
Gérer des en-têtes dynamiques dans un format de log étendu W3C à l'aide d'un tJavaFlex
| Version | Toutes les versions plateformes et entreprises actuellement supportées (Jobs Data Integration Batch) |
Environnement
- Cet article a été écrit avec Talend Studio for Data Integration 6.3.1 (Enterprise). C'est pour cela que les Jobs joints ne peuvent être importés que dans les versions 6.3.1 et ultérieures de Talend.
- Le composant tJavaFlex est disponible dans toutes les versions supportées actuellement du Studio Talend.
Format de log étendu W3C
Conformément à W3C, le format de log étendu contient deux types de lignes, directives (en-tête) et entrées (données). Chaque ligne d'entrée contient une liste de champs, alors que les lignes directives contiennent des métadonnées concernant le log lui-même. Les lignes directives Fields contiennent spécifiquement la liste des champs qui devront être parsés pour lire les données de log dans les entrées de ligne.
Voici un exemple de log. La troisième ligne est la ligne directive Fields. Notez que les champs dans un log W3C sont séparés par un espace.
Numéro de version : 1.0
Date : 2001-05-02 17:42:15
#Champs : time cs-method cs-uri-stem sc-status cs-version
17:42:15 GET /default.htm 200 HTTP/1.0
17:42:15 GET /default.htm 200 HTTP/1.0
Solution
Comme le champ et les valeurs sont séparés par un espace, il est possible de lire le fichier ci-dessus à l'aide d'un composant tFileInputDelimited. Le composant doit être configuré pour ignorer les trois premières lignes, et lire les entrées de ligne avec un espace comme séparateur de champs. Toutefois, le problème avec cette solution est qu'elle ne s'adapte pas dynamiquement pour garantir que les bonnes colonnes sont mappées dans les bons champs, si l'administrateur modifie l'ordre des champs écrits en sortie dans le log, ou les renomme. L'objectif est de toujours mapper les champs corrects même si l'administrateur informatique modifie l'ordre ou le nom des champs écrits en sortie par le log. C'est la raison pour laquelle la solution suivante est conçue pour lire et mapper les champs connus, tout en ignorant les champs nouveaux et inconnus. Les champs existants supprimés de la définition enverront les valeurs nulles dans votre Job.
La solution est d'utiliser le tJavaFlex pour mapper correctement les champs. Il faut donc :
- Trouver les lignes directives Fields, lues dans la liste de champs.
- Lire les entrées de log ligne par ligne.
- Parser les entrées de log.
- Mapper les champs des entrées de log vers les champs définis dans le schéma. Les champs nouveaux, inconnus et manquants seront ignorés. La solution effectuera également tout parsing de type de données nécessaire.
Fonctionnement du tJavaFlex
Le tJavaFlex permet au développeur de saisir du code personnalisé afin de l'intégrer dans un Job Talend Data Integration. Avec le tJavaFlex, vous pouvez saisir les trois différentes parties du code Java (de début, principal et de fin) constituant un composant qui permet d'exécuter une opération souhaitée. En codant les trois parties (de début, principal et de fin) correctement, Talend assure que la logique se comporte comme souhaité au sein du flux de données d'un sous-Job. Veuillez vous référer à la documentation du composant pour obtenir plus d'informations concernant le tJavaFlex.
Créer un Job
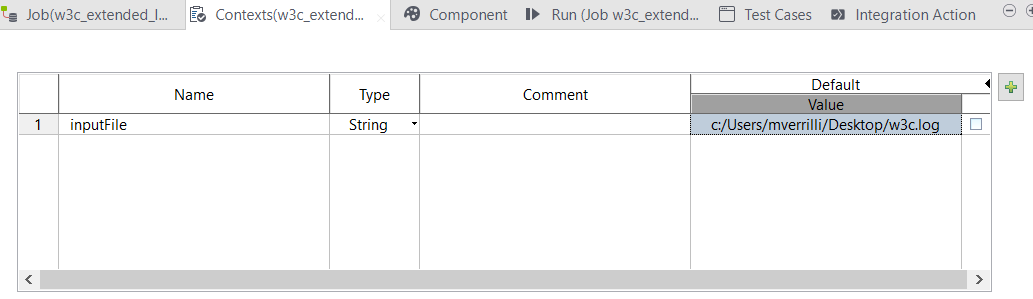
Créez un Job comme montré ci-dessous avec les composants tJavaFlex et tLogRow.

Créez une variable de contexte inputFile afin de référencer le chemin du fichier d'entrée. La variable de contexte sera utilisée dans le code du composant tJavaFlex.
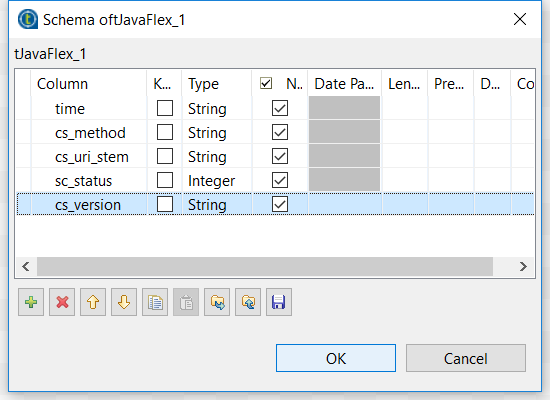
Définir le schéma
Dans cet exemple, intéressez-vous à ces champs : time cs-method cs-uri-stem sc-status cs-version . Comme les noms des champs du schéma sont conformes aux standards de Talend et ne peuvent contenir de tiret dans l'éditeur du schéma dans Talend, le tiret sera remplacé par un tiret bas. Le nom n'a pas besoin de correspondre puisque le mapping surviendra dans la section Main du composant tJavaFlex. Notez que seuls les champs qui seront extraits des entrées de log seront mappés, afin d'optimiser la logique. C'est la bonne pratique pour la création de Jobs d'intégration de données. Aussi, seules les données nécessaires dans la mémoire sont manipulées et chargées.
Configurer le composant tJavaFlex
Tout d'abord, définissez le code de début. Des commentaires en ligne expliquent cette procédure en détail, toutefois, notez que la variable de contexte inputFile est utilisée pour le chemin d'accès au fichier.
Pour résumer :
- Déclarez les variables.
- Ouvrez le fichier à l'aide d'un BufferedReader.
- Scannez les directives pour Fields et parsez la liste en tableau.
- Commencez la boucle pour traiter les lignes de données.
Code de début
// In order to add new fields not currently supported,
// simply add the field to this component's schema,
// then at the switch statement in the main code,
// add the relevant mapping and data type conversion
// if required.
// input file is set via context variable
String file = context.inputFile;
// Raw line from file before being parsed
String line = "";
// Split line variable for parsed data
String[] parts;
// List of fields
String[] fieldList = {};
// lineCount to assist in case a specific line causea an exception
Long lineCount = new Long(0);
// errorLineCount to report a summary of the number of rows rejected due to errors
Long errorLineCount = new Long(0);
// Read the file and fill out the field list.
try (BufferedReader br = new BufferedReader(new FileReader(file)))
{
while ((line = br.readLine()) != null) {
lineCount++; // process the line.
if ( line.startsWith("#") ) {
System.out.println(line);
// If the fields directive is found, parse fields to an array
if ( line.startsWith("#Fields: ") ) {
fieldList = line.substring(9).split(" ");
break;
}
}
else {
// throw error to abort
throw new Exception("Field list not detected.");
}
}
// Process remaining file as data lines
while ((line = br.readLine()) != null) {
Ensuite, chaque ligne est traitée dans le code principal. Notez le support de la déclaration de switch pour chaque champ requis : time cs-method cs-uri-stem sc-status cs-version.Code principal
lineCount++;
// Skip directives
if ( line.startsWith("#") ) {
continue;
}
try {
// parse the line
parts = line.split(" ");
// initialize new row
row1 = new row1Struct();
// Populate each field by position
for( int ii = 0; ii < fieldList.length; ii++) {
switch ( fieldList[ii] ) {
case "time" :
row1.time = parts[ii];
break;
case "sc-status" :
row1.sc_status = Integer.parseInt(parts[ii]);
break;
case "cs-method" :
row1.cs_method = parts[ii];
break;
case "cs-uri-stem" :
row1.cs_uri_stem = parts[ii];
break;
case "cs-version" :
row1.cs_version = parts[ii];
break;
default:
log.warn("Unhandled field encountered [" + fieldList[ii] + "].");
System.out.println("Unhandled field encountered [" + fieldList[ii] + "].");
}
}
} catch (java.lang.Exception e) {
//output exception for each log entry that causes an issue and continue to read next line
log.warn("tJavaFlex_1 [Line " + lineCount + "] " + e.getMessage());
System.err.println(e.getMessage());
errorLineCount++;
continue;
}
À présent, la boucle de traitement des données doit être fermée dans la section Code de fin. C'est également le moment d'afficher des statistiques utiles pour le log, des avertissements concernant les lignes rejetées, etc.
Code de fin
}
}
log.info("tJavaFlex_1 - " + lineCount + " rows processed.");
if (errorLineCount > 0) {
log.warn("tJavaFlex_1 - " + errorLineCount + " rows rejected.");
}
Enfin, il faut ajouter des imports requis à la section Import d'Advanced Settings pour les bibliothèques utilisées.
Imports
import java.io.BufferedReader; import java.io.FileReader;
Exécuter le Job
L'exécution du Job écrit en sortie l'en-tête dans le log (à cause des instructions println) ainsi que les lignes de sortie du tLogRow. Pour voir les données de log supplémentaires, définissez les propriétés Advanced Settings de l'onglet Run : log4jLevel => Info.
Starting job w3c_extended_log_test at 17:45 10/02/2017.
[INFO ]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - TalendJob:
'w3c_extended_log_test' - Start.
[statistics] connecting to socket on port 3935
[statistics] connected
#Version: 1.0
#Date: 2001-05-02 17:42:15
#Fields: time cs-method cs-uri-stem sc-status cs-version
[INFO ]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Content of row 1:
17:42:15|GET|/default.htm|200|HTTP/1.0
17:42:15|GET|/default.htm|200|HTTP/1.0
[INFO
]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Content of row 2:
17:42:15|GET|/default.htm|200|HTTP/1.0
17:42:15|GET|/default.htm|200|HTTP/1.0
[INFO
]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tJavaFlex_1 - 5 rows
processed.
[INFO ]:
sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Printed row count:
2.
[statistics]
disconnected
[INFO ]:
sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - TalendJob: 'w3c_extended_log_test'
- Done.
Job w3c_extended_log_test ended at 17:45
10/02/2017. [exit code=0]Conclusion
L'utilisation du composant tJavaFlex est une fonctionnalité puissante dans Talend permettant une large gamme d'extensions. Cet exemple montre une méthode qui permet un degré de flexibilité dans les formats de fichiers entrants. L'implémentation de ce seul tJavaFlex peut gérer des données d'entrée dans différents formats, notamment l'ajout de nouveaux champs, la transposition de champs et de champs manquants avec un résultat prévisible.
Pour plus d'informations, consultez tJavaFlex et Extended Log File Format (uniquement en anglais) (en anglais).