
De functiegroep met zogeheten aggregatiefuncties bestaat uit functies die meerdere veldwaarden als invoer aannemen en een enkel resultaat per groep retourneren, waarbij de groepering wordt gedefinieerd door een grafiekdimensie of een group by-clausule in de scriptinstructie.
Aggregatiefuncties zijn onder meer Sum(), Count(), Min(), Max() en nog veel meer.
De meeste aggregatiefuncties kunnen zowel worden gebruikt in het load-script voor gegevens als in diagramuitdrukkingen, maar de syntaxis verschilt.
Aggregatiefuncties gebruiken in een load-script voor gegevens
Aggregatiefuncties kunnen alleen worden gebruikt binnen LOAD - en SELECT-opdrachten.
Aggregatiefuncties gebruiken in grafiekuitdrukkingen
De parameter van de aggregatiefunctie mag geen andere aggregatiefuncties bevatten, tenzij deze interne aggregaties de kwalificatie TOTAL bevatten. Gebruik voor meer geavanceerde geneste aggregaties de geavanceerde functie Aggr, in combinatie met een opgegeven dimensie.
Een aggregatiefunctie aggregeren over de set mogelijke records die wordt gedefinieerd door de selectie. Maar er kan een alternatieve set records worden gedefinieerd door gebruik te maken van een set-uitdrukking bij set-analyse.
Set-analyse en set-uitdrukkingen
Hoe aggregaties worden berekend
Een aggregatie wordt uitgevoerd voor de records van een specifieke tabel en aggregeert de records in de tabel. Met Count (<Field>) telt het aantal records in de tabel waar <Field> aanwezig is. Als u alleen specifieke veldwaarden wilt aggregeren, moet u de clausule distinct gebruiken, zoals Count(distinct <Field>).
Als de aggregatiefunctie velden van verschillende tabellen bevat, wordt de aggregatiefunctie uitgevoerd voor records van het kruisproduct van de tabellen van de onderliggende velden. Hiervoor geldt een prestatiestraf en om deze reden moet u deze aggregaties vermijden, zeker als u grote hoeveelheden gegevens hebt.
Aggregatie van sleutelvelden
Door de manier waarop aggregaties worden berekend, kunt u geen sleutelvelden aggregeren omdat niet duidelijk is welke tabel voor de aggregatie moet worden gebruikt. Bijvoorbeeld als het veld <Key> twee tabellen koppelt, is niet duidelijk of Count(<Key>) het aantal records van de eerste of tweede tabel moet retourneren.
Als u echter de distinct-clausule gebruikt, is de aggregatie goed gedefinieerd en kan worden berekend.
Dus als u een sleutelveld binnen een aggregatiefunctie gebruikt zonder de distinct-clausule, retourneert QlikView mogelijk een getal dat geen betekenis heeft. De oplossing is om de distinct-clausule te gebruiken of een kopie van de sleutel te gebruiken. Dat wil zeggen een kopie die alleen in één tabel aanwezig is.
In de volgende tabellen bijvoorbeeld is ProductID de sleutel tussen de tabellen.
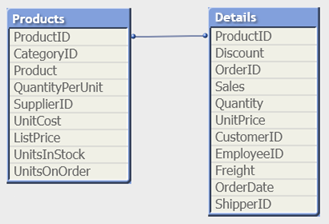
Count(ProductID) kan geteld worden in de Products-tabel (dat één record per product bevat– ProductID is de primaire sleutel) of het kan worden geteld in de Details-tabel (dat waarschijnlijk meerdere records per product bevat). Als u het aantal afzonderlijke producten wilt tellen, moet u Count(distinct ProductID) gebruiken. Als u het aantal rijen in een specifieke tabel wilt tellen, moet u de sleutel niet gebruiken.