
Créer la règle de rapprochement pour grouper les enregistrements similaires
Procédure
-
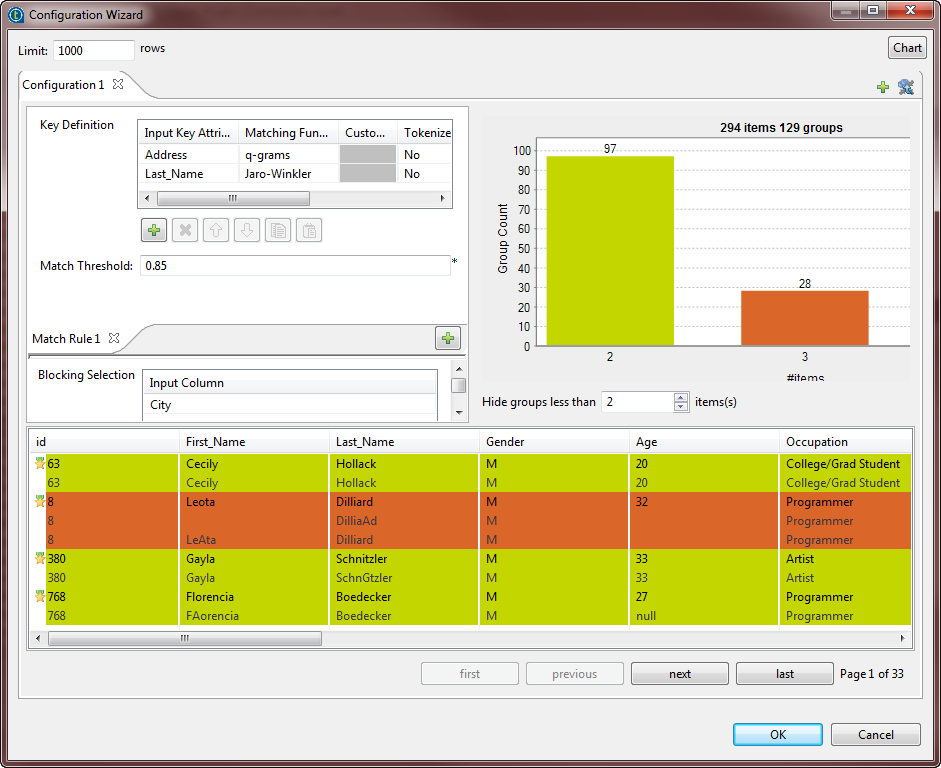
Double-cliquez sur le tMatchGroup afin d'afficher l'assistant de configuration dans lequel vous pouvez définir la règle de rapprochement.
-
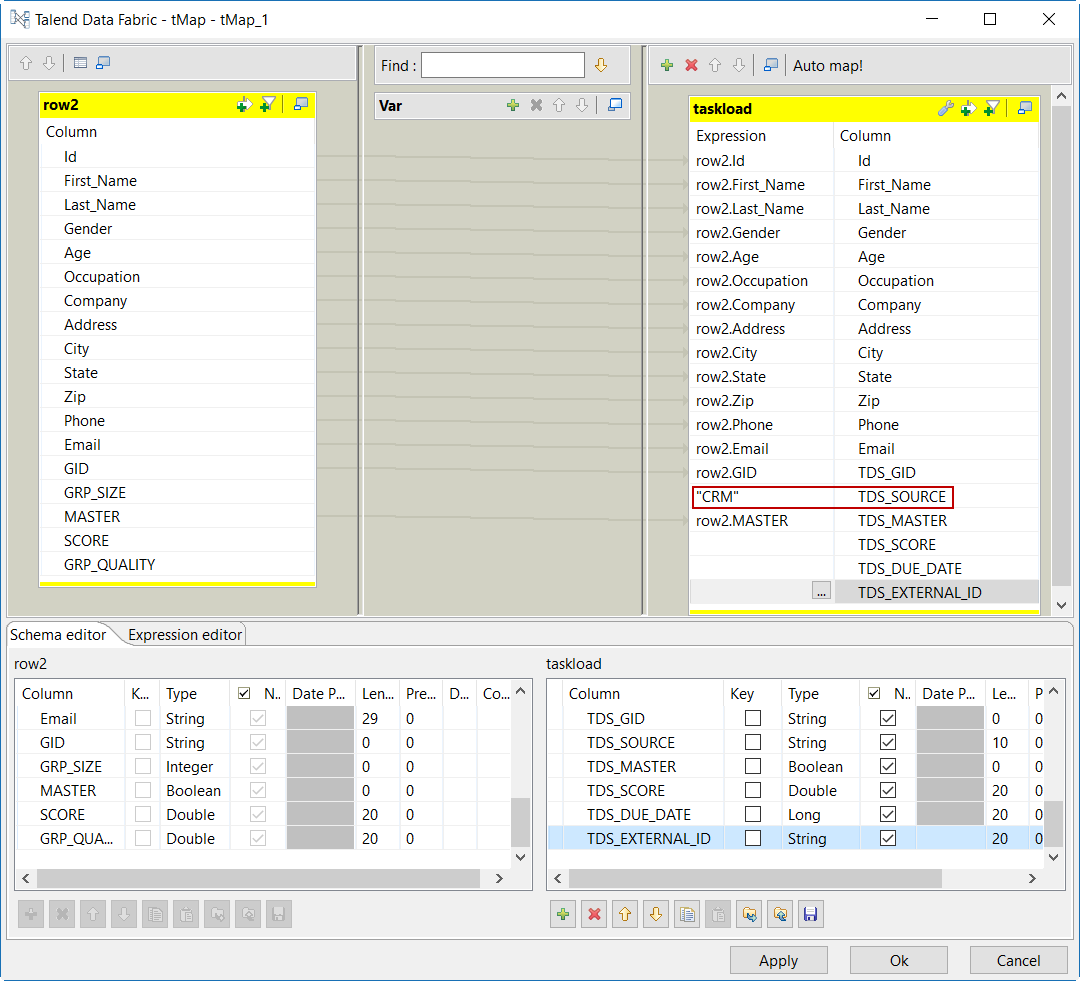
Double-cliquez sur le tMap pour ouvrir son éditeur.
-
Lorsque les données viennent de sources différentes et que le schéma d'entrée dispose d'une colonne contenant le nom des sources, mappez la colonne source à TDS_SOURCE.
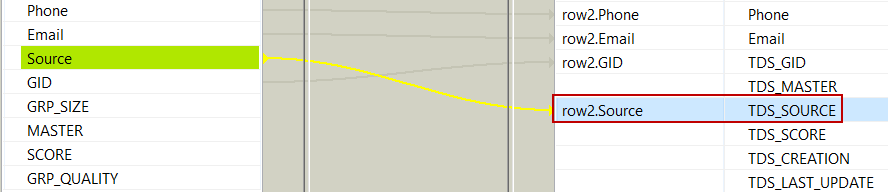
Si vous ne spécifiez aucun nom de source, Source 1, Source 2, etc. sont ajoutés par défaut.
Si vous spécifiez le même nom pour différentes sources d'une même tâche, les suffixes -1, -2, etc. sont ajoutés par défaut. Par exemple, si vous créez une tâche avec trois sources SAP, le nom des sources dans Talend Data Stewardship s'affichent comme suit : SAP, SAP - 1, SAP - 2.
Vous pouvez également calculer de manière dynamique les scores de confiance des enregistrements spécifiques si vous les fournissez au niveau de la source de la tâche et que vous les mappez vers la colonne de sortie TDS_RATING dans le tDataStewardshipTaskOutput. Ces scores de confiance écrasent les éventuels scores définis lors de la création de la campagne.
Vérifiez que les noms des sources dans le fichier d'entrée ne contiennent pas de point et ne commencent pas par un symbole dollar.