
Diferencias entre datos Direct Discovery y datos en memoria
El modelo en memoria
En el modelo en memoria de Qlik Sense, todos los valores únicos de los campos seleccionados de una tabla en el script de carga se cargan en estructuras de campos, y los datos asociados se cargan en la tabla de forma simultánea. Los datos de campos y los datos asociados se hallan todos en la memoria.
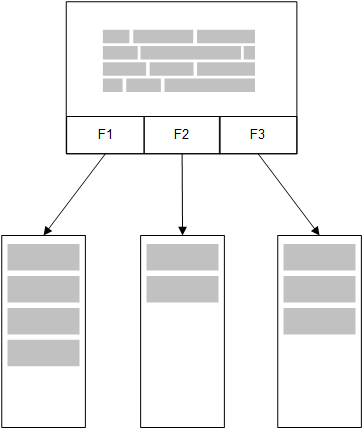
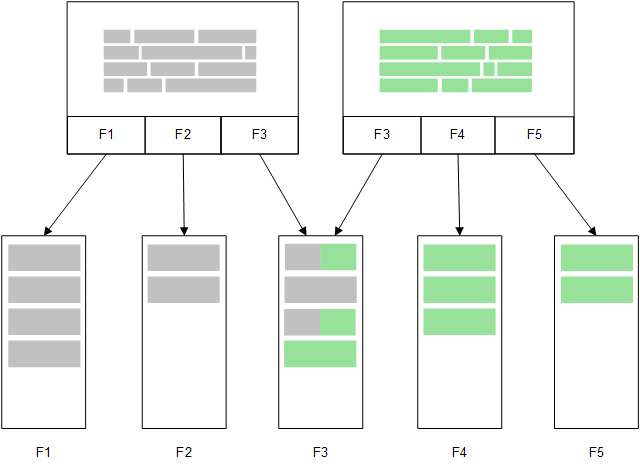
Una segunda tabla relacionada cargada en la memoria compartiría un campo común y esa tabla podría añadir nuevos valores únicos al campo común, o podría compartir valores previos.
Direct Discovery
Cuando los campos de tabla se cargan mediante una sentencia Direct Discovery LOAD (Direct Query), se crea una tabla similar únicamente con los campos DIMENSION. Al igual que ocurre con los campos en memoria, los valores únicos de los campos DIMENSION se cargan en la memoria. Pero las asociaciones entre los campos se quedan en la base de datos.
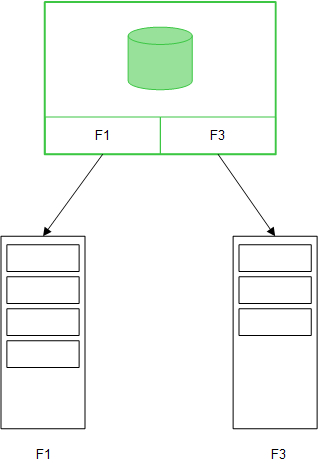
Los valores del campo MEASURE también se quedan en la base de datos.
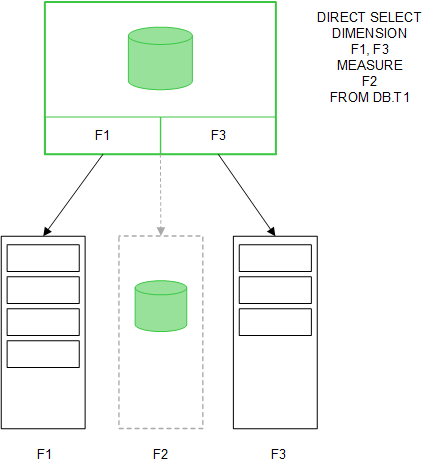
Una vez que se ha establecido la estructura Direct Discovery, los campos Direct Discovery se pueden usar con determinados objetos de visualización y pueden utilizarse para asociaciones con los campos en memoria. Cuando se utiliza un campo Direct Discovery, Qlik Sense automáticamente crea la consulta SQL adecuada para ejecutarse en los datos externos. Cuando se realizan selecciones, los valores de datos asociados de los campos Direct Discovery se utilizan en las condiciones WHERE de las consultas a la base de datos.
Con cada selección, las visualizaciones con campos Direct Discovery se recalculan y los cálculos se realizan en la tabla de la base de datos de origen ejecutando la consulta SQL creada por Qlik Sense. Se puede utilizar la funcionalidad de la condición de cálculo para especificar cuándo queremos que se recalculen las visualizaciones. Hasta que se cumpla dicha condición, Qlik Sense no envía consultas para recalcular las visualizaciones.
Diferencias de rendimiento entre campos en memoria y campos Direct Discovery
El procesamiento en memoria siempre es más rápido que el procesamiento en las bases de datos fuente. El rendimiento de Direct Discovery refleja el rendimiento del sistema que ejecuta la base de datos que procesa las consultas de Direct Discovery.
Es posible utilizar las mejores prácticas estándar de bases de datos y rendimiento de consultas en Direct Discovery. Todos los ajustes de rendimiento deberían hacerse en la base de datos fuente. Direct Discovery no ofrece soporte para el ajuste del rendimiento de las consultas desde la app de Qlik Sense. Sin embargo, sí es posible hacer llamadas paralelas asíncronas a la base de datos utilizando la capacidad de agrupación de conexiones. La sintaxis de script de carga para configurar la capacidad de conexión directa es la siguiente:
SET DirectConnectionMax=10;
El almacenamiento en la caché de Qlik Sense también mejora la experiencia global del usuario. Vea Almacenamiento en caché y Direct Discovery más adelante.
El rendimiento de Direct Discovery con DIMENSION también puede mejorarse separando algunos de los campos de las asociaciones. Esto se hace mediante la palabra clave DETACH en DIRECT QUERY. Si bien los campos separados no se consultan en busca de asociaciones, aún forman parte de los filtros, con lo que aceleran los tiempos de selección.
Mientras que los campos en memoria de Qlik Sense y los campos Direct DiscoveryDIMENSION poseen todos sus datos en memoria, la manera en que se cargan afecta a la velocidad de carga de datos de la memoria. Los campos en memoria de Qlik Sense guardan solo una copia de un valor de campo cuando hay múltiples instancias de un mismo valor. Sin embargo, se cargan todos los datos de campo y luego los datos duplicados se clasifican.
Los campos DIMENSION también almacenan solo una copia de un valor de campo, pero los valores duplicados se clasifican y organizan en la base de datos antes de cargarse en la memoria. Cuando manejamos cantidades extensas de datos, como suele ocurrir cuando usamos Direct Discovery, los datos se cargan mucho más rápido como una carga DIRECT QUERY que con la carga SQL SELECT empleada para campos en memoria.
Diferencias entre datos en memoria y datos de bases de datos
DIRECT QUERY es sensible a mayúsculas cuando se efectúan asociaciones con datos en memoria. Direct Discovery selecciona datos de bases de datos fuente conforme a la distinción de mayúsculas de los campos de la base de datos consultada. Si los campos de la base de datos no son sensibles a mayúsculas, una consulta Direct Discovery podría devolver datos que no devolvería una consulta en memoria. Por ejemplo, si los siguientes datos existen en una base de datos que no distingue entre mayúsculas y minúsculas, una consulta Direct Discovery sobre el valor "Red" devolverá las cuatro filas.
| ColumnaA | ColumnaB |
|---|---|
| rojo | uno |
| Rojo | dos |
| rOJO | tres |
| ROJO | cuatro |
Una selección en memoria de "Red," por otro lado, devolvería únicamente:
Red two
Qlik Sense normaliza los datos hasta tal punto que produce correspondencias en datos seleccionados que las bases de datos no encontrarían. Como resultado, una consulta en memoria puede producir más valores de correspondencias que una consulta de Direct Discovery. Por ejemplo, en la tabla siguiente, los valores para el número "1" varían según la ubicación de los espacios a su alrededor:
| ColumnaA | ColumnaB |
|---|---|
| ' 1' | espacio_antes |
| '1' | sin_espacio |
| '1 ' | espacio_después |
| '2' | dos |
Si selecciona "1" en un Panel de filtrado para ColumnA, donde los datos están en memoria estándar en Qlik Sense, las primeras tres filas se asocian:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Si el Panel de filtrado contiene datos Direct Discovery, la selección de "1" podría asociar solo "no_space". Las correspondencias que devuelven datos Direct Discovery dependen de la base de datos. Algunas devuelven solo "no_space" y otras, como SQL Server, devuelven "no_space" y "space_after".
Almacenamiento en caché y Direct Discovery
El almacenamiento en la caché de Qlik Sense almacena los estados de selección de las consultas y los resultados de las consultas asociadas en la memoria. A medida que se van haciendo los mismos tipos de selecciones, Qlik Sense aprovecha la consulta de la caché en lugar de consultar los datos fuente. Cuando se realiza una selección diferente, se realiza una consulta SQL en la fuente de datos. Los resultados de la caché se comparten entre usuarios.
Ejemplo:
-
El usuario aplica la selección inicial.
SQL se pasa a la fuente de datos subyacente.
-
El usuario borra la selección y aplica la misma selección que la selección inicial.
Devuelve el resultado de la caché, SQL no se pasa a la fuente de datos subyacente.
-
El usuario aplica otra selección distinta.
SQL se pasa a la fuente de datos subyacente.
Se puede establecer un límite de tiempo en el almacenamiento en caché con la variable del sistema DirectCacheSeconds. Una vez que se ha alcanzado el límite de tiempo, Qlik Sense borra la caché de los resultados de la consulta Direct Discovery que se generaron para las selecciones anteriores. Qlik Sense consulta entonces a la fuente de datos las selecciones efectuadas y crea la caché de nuevo según el límite de tiempo designado.
El tiempo de caché predeterminado para los resultados de la consulta Direct Discovery es de 30 minutos, a menos que se use la variable de sistema DirectCacheSeconds.