
Modelo na memória
No modelo na memória do QlikView, todos os valores exclusivos nos campos selecionados a partir de uma tabela no script de carga são carregados nas estruturas de campo e os dados associativos são simultaneamente carregados na tabela. Os dados de campo e os dados associativos são mantidos na memória.
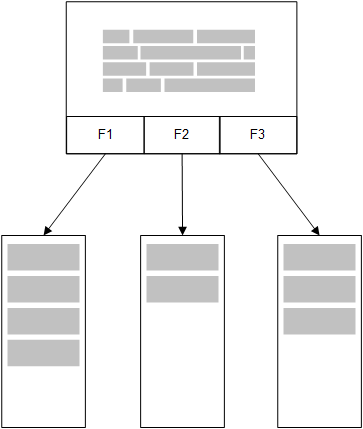
Uma segunda tabela relacionada, carregada na memória compartilharia um campo comum, e essa tabela poderia adicionar novos valores exclusivos ao campo comum ou poderia compartilhar os valores existentes.
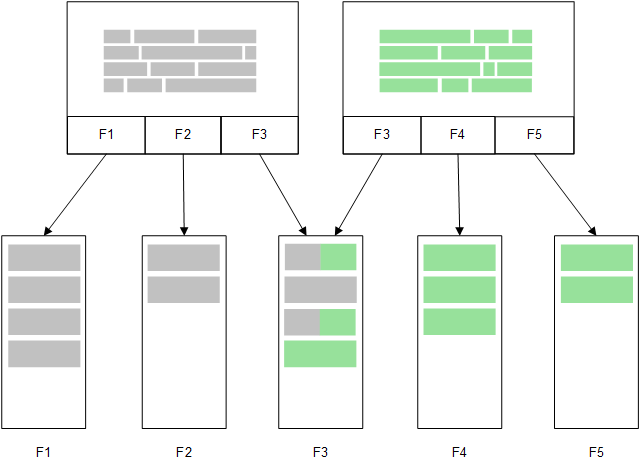
Direct Discovery
Quando os campos da tabela são carregados com um comando Direct DiscoveryLOAD (Direct Query), uma tabela semelhante é criada apenas com os campos DIMENSION. Como ocorre com os campos da memória, os valores exclusivos dos campos DIMENSION são carregados na memória. No entanto, as associações entre os campos são deixadas no banco de dados.
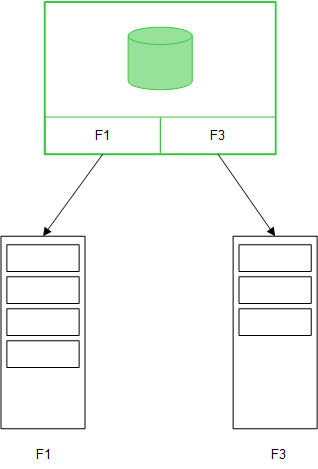
MEASURE são valores dos campos também deixados no banco de dados.
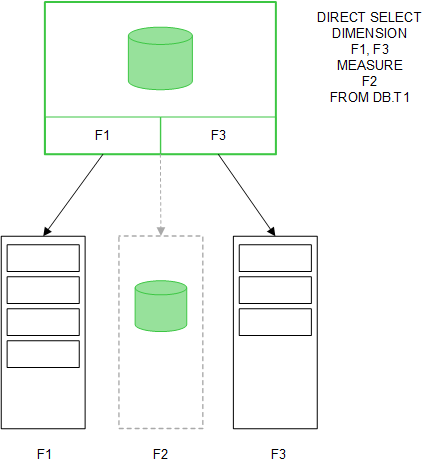
Depois que a estrutura do Direct Discovery é estabelecida, os campos do Direct Discovery podem ser usados com determinados objetos de gráfico e podem ser usados para associações com os campos da memória. Quando um campo do Direct Discovery é usado, o QlikView automaticamente cria a consulta do SQL adequada para ser executada nos dados externos. Quando as seleções são feitas, os valores dos dados associados dos campos do Direct Discovery são usados nas condições WHERE das consultas do banco de dados.
Com cada seleção, os gráficos com os campos do Direct Discovery são recalculados, com os cálculos ocorrendo na tabela da base de dados de origem, por meio da execução da consulta SQL criada pelo QlikView. O recurso de condição de cálculo pode ser usado para especificar quando gráficos devem ser recalculados. Até que a condição seja atendida, o QlikView não envia consultas para recalcular os gráficos.
Diferenças de desempenho entre os campos da memória e os campos do Direct Discovery
O processamento na memória é sempre mais rápido do que o processamento nos bancos de dados de origem. O desempenho do Direct Discovery reflete o desempenho do sistema que executa o banco de dados que processa as consultas do Direct Discovery.
É possível usar as práticas recomendadas de ajuste de consulta e banco de dados para o Direct Discovery. Todo o ajuste de desempenho deve ser feito no banco de dados de origem. O Direct Discovery não oferece suporte para o ajuste de desempenho da consulta a partir do documento do QlikView. No entanto, é possível fazer chamadas paralelas e assíncronas para o banco de dados com o recurso de pool de conexão. A sintaxe do script de carga para configurar o recurso de pool é a seguinte:
SET DirectConnectionMax=10;
O armazenamento em cache do QlikView também melhora a experiência geral do usuário. Consulte Armazenamento em cache e o Direct Discovery abaixo.
O desempenho do Direct Discovery com os campos DIMENSION também pode ser melhorado desvinculando alguns dos campos das associações. Isto é feito com a palavra-chave DETACH em DIRECT QUERY. Embora os campos desvinculados não sejam consultados para associações, eles ainda fazem parte dos filtros, acelerando os tempos de seleção.
Embora QlikView os campos da memória e Direct DiscoveryDIMENSION mantenham todos os seus dados na memória, a maneira pela qual eles são carregados afeta a velocidade das cargas na memória. Os campos da memória do QlikView mantêm apenas uma cópia do valor de campo quando existirem várias instâncias do mesmo valor. No entanto, todos os dados do campo são carregados e, em seguida, os dados duplicados são classificados.
DIMENSION são campos que também armazenam uma cópia do valor de campo, mas os valores duplicados são classificados no banco de dados antes de serem carregados na memória. Ao lidar com grandes quantidades de dados, como geralmente ocorre ao usar o Direct Discovery, os dados são carregados mais rapidamente como uma carga DIRECT QUERY do que seriam por meio da carga SQL SELECT, usada para os campos da memória.
Diferenças entre os dados da memória e os dados do banco de dados
DIRECT QUERY faz distinção entre maiúsculas e minúsculas ao fazer associações com os dados da memória. O Direct Discovery seleciona os dados dos bancos de dados de origem, de acordo com a distinção entre maiúsculas e minúsculas dos campos consultados do banco de dados. Se os campos do banco de dados não fizerem distinção entre maiúsculas e minúsculas, uma consulta do Direct Discovery poderia retornar dados que uma consulta da memória não retornaria. Por exemplo, se os seguintes dados existissem em um banco de dados que não fizesse distinção entre maiúsculas e minúsculas, uma consulta do Direct Discovery do valor "Red" retornaria todas as quatro linhas.
| ColumnA | ColumnB |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
Por outro lado, uma seleção na memória de "Red," retornaria apenas:
Red two
O QlikView normaliza os dados na medida que gera correspondências nos dados selecionados que os bancos de dados não fariam correspondências. Como resultado disso, uma consulta na memória pode gerar mais valores de correspondência do que uma consulta do Direct Discovery. Por exemplo, na tabela a seguir, os valores para o número "1" variam pelo local de espaços ao seu redor:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
Se você selecionar "1" em uma Lista para a ColumnA, onde os dados estão na memória padrão do QlikView, as primeiras três linhas são associadas:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Se a Lista contiver dados do Direct Discovery, a seleção de "1" poderia associar apenas "no_space". As correspondências retornadas para os dados do Direct Discovery dependem do banco de dados. Alguns retornam apenas "no_space" e outros, como o SQL Server, retornam "no_space" e "space_after".
Armazenamento em cache e o Direct Discovery
O armazenamento em cache do QlikView armazena estados de seleção das consultas e os resultados de consultas associados na memória. Já que os mesmos tipos de seleções são feitas, o QlikView aproveita a consulta do cache, em vez de consultar os dados de origem. Quando uma seleção diferente é feita, uma consulta do SQL é feita na fonte de dados. Os resultados armazenados em cache são compartilhados entre os usuários.
Exemplo:
-
O usuário aplica a seleção inicial.
O SQL é transmitido para a fonte de dados subjacente.
-
O usuário limpa a seleção e aplica a mesma seleção como uma seleção inicial.
O resultado do cache é retornado e o SQL não é transmitido para a fonte de dados subjacente.
-
O usuário aplica uma seleção diferente.
O SQL é transmitido para a fonte de dados subjacente.
Um limite de tempo pode ser definido para o armazenamento em cache com a variável do sistema DirectCacheSeconds. Quando o limite de tempo é alcançado, o QlikView limpa o cache dos resultados da consulta do Direct Discovery gerados para as seleções anteriores.O QlikView, então, consulta as seleções nos dados de origem e recria o cache com base no limite de tempo designado.
O tempo de cache padrão para os resultados da consulta do Direct Discovery é de 30 minutos, a menos que a variável do sistema DirectCacheSeconds seja usada.