstruktur von Talend Cloud API Designer. Weitere Informationen finden Sie unter Erstellen neuer REST API-Metadaten über API Designer.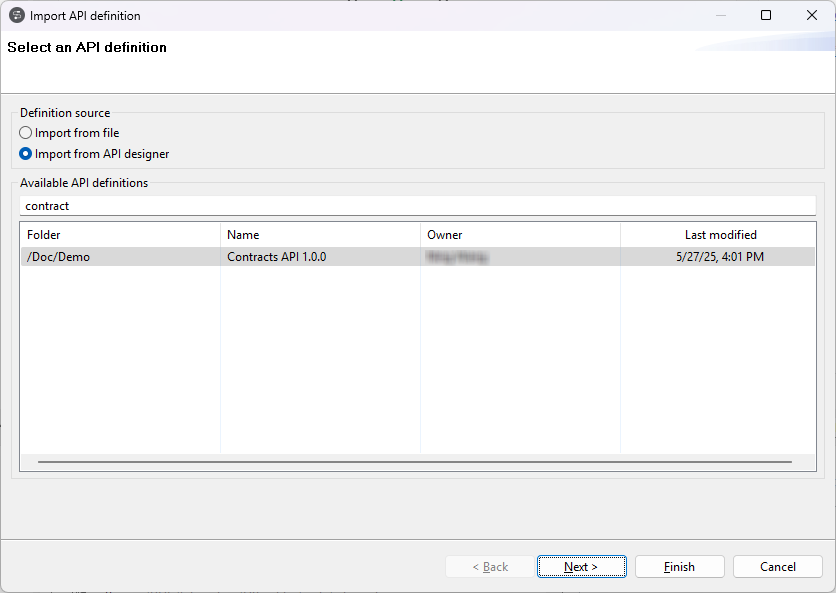 |
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für CDP Private Cloud Base 7.1.7 mit Spark Universal 3.3.x | Talend Studio unterstützt jetzt CDP Private Cloud Base 7.1.7 (Spark 3.2) SP1 mit JDK 11 mit Spark Universal 3.3.x in Spark-Batch-Aufträgen und -Standard-Jobs. |
| Neue tIcebergSQL-Komponente in Spark-Batch-Aufträgen |
Die neue tIcebergSQL-Komponente ist jetzt in der Beta-Version in Spark-Batch-Aufträgen verfügbar. Damit können Sie SQL-Abfragen für in Polaris und Snowflake Open Catalog verwaltete Iceberg-Tabellen ausführen. 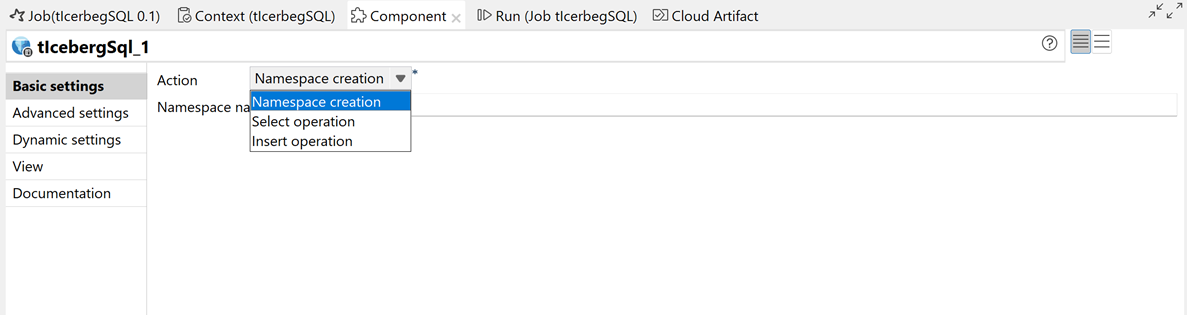 |
| Unterstützung für Hive 3 in Impala-Komponenten | Talend Studio unterstützt jetzt Hive 3 in Impala-Komponenten in Standard-Jobs. |
Datenintegration
| Funktion | Beschreibung |
|---|---|
|
Neue tQVDOutput-Komponente in Standard-Jobs |
Die neue tQVDOutput-Komponente ist jetzt in Standard-Jobs verfügbar. Damit können QVD-Dateien erstellt werden. |
|
Neue Partitionsoptionen in tKafkaInput in Standard-Jobs |
Die Option Use offset partition (Offset-Partition verwenden) wurde in tKafkaInput hinzugefügt. Damit können Sie die Partition angeben, aus der gelesen werden soll, und den Start-Offset zum Abrufen von Nachrichten definieren. |
Data Mapper
| Funktion | Beschreibung |
|---|---|
| Unterstützung für den Operator EXISTS in DSQL-Maps | Der Operator EXISTS ist jetzt in DSQL-Maps verfügbar, wo Sie prüfen können, ob ein Argument nicht leer oder null ist. Das Argument kann ein Array, ein Datensatz, ein Primitiv, eine Option oder eine Map sein. |
| Unterstützung für arithmetische Operation zwischen Zeichenfolgen-Operanden, die Zahlen darstellen | Arithmetische Operationen wie '2' + '1' werden jetzt als numerische Zeichenfolgen-Operanden berechnet und unterstützt. |
| Unterstützung für komplexe parametrisierte Ausdrücke in DSQL-Maps | Talend Studio unterstützt jetzt komplexe parametrisierte Ausdrücke im DSQL-Maps-Editor. Sie können jetzt einen Block in einem parametrisierten Ausdruck verwenden: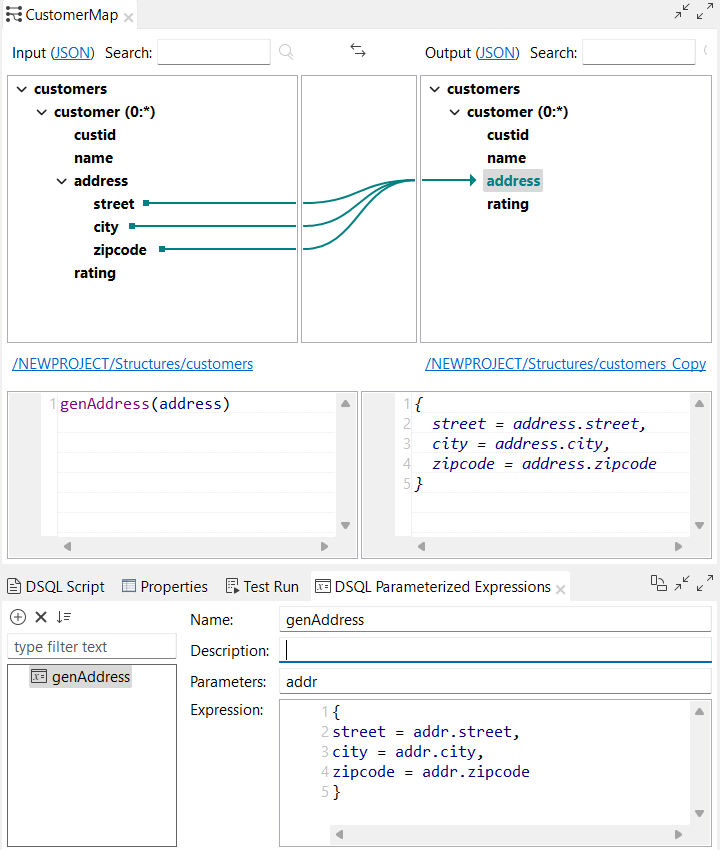 Sie können jetzt auch eine Abfrage in einem parametrisierten Ausdruck verwenden:
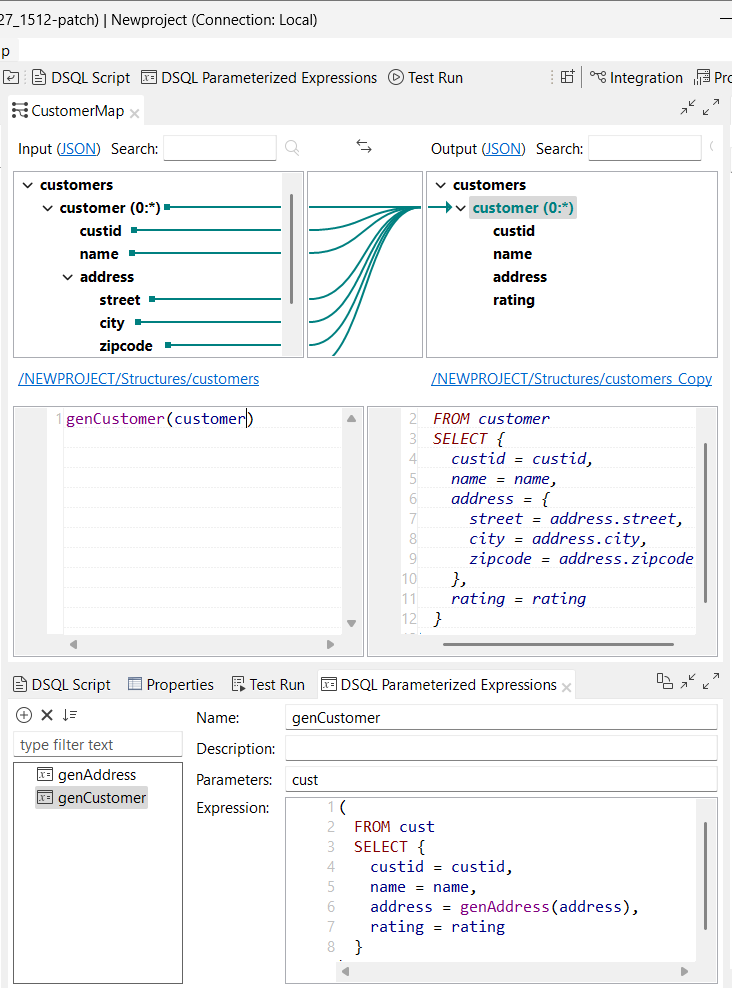 |
| Neue Optionen zum Kopieren und Einfügen von Ausdrücken in DSQL-Maps | Sie haben jetzt die Möglichkeit, Ausdrücke zu kopieren und einzufügen, wenn Sie mit der rechten Maustaste auf ein Ausgabeelement im DSQL-Map-Editor klicken.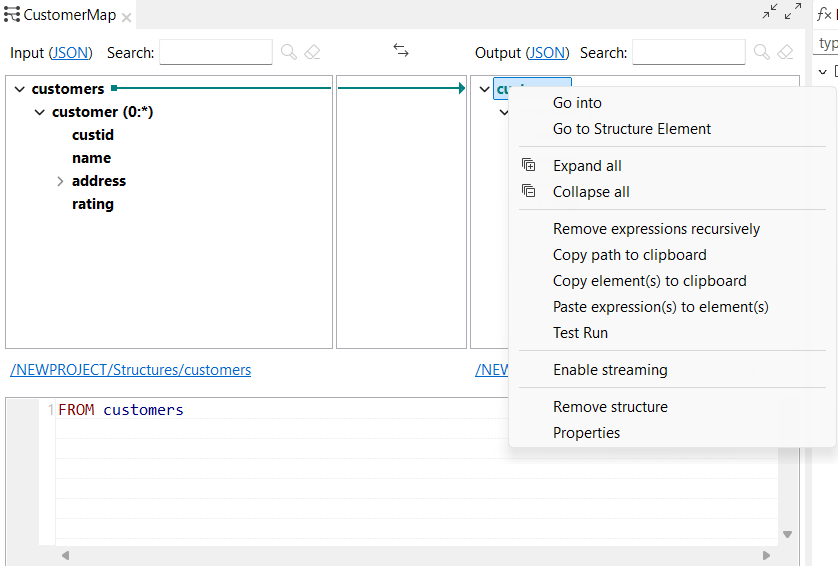 |
| Unterstützung für einen benutzerdefinierten Start-Indexwert in Abfragen in DSQL-Maps | Sie können jetzt einen benutzerdefinierten Start-Indexwert in Ihren Abfragen in DSQL-Maps verwenden, indem Sie einen Ausdruck nach dem Schlüsselwort INDEX definieren. Beispielsweise können Sie Ihren Index so definieren, dass er bei 1 beginnt: |
| Unterstützung für den NOT-Operator vor bedingten Ausdrücken in DSQL-Maps | Die Operatoren NOT und ! können jetzt von einem bedingten Ausdruck gefolgt sein: |
Datenqualität
| Funktion | Beschreibung |
|---|---|
| Unterstützung für neue Authentifizierungsmethoden für die Snowflake-Verbindung | Wenn Sie eine Verbindung mit Snowflake als Datenbankverbindung im Repository herstellen, können Sie jetzt die Schlüssel-Paar- und OAuth 2.0-Authentifizierungsmethoden verwenden. |