
Den grupp av funktioner som kallas aggregeringsfunktioner utgörs av funktioner som tar flera fältvärden som indata och returnerar ett enda resultat, där grupperingen definieras av en diagramdimension eller en group by-sats i skriptet.
Aggregeringsfunktionerna omfattar Sum(), Count(), Min(), Max() med flera.
De flesta aggregeringsfunktioner kan användas i både dataladdningsskriptet och diagramuttrycken, men syntaxen skiljer sig åt.
Använda aggregeringsfunktioner i ett dataladdningsskript
Aggregeringsfunktioner kan enbart användas inuti LOAD - och SELECT-satser.
Använda aggregeringsfunktioner i diagramuttryck
Parametern för aggregeringsfunktionen får inte innehålla andra aggregeringsfunktioner, om inte dessa inre aggregeringar innehåller kvalificeraren TOTAL. För mer avancerade nästlade aggregationer kan du använda den avancerade funktionen Aggr, i kombination med en specificerad dimension.
En aggregeringsfunktion aggregerar över den uppsättning möjliga poster som definierats av urvalet. En alternativ uppsättning poster kan dock definieras med ett s.k. set-uttryck i set-analys.
Hur aggregeringar kalkyleras
En aggregering gör en loop över posterna i en specifik tabell och aggregerar posterna i den. Till exempel kommer Count(<Field>) att räkna antalet poster i tabellen där <Field> finns. Skulle du vilja aggregera endast de distinkta postvärdena, behöver du använda distinct-satsen, som t.ex. Count(distinct <Field>).
Om aggregeringsfunktionen innehåller fält från olika tabeller kommer aggregeringsfunktionen att göra en loop över fälten för korsprodukten av tabellerna i de konstituerande fälten. Detta försämrar prestandan, och därför bör sådan aggregeringar undvikas, särskilt när du har stora datamängder.
Aggregering av nyckelfält
Sättet aggregeringar kalkyleras på innebär att du inte kan aggregera nyckelfält eftersom det inte är tydligt vilken tabell som skulle användas för aggregeringen. Om till exempel fältet <Key> länkar två tabeller, är det inte tydligt om Count(<Key>) skulle returnera antalet poster från den första eller andra tabellen.
Men om du använder distinct-satsen, är aggregeringen väldefinierad och kan beräknas.
Så om du använder ett nyckelfält inuti en aggregeringsfunktion utan distinct-satsen, kommer QlikView att returnera ett nummer som kan vara meningslöst. Lösningen är att antingen använda distinct-satsen, eller använda en kopia av nyckeln –en kopia som finns endast i en tabell..
Till exempel är ProductID nyckeln mellan tabellerna i följande tabeller.
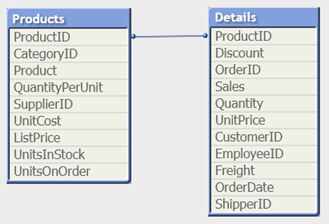
Count(ProductID) kan räknas antingen i Products-tabellen (som endast har en post per produkt – ProductID är primärnyckeln) eller så kan den räknas i Details-tabellen (som högst troligt har flera poster per produkt). Om du vill räkna antalet distinkta produkter bör du använda Count(distinct ProductID). Om du vill räkna antalet rader i en specifik tabell bör du inte använda nyckeln.