
Inmemory-modell
Med QlikViews inmemory-modell läses alla unika värden i de fält som har valts från en tabell i laddningsskriptet in i fältstrukturer. Associativa data laddas samtidigt in i tabellen. Fältdata och associativa data hanteras i RAM-minnet.
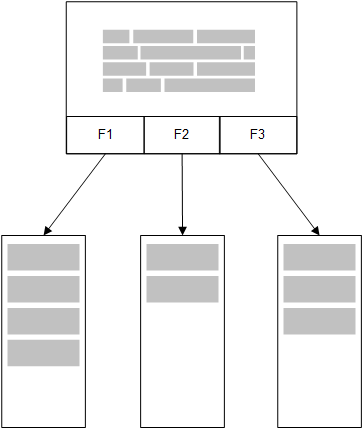
En andra, kopplad tabell som läses in i minnet skulle ha ett gemensamt fält. Den tabellen skulle kunna lägga till nya unika värden i det gemensamma fältet eller dela befintliga värden med det.
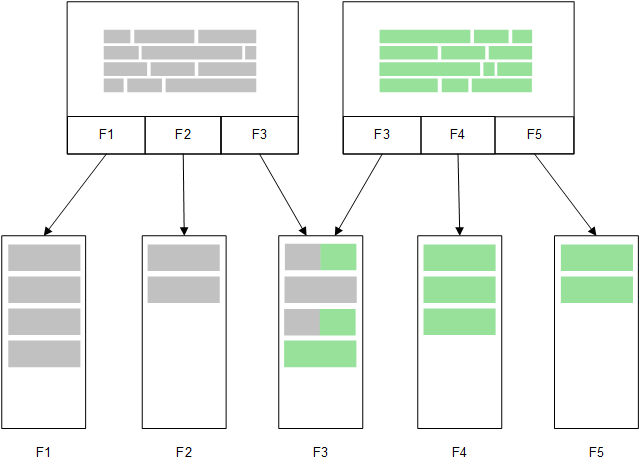
Direct Discovery
När tabellfält läses in med en Direct DiscoveryLOAD-sats (Direct Query), skapas en liknande tabell med enbart DIMENSION-fälten. Precis som med minnesfälten laddas de unika värdena för DIMENSION-fälten till minnet. Men associationerna mellan fälten lämnas kvar i databasen.
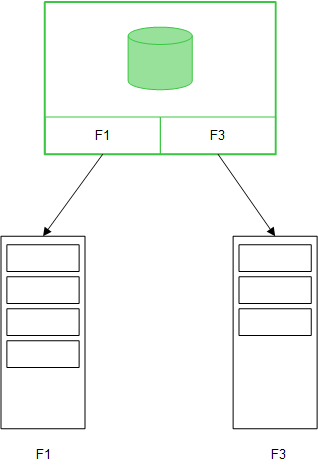
MEASURE-fältvärden lämnas också kvar i databasen.
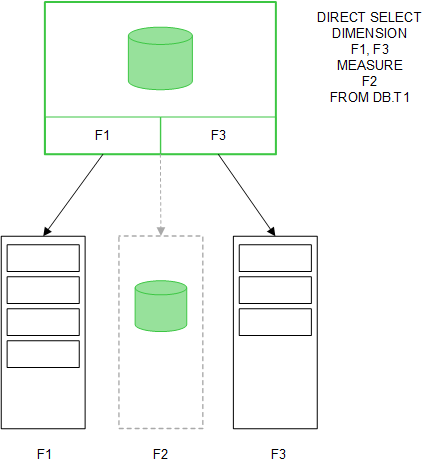
När Direct Discovery-strukturen har etablerats kan Direct Discovery-fälten användas med vissa diagramobjekt, och de kan användas för associationer med inmemory-fält. När ett Direct Discovery-fält används skapar QlikView automatiskt rätt SQL-fråga att köra mot externa data. När man gör val används de associerade datavärdena från Direct Discovery-fälten i WHERE-villkoren i databasfrågorna.
För varje val beräknas diagrammen med Direct Discovery-fält på nytt. Beräkningarna görs i källans databastabell genom att exekvera den SQL-fråga som har skapats i QlikView. Funktionen för beräkningsvillkor kan användas för att ange när diagram ska beräknas på nytt. QlikView skickar inga frågor för att beräkna diagrammen på nytt förrän villkoret har uppfyllts.
Skillnader i prestanda mellan inmemory-fält och Direct Discovery-fält
Inmemory-bearbetning går alltid snabbare än bearbetning i källdatabaser. Prestandan för Direct Discovery motsvarar prestandan för det system där databasen som hanterar Direct Discovery-frågorna körs.
Det går att använda de vanliga regelverken när man gör inställningar för databasen och frågorna för Direct Discovery. Alla prestandainställningar bör göras i källdatabasen. Direct Discovery ger inget stöd för frågeprestandainställningar från QlikView-dokumentet. Det går däremot att göra asynkrona, parallella anrop mot databasen med hjälp av anslutningspoolning. Skriptsyntaxen för anslutningspoolning är:
SET DirectConnectionMax=10;
QlikViews cachelagring förbättrar också användarens upplevelse av programmet. Se Cachning och Direct Discovery nedan.
Prestanda för Direct Discovery med DIMENSION-fält kan även förbättras genom att koppla bort några av fälten från associationerna. Detta görs med nyckelordet DETACH vid DIRECT QUERY. Medan frånkopplade fält inte genomsöks efter associationer, ingår de ändå i filtren, vilket gör att tiderna för val kortas ner.
QlikViews inmemory-fält och Direct Discovery DIMENSION-fält håller båda alla sina data i minnet. Det är sättet på vilket de laddas som påverkar hur snabbt laddningen till minnet går. QlikViews inmemory-fält behåller bara en kopia av ett fältvärde när det finns flera förekomster av samma värde. Men alla fältdata laddas, och sedan sorteras dubblettdata ut.
DIMENSION-fält behåller också bara en kopia av fältvärdet, men dubblettvärdena sorteras ut i databasen innan de läses in i minnet. När du hanterar stora datamängder, vilket är normalt när man använder Direct Discovery, läses data in mycket fortare i form av en DIRECT QUERY-inläsning än genom den SQL SELECT-inläsning som används för minnesfält.
Skillnader mellan inmemory-data och databasdata
DIRECT QUERY är skiftlägeskänsligt vad gäller associationer med minnesdata. Direct Discovery väljer data från källdatabaser enligt skiftlägeskänsligheten hos de genomsökta databasfälten. Om databasfälten inte är skiftlägeskänsliga, kan en Direct Discovery-fråga returnera vissa data som en minnesfråga inte returnerar. Om följande data exempelvis ligger i en databas som inte är skiftlägeskänslig, skulle en Direct Discovery-fråga efter värdet "Red" returnera alla fyra raderna.
| ColumnA | ColumnB |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
Om man å andra sidan väljer "Red," in-memory, returnerar frågan endast:
Red two
QlikView normaliserar data i en utsträckning som leder till att valda data ger matchningar som databaser inte skulle matcha. Därför kan en inmemory-fråga ge fler matchande värden än en Direct Discovery-fråga. Se till exempel tabellen nedan, där värdena för talet "1" varierar beroende på hur blankstegen omkring dem är placerade:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
Om du väljer "1" i en listbox för ColumnA där data är standard för QlikView-inmemory associeras de första tre raderna:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Om listboxen innehåller Direct Discovery-data kan urvalet "1" kanske enbart associera "no_space". Vilka matchningar som returneras för Direct Discovery-data beror på databasen. Vissa returnerar bara "no_space", och vissa, såsom SQL Server, returnerar "no_space" och "space_after".
Cachning och Direct Discovery
QlikView-cachningen lagrar urvalsstatus för frågor och associerade frågeresultat i minnet. När samma typ av val görs använder QlikView sig av frågan i cacheminnet i stället för att söka i källdata. När ett annat val görs, körs en SQL-fråga mot datakällan. De cachade resultaten delas mellan användare.
Exempel:
-
Användaren applicerar ett första urval.
SQL släpps vidare till den bakomliggande datakällan.
-
Användaren rensar sina val och applicerar samma val som första urval.
Cacheresultatet returneras, SQL släpps inte vidare till den bakomliggande datakällan.
-
Användaren applicerar annat urval.
SQL släpps vidare till den bakomliggande datakällan.
En tidsgräns kan anges med hjälp av systemvariabeln DirectCacheSeconds. När tidsgränsen har uppnåtts, rensar QlikView cacheminnet bort Direct Discovery-sökresultaten som genererades för de tidigare valen.QlikView ställer då frågor om urval till datakällan och återskapar cacheminnet för den tilldelade tidsgränsen.
Cachelagringsgränsen för Direct Discovery-sökresultat är 30 minuter, såvida inte systemvariabeln DirectCacheSeconds används.