
La serie di funzioni conosciute come funzioni di aggregazione è costituita da funzioni che prendono più valori di campo come input e restituiscono un singolo risultato per gruppo, dove il raggruppamento viene definito con una dimensione del grafico o una clausola group by nell'istruzione di script.
Le funzioni di aggregazione comprendono Sum(), Count(), Min(), Max(), e molte altre.
La maggior parte delle funzioni di aggregazione può essere utilizzata sia nello script di caricamento dati che nelle espressioni grafiche, anche se la sintassi è diversa.
Utilizzo delle funzioni di aggregazione in uno script di caricamento dati.
Le funzioni di aggregazione possono essere utilizzate soltanto all’interno delle istruzioni LOAD e SELECT .
Utilizzo delle funzioni di aggregazione nelle espressioni grafiche
Il parametro della funzione di aggregazione non deve contenere altre funzioni di aggregazione, a meno che queste aggregazioni interne non contengano il qualificatore TOTAL. Per aggregazioni nidificate più complesse, utilizzare la funzione avanzata Aggr, in combinazione con una dimensione specificata.
La funzione di aggregazione aggrega il set di possibili record definiti dalla selezione. Tuttavia, è possibile definire un set alternativo di record mediante un'espressione di gruppo nell'analisi di gruppo.
Analisi di gruppo ed espressioni di gruppo
Come vengono calcolate le aggregazioni
Un'aggregazione esegue un loop sui record di una tabella specifica, aggregando i record in essa contenuti. Ad esempio, Count(<Field>) conteggerà il numero dei record in una tabella in cui risiede <Field>. Se si desidera aggregare solo i valori dei campi distinti, è necessario usare la clausola distinct, come Count(distinct <Field>).
Se la funzione di aggregazione contiene campi provenienti da tabelle diverse, la funzione di aggregazione eseguirà un loop sui record del prodotto incrociato delle tabelle dei campi costituenti. Questo comporta una penalizzazione delle prestazioni e per questo motivo tali aggregazioni dovrebbero essere evitate, soprattutto quando si dispone di grandi quantità di dati.
Aggregazione dei campi chiave
Il modo in cui vengono calcolate le aggregazioni significa che non è possibile aggregare i campi chiave perché non è chiaro quale tabella debba essere utilizzata per l'aggregazione. Ad esempio, se il campo <Key> collega due tabelle, non è chiaro se Count(<Key>) debba restituire il numero di record dalla prima o dalla seconda tabella.
Tuttavia, se si utilizza la clausola distinct, l'aggregazione risulterà ben definita e potrà essere calcolata.
Pertanto, se si utilizza un campo chiave all'interno di una funzione di aggregazione senza la clausola distinct, licenza restituirà un numero che potrebbe essere privo di significato. La soluzione consiste nell'utilizzare la clausola distinct, o utilizzare una copia della chiave – una copia che risiede in un'unica tabella.
Ad esempio, nelle tabelle seguenti, ProductID è la chiave tra le tabelle.
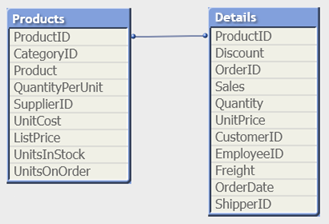
Count(ProductID) può essere conteggiato nella tabella Products (che ha solo un record per prodotto – ProductID è la chiave principale) oppure può essere conteggiato nella tabella Details (che molto probabilmente presenterà svariati record per prodotto). Se si desidera conteggiare il numero di prodotti distinti, utilizzare Count(distinct ProductID). Se si desidera conteggiare il numero di righe in una tabella specifica, non usare la chiave.