
Modello in memoria
Nel modello in memoria di licenza tutti i valori univoci nei campi selezionati da una tabella nello script di caricamento vengono caricati in strutture di campo e i dati associativi vengono contemporaneamente caricati nella tabella. Sia i dati dei campi sia i dati associativi vengono conservati in memoria.
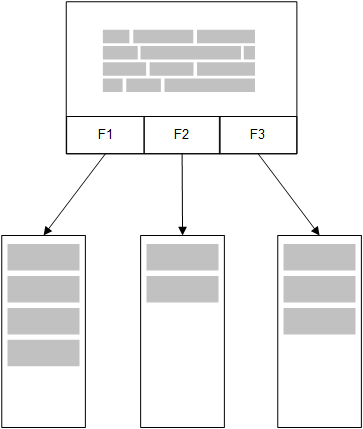
Una seconda tabella correlata caricata in memoria condividerebbe un campo comune e potrebbe aggiungere nuovi valori univoci al campo comune o condividere valori esistenti.
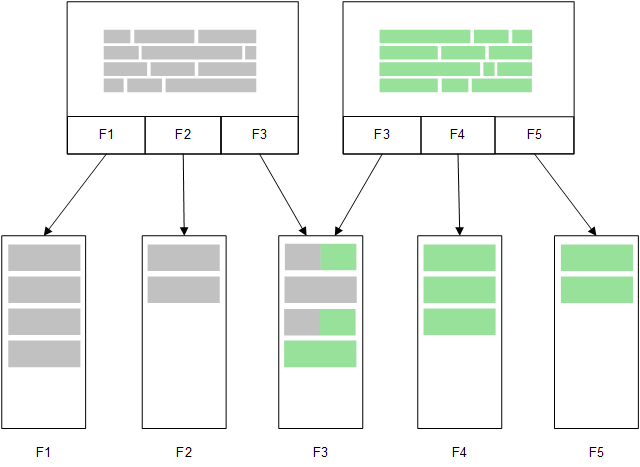
Direct Discovery
Quando i campi della tabella vengono caricati con un'istruzione LOAD di Direct Discovery (Direct Query), viene creata una tabella simile contenente solo i campi DIMENSION. Come con i campi in memoria, i valori univoci per i campi DIMENSION vengono caricati in memoria, ma le associazioni tra i campi rimangono nel database.
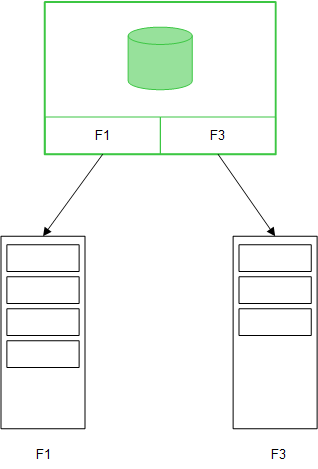
Anche i valori di campo MEASURE vengono lasciati nel database.
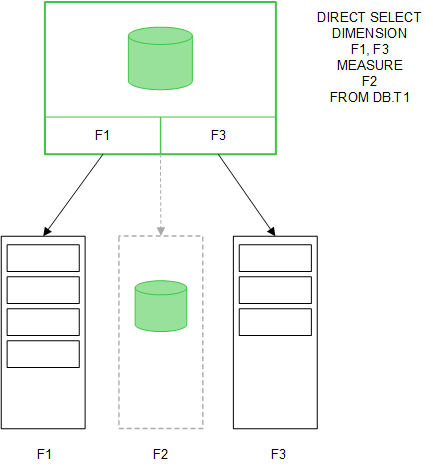
Una volta stabilita la struttura di Direct Discovery, i campi di Direct Discovery possono essere utilizzati con determinati oggetti dei grafici e per le associazioni con i campi in memoria. Quando si utilizza un campo Direct Discovery, licenza crea automaticamente la query SQL appropriata da eseguire sui dati esterni. Quando si effettuano le selezioni, i valori dei dati associati dei campi Direct Discovery vengono utilizzati nelle condizioni WHERE delle query di database.
Con ciascuna selezione i grafici con i campi di Direct Discovery vengono ricalcolati e questi calcoli vengono eseguiti nella tabella del database sorgente con la query SQL creata mediante licenza. È possibile utilizzare la funzione di condizione di calcolo per specificare quando ricalcolare i grafici. Fino a quando la condizione non viene soddisfatta, licenza non invia query per ricalcolare i grafici.
Differenze di prestazioni tra campi in memoria e campi Direct Discovery
L'elaborazione in memoria è sempre più veloce rispetto a quella nei database sorgente. Le prestazioni di Direct Discovery rispecchiano quelle del sistema che esegue il database di elaborazione delle query Direct Discovery.
È possibile utilizzare le procedure consigliate standard di ottimizzazione del database e delle query per Direct Discovery. Tutte le ottimizzazioni delle prestazioni devono essere eseguite nel database sorgente. Direct Discovery non supporta l'ottimizzazione delle prestazioni delle query dal documento licenza. È possibile, tuttavia, effettuare chiamate asincrone, parallele al database, utilizzando la funzionalità di pooling delle connessioni. Di seguito è riportata la sintassi dello script di caricamento per impostare la funzionalità di pooling:
SET DirectConnectionMax=10;
La memorizzazione nella cache licenza permette anche di migliorare l'esperienza generale dell'utente. Vedere Memorizzazione nella cache e Direct Discovery di seguito.
Anche le prestazioni di Direct Discovery con campi DIMENSION possono essere migliorate separando alcuni campi dalle associazioni. A tale scopo viene utilizzata la parola chiave DETACH in DIRECT QUERY. Sebbene i campi separati non vengano sottoposti a query per le associazioni, fanno comunque parte dei filtri e velocizzano i tempi di selezione.
Mentre i campi licenza in memoria e i campi Direct DiscoveryDIMENSION mantengono tutti i dati in memoria, il modo in cui vengono caricati influisce sulla velocità dei caricamenti in memoria. I campi licenza in memoria mantengono una sola copia di un valore di campo quando sono presenti più istanze dello stesso valore. Tuttavia, vengono caricati tutti i dati dei campi e quelli duplicati vengono esclusi in un secondo momento.
Anche i campi DIMENSION contengono solo una copia di un valore di campo, ma i valori duplicati vengono ordinati nel database prima di essere caricati in memoria. Quando si gestiscono grandi quantità di dati, come avviene di solito quando si utilizza Direct Discovery, i dati vengono caricati molto più rapidamente sotto forma di caricamento DIRECT QUERY rispetto a quanto non avverrebbe con il caricamento SQL SELECT utilizzato per i campi in memoria.
Differenze tra dati in memoria e dati di database
DIRECT QUERY rileva la distinzione tra maiuscole e minuscole quando si effettuano associazioni con dati in memoria. Direct Discovery seleziona i dati dai database sorgente in base all'impostazione di distinzione tra maiuscole e minuscole dei campi del database oggetto di query. Se i campi del database non supportano la distinzione tra maiuscole e minuscole, una query Direct Discovery può restituire dati non restituiti da una query in memoria. Ad esempio, se i dati seguenti esistono in un database che non rileva la distinzione tra maiuscole e minuscole, una query Direct Discovery del valore "Red" restituirebbe tutte e quattro le righe.
| ColumnA | ColumnB |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
Una selezione in memoria di "Red," d'altra parte, restituirebbe solo:
Red two
licenza normalizza i dati in modo da produrre corrispondenze nei dati selezionati che non verrebbero riprodotte dai database. Di conseguenza, una query in memoria può produrre più valori corrispondenti rispetto a una query Direct Discovery. Ad esempio, nella tabella seguente i valori per il numero "1" variano in base alla posizione degli spazi adiacenti:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
Se si seleziona "1" in una casella di elenco per ColumnA, in cui i dati sono in memoria licenza standard, vengono associate le prime tre righe:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Se la casella di elenco contiene dati Direct Discovery, la selezione di "1" può associare solo "no_space". Le corrispondenze restituite per i dati Direct Discovery dipendono dal database. Alcuni restituiscono solo "no_space" e altri, come SQL Server, restituiscono "no_space" e "space_after".
Memorizzazione nella cache e Direct Discovery
licenza memorizza nella cache gli stati di selezione delle query e i relativi risultati. Poiché vengono effettuati gli stessi tipi di selezione, licenza sfrutta la query della cache anziché eseguire altre query sui dati sorgente. Quando si effettua una selezione diversa, viene eseguita una query SQL sulla sorgente di dati. I risultati memorizzati nella cache vengono condivisi tra gli utenti.
Esempio:
-
L'utente applica la selezione iniziale.
Viene eseguita una query pass-through SQL sulla sorgente di dati sottostante.
-
L'utente annulla la selezione e applica la stessa selezione iniziale.
Viene restituito il risultato della cache e non vengono eseguite query pass-through, SQL sulla sorgente di dati sottostante.
-
L'utente applica una selezione diversa.
Viene eseguita una query pass-through SQL sulla sorgente di dati sottostante.
È possibile impostare un limite temporale per la memorizzazione nella cache con la variabile di sistema DirectCacheSeconds. Una volta raggiunto tale limite, licenza svuota la cache per i risultati della query Direct Discovery generati per le selezioni precedenti.licenza riprende quindi a eseguire query sui dati sorgente per le selezioni e ricrea la cache per il limite di tempo indicato.
Il tempo di memorizzazione nella cache predefinito per i risultati della query Direct Discovery è 30 minuti, a meno che non si utilizzi la variabile di sistema DirectCacheSeconds.