
Różnice między danymi Direct Discovery a danymi w pamięci głównej
Model oparty na pamięci głównej
W ramach udostępnianego przez Qlik Sense modelu opartego na pamięci głównej (in-memory model) wszystkie niepowtarzalne wartości w polach wybranych z tabeli przez skrypt ładowania są ładowane do struktur pól, podczas gdy dane asocjacyjne są jednocześnie ładowane do tej tabeli. Wszystkie dane pól i dane asocjacyjne są przechowywane w pamięci głównej.
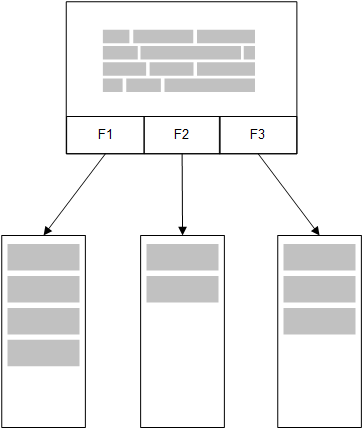
Druga powiązana tabela załadowana do pamięci głównej będzie mieć wspólne pole z pierwszą tabelą i może dodawać do tego wspólnego pola nowe niepowtarzalne wartości lub współdzielić z nim istniejące wartości.
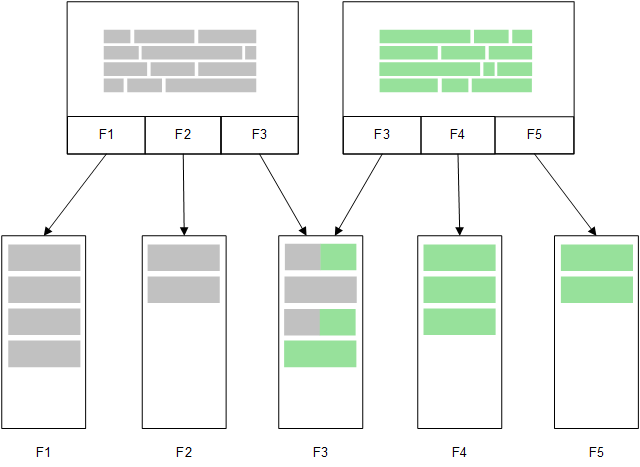
Direct Discovery
Jeśli pola tabeli zostaną załadowane za pomocą instrukcji Direct Discovery LOAD (Direct Query), utworzona zostanie wówczas podobna tabela, ale wyłącznie z polami DIMENSION. Jak ma to miejsce w modelu opartym na pamięci głównej, niepowtarzalne wartości dla pól DIMENSION są ładowane do pamięci głównej. Asocjacje między polami pozostają jednak nadal zapisane w bazie danych.
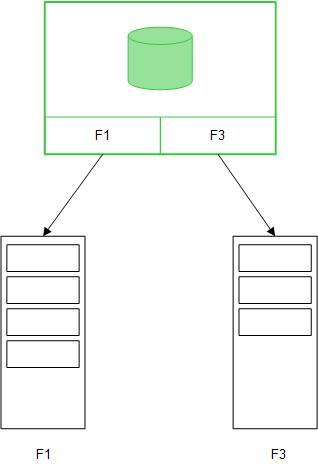
Wartości pól MEASURE są również pozostawiane w bazie danych.
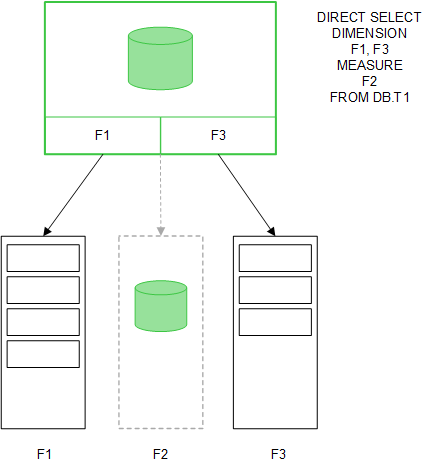
Po zdefiniowaniu struktury Direct Discovery można używać pól Direct Discovery z niektórymi obiektami wizualizacji oraz na potrzeby asocjacji z polami zapisanymi w pamięci głównej. Jeśli korzysta się z pola Direct Discovery, Qlik Sense automatycznie tworzy odpowiednie zapytanie SQL uruchamiane względem danych zewnętrznych. Po dokonaniu selekcji wartości powiązanych danych z pól Direct Discovery są używane w warunkach WHERE zapytań do bazy danych.
Z każdą selekcją następuje ponowne obliczenie wizualizacji zawierających pola Direct Discovery, a obliczenia mają miejsce w tabeli źródłowej bazy danych w wyniku wykonania zapytania SQL utworzonego przez Qlik Sense. Do określenia momentu ponownego obliczenia wizualizacji można używać funkcji warunku obliczenia. Program Qlik Sense nie będzie wysyłać zapytań w celu ponownego obliczenia wizualizacji, dopóki taki warunek nie zostanie spełniony.
Różnice w działaniu pól w pamięci głównej i pól Direct Discovery
Przetwarzanie odbywające się w pamięci głównej jest zawsze szybsze niż przetwarzanie odbywające się w źródłowych bazach danych. Działanie mechanizmu Direct Discovery jest uzależnione od działania systemu udostępniającego bazę danych, w której przetwarzane są zapytania Direct Discovery.
W celu obsługi mechanizmu Direct Discovery można korzystać ze standardowej bazy danych i najlepszych praktyk w zakresie optymalizacji zapytań. Wszelkie takie optymalizacje powinny być wykonywane w źródłowej bazie danych. Mechanizm Direct Discovery nie umożliwia optymalizowania zapytań z aplikacji Qlik Sense. Można jednak używać funkcji pul połączeń w celu asynchronicznego wysyłania równoległych wywołań do bazy danych. Składnia skryptu ładowania umożliwiająca konfigurację pul połączeń jest następująca:
SET DirectConnectionMax=10;
Ogólną wygodę obsługi zwiększa też włączenie buforowania w programie Qlik Sense. Zob. Buforowanie i Direct Discovery poniżej.
Działanie Direct Discovery z polami DIMENSION może być również ulepszone przez odłączenie niektórych pól od asocjacji. W tym celu należy skorzystać ze słowa kluczowego DETACH w ramach DIRECT QUERY. Odłączone pola nie są uwzględniane w zapytaniu o asocjacje, ale są nadal używane do filtrowania i skracają czas związany z selekcją.
Zarówno pola oparte na pamięci głównej Qlik Sense, jak i pola Direct Discovery DIMENSION zapisują wszystkie swoje dane w pamięci głównej, ale sposób ich ładowania wpływa na szybkość ładowania do pamięci głównej. W Qlik Sense pola oparte na pamięci głównej mają tylko jedną kopię wartości pola w przypadku wielu wystąpień tej samej wartości. Wszystkie dane pól są jednak ładowane, a następnie powielone dane zostają zidentyfikowane.
Pola DIMENSION również mają tylko jedną kopię wartości pola, wartości powielone są jednak odrzucane już przy sortowaniu w bazie danych, przed załadowaniem do pamięci. W przypadku przetwarzania dużych ilości danych, jak ma to zazwyczaj miejsce w przypadku korzystania z Direct Discovery, dane te zostają załadowane znacznie szybciej w ramach instrukcji DIRECT QUERY, niż w ramach instrukcji SQL SELECT używanej dla pól opartych na pamięci głównej.
Różnice między danymi w pamięci głównej i danymi w bazie danych
Instrukcja DIRECT QUERY uwzględnia wielkość liter podczas tworzenia asocjacji z danymi opartymi na pamięci głównej. Direct Discovery wybiera dane ze źródłowych baz danych zgodnie z zasadami uwzględniania wielkości liter w polach bazy danych, których dotyczą zapytania. Jeśli w polach w bazie danych wielkość liter nie jest uwzględniana, wówczas zapytanie Direct Discovery może zwrócić dane, których nie zwróciłoby zapytanie oparte na pamięci głównej. Jeśli na przykład następujące dane występowały w bazie danych, która nie uwzględnia wielkości liter, zapytanie Direct Discovery o wartość "Red" zwróciłoby wszystkie cztery wiersze.
| ColumnA | ColumnB |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
W przypadku modelu opartego na pamięci głównej wybór "Red," zwróciłby jednak tylko następujący wynik:
Red two
Qlik Sense dokonuje zaawansowanej normalizacji danych, dzięki czemu może znajdować w wybranych danych wyniki, których nie ujawniłaby baza danych. W efekcie zapytanie oparte na pamięci głównej może zwrócić więcej pasujących wartości niż zapytanie Direct Discovery. Na przykład w następującej tabeli wartości dla liczby "1" różnią się lokalizacją spacji dookoła niej:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
W przypadku wybrania "1" w Panelu filtrowania dla ColumnA, gdy dane są podane w standardowym modelu Qlik Sense opartym na pamięci głównej, powiązane zostaną trzy pierwsze wiersze:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Jeśli Panel filtrowania zawiera dane Direct Discovery, selekcja "1" może skojarzyć tylko wiersze "no_space". Wyniki zwracane dla danych Direct Discovery zależą od bazy danych. Czasami zwrócone zostaną tylko wartości "no_space", a czasami, na przykład w przypadku SQL Server, zwrócone zostaną wartości "no_space" i "space_after".
Buforowanie i Direct Discovery
W Qlik Sense buforowanie powoduje, że stany wyboru zapytań i wyniki powiązanych zapytań są umieszczane w pamięci głównej. W przypadku dokonania tych samych selekcji Qlik Sense korzysta z zapytania zapisanego w buforze i nie przesyła już zapytania do bazy danych. W przypadku dokonania innej selekcji, do źródła danych przesyłane jest zapytanie SQL. Znajdujące się w buforze wyniki są udostępniane użytkownikom.
Przykład:
-
Użytkownik dokonuje początkowej selekcji.
Do bazowego źródła danych przesłane zostaje zapytanie SQL.
-
Użytkownik czyści selekcję, a następnie ponownie dokonuje tej samej selekcji.
Zwracany jest wynik z bufora, a zapytanie SQL nie zostaje przesłane do bazowego źródła danych.
-
Użytkownik dokonuje innej selekcji.
Do bazowego źródła danych przesłane zostaje zapytanie SQL.
Dla buforowania można ustawić limit czasu za pomocą zmiennej systemowej DirectCacheSeconds. Gdy ten limit zostanie osiągnięty, program Qlik Sense wyczyści bufor, aby zrobić miejsce na wyniki zapytania Direct Discovery wygenerowane na podstawie poprzednich selekcji. Następnie Qlik Sense generuje zapytania do danych źródłowych pod kątem selekcji i odtwarza bufor, który istnieje do osiągnięcia wyznaczonego limitu czasu.
Domyślny czas buforowania dla wyników zapytania Direct Discovery to 30 minut, chyba że zastosowana została zmienna systemowa DirectCacheSeconds.