
Direct Discovery とインメモリ データとの違い
インメモリ モデル
Qlik Sense のインメモリ モデルでは、ロード スクリプトのテーブルから選択された項目のユニーク値が項目構造にすべてロードされ、それと同時に連想データはテーブルにロードされます。項目データおよび連想データは、すべてメモリに保持されています。
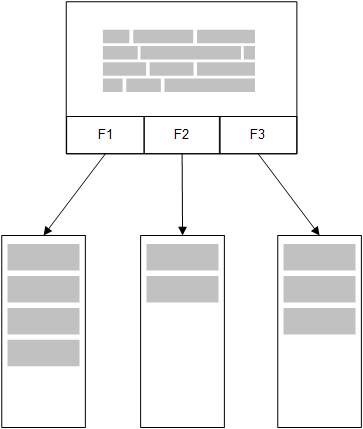
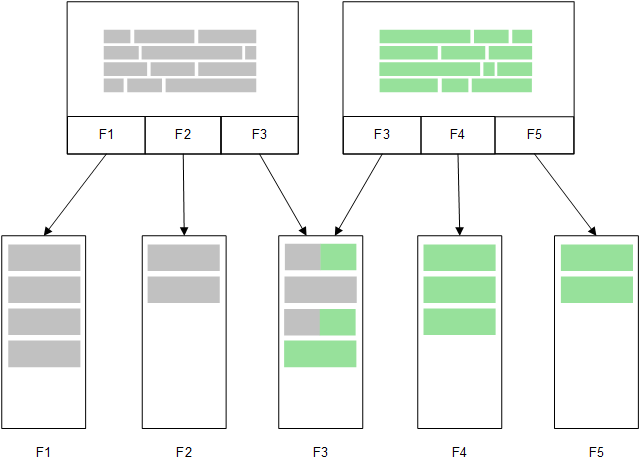
メモリにロードされたもう一つの関連テーブルは、共通の項目を共有することがあります。そしてそのテーブルは、共通の項目に新しい一意の値を追加したり、既存値を共有したりする場合があります。
Direct Discovery
テーブル項目が Direct Discovery LOAD ステートメント (Direct Query) でロードされると、DIMENSION 項目のみで類似テーブルが作成されます。インメモリ項目では、DIMENSION 項目のユニーク値がメモリにロードされます。ただし、項目間の関係性はデータベースに残ります。
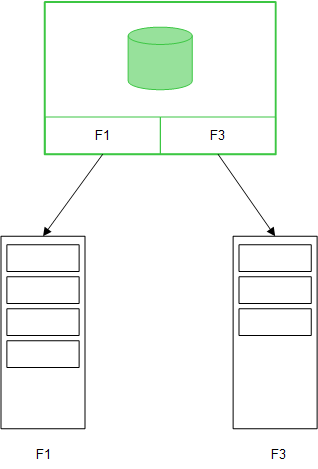
MEASURE 項目値もまた、データベースに残ります。
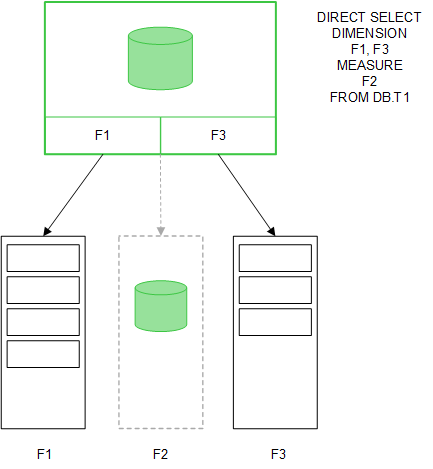
Direct Discovery 構造が確立すると、特定の ビジュアライゼーション オブジェクトと共に Direct Discovery 項目を使用できます。そして、インメモリ項目を使った関連付けのためにもこの項目を使用できます。Direct Discovery 項目が使用されている場合、Qlik Sense は適切な SQL クエリ を自動作成し、外部データ上で実行します。選択を行うと、データベースのクエリの WHERE 条件で Direct Discovery 項目の関連データ値が使用されます。
Direct Discovery 項目を含むビジュアライゼーションは、各選択条件に従い再計算されます。そして、Qlik Sense で作成された SQL クエリを実行することにより、元のデータベース テーブルに計算結果が表示されます。演算実行条件の機能を使用すれば、ビジュアライゼーションを再計算するタイミングを指定できます。条件が合うまで、Qlik Sense はビジュアライゼーションを再計算するクエリを送信しません。
インメモリ項目と Direct Discovery 項目とのパフォーマンスの違い
インメモリでの処理スピードは、ソース データベースでの処理スピードよりも常に速くなります。Direct Discovery のパフォーマンスは、Direct Discovery クエリを処理するデータベースを稼働しているシステムのパフォーマンスにより異なります。
Direct Discovery のベスト プラクティスを引き出す標準的なデータベースおよびクエリを使用することができます。パフォーマンスの調整はすべて、ソース データベース上で行われます。Direct Discovery は、Qlik Sense アプリからのクエリのパフォーマンス調整には対応していません。ただし、接続プーリング機能を使用することで、データベースへの非同期・同時呼び出しを行うことはできます。プーリング機能を設定するロード スクリプト構文は以下の通りです。
SET DirectConnectionMax=10;
Qlik Sense キャッシュにより、ユーザー エクスペリエンス全体が改善されます。以下 キャッシュおよび Direct Discovery を参照してください。
一部項目の関連付けを解除することでも、DIMENSION 項目を含む Direct Discovery のパフォーマンスを改善できます。これは、DIRECT QUERY 上で DETACH キーワードを用いて実行されました。関連付けが解除された項目では、関連付けのクエリは実行されませんが、フィルターの一部として残っているので、選択時間を短縮できます。
Qlik Sense のインメモリ項目と Direct Discovery の DIMENSION 項目の両方の全データがメモリ内に保持されている間、項目へのロード方法の違いは、メモリへのロード速度に影響を及ぼします。同じ値を持つ複数のインスタンスが存在する場合、Qlik Sense のインメモリ項目は、項目値のコピーを 1 つだけ保持します。ただし、全項目データをロードして、重複データが抽出されます。
DIMENSION 項目も項目値のコピーを 1 つだけ保持しますが、重複値はメモリへのロードに先立ち、データベースで抽出されます。Direct Discovery を使用する際と同様に、大量のデータを取り扱う場合は、インメモリ項目の SQL SELECT ロードよりも、DIRECT QUERY ロードを実行した方が素早くデータをロードできます。
データ インメモリとデータベース データとの違い
インメモリ データで関連付けを行う場合、DIRECT QUERY では大文字と小文字が区別されます。Direct Discovery は、クエリ対象のデータベース フィールドについて大文字と小文字の区別を行って、ソース データベースからデータを選択します。大文字と小文字を区別しないデータベース フィールドの場合、Direct Discovery のクエリは、インメモリのクエリが返さないデータを返す場合があります。大文字と小文字を区別しないデータベースに以下のデータが存在する場合、値 "Red" の Direct Discovery クエリは以下 4 つの行をすべて返します。
| ColumnA | ColumnB |
|---|---|
| 赤色 | 1 |
| 赤色 | 2 |
| 赤色 | 3 |
| 赤色 | 4 |
一方、"Red," のインメモリの選択は、以下のみを返します。
Red two
Qlik Sense は、データベースが合致しない選択データで一致する値が生成されるまで、データを正規化します。その結果、インメモリ クエリは、Direct Discovery クエリよりも一致度が高い値を生成する場合があります。例えば、以下のテーブルでは、前後のスペースの位置により、数値 "1" に対する値が変化します。
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | 2 |
標準 Qlik Sense インメモリにデータがある ColumnA の [フィルター パネル] で "1" を選択すると、最初の 3 行が以下に関連付けられます。
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
[フィルター パネル] に Direct Discovery データが含まれる場合、"1" のデータ選択は "no_space" のみを関連付ける可能性があります。返される Direct Discovery データとの一致は、データベースにより異なります。例えば、"no_space" のみ返す場合もあれば、SQL Server のように "no_space" と "space_after" を返す場合もあります。
キャッシュおよび Direct Discovery
Qlik Sense のキャッシュは、クエリの選択状態および関連付けられたクエリの結果をメモリに保存します。同じ種類の選択が行われると、Qlik Sense は、ソース データのクエリを実行せずに、キャッシュのクエリを利用します。異なる選択を行うと、データ ソースで SQL クエリ を実行します。キャッシュされている結果は、ユーザー間で共有されます。
-
最初の選択を適用した場合
SQL は、基底のデータ ソースに渡されます。
-
選択をクリアし、最初の選択と同じ選択を適用した場合
キャッシュ結果が返され、SQL は基底データ ソースには渡されません。
-
異なる選択を適用した場合
SQL は、基底のデータ ソースに渡されます。
DirectCacheSeconds システム変数を使用して、キャッシュに制限時間を設定できます。制限時間が経過すると、Qlik Sense は、前の選択で生成された Direct Discovery クエリの結果のキャッシュをクリアします。そして、Qlik Sense は選択用にソース データのクエリを実行し、指定した制限時間でキャッシュを再び作成します。
Direct Discovery クエリ結果のキャッシュ時間はデフォルトで 30 分間に設定されていますが、DirectCacheSeconds のシステム変数が使用されている場合は該当しません。