Pour plus d'informations concernant les droits et autorisations, consultez la documentation ou contactez l'administrateur du cluster Hadoop utilisé.
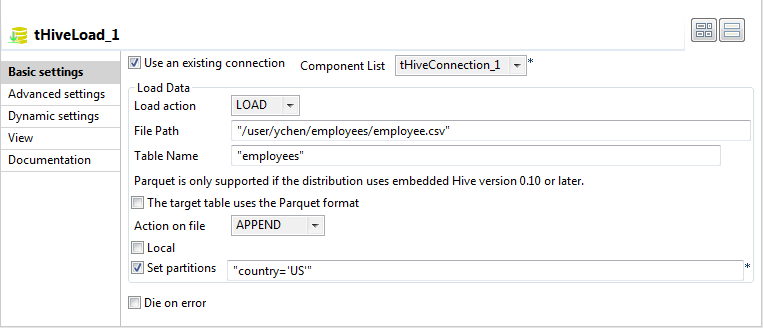
Notez que si vous devez lire des données depuis un système de fichiers local autre que le système HDFS, vous devez vous assurer que les données lues sont stockées dans le système de fichiers local de la machine sur laquelle le Job est exécuté. Cochez ensuite la case Local dans la vue Basic settings. Par exemple, lorsque le mode de connexion à Hive est Standalone, le Job est exécuté sur la machine sur laquelle l'application Hive est installée. Les données sont donc stockées sur cette machine.