
組み込みとベクターデータベースを使用して電話レビューをインデックス化する
このジョブは、フォルダー内の電話レビューのテキストファイルを読み込み、分析しやすいように内容を小さなチャンクに分割し、Azure OpenAIを使用してベクターの組み込みを生成し、それらをPineconeのベクターデータベースに保存することで、セマンティック検索を可能にします。
始める前に
このジョブを実行する前に、次を確認してください。
- text-embedding-3-smallモデルへのアクセス権を持つ、アクティブなAzure OpenAIアカウントがあること。
- Azure OpenAI APIキーとエンドポイントが設定されていること。
- 組み込み保存用の インデックスが作成されたPineconeアカウントがあること。
- Pinecone APIキーとホストエンドポイントが設定されていること。
- アーカイブファイルtembeddingai-tpineconeclient_phone-review-files.zipをダウンロードし、LG.txtおよびIphones.txtファイルを解凍していること。
- 電話レビューのテキストファイルを含むディレクトリ<folder_path>/phone-reviews/を作成していること。
コンポーネントのリンク
手順
-
Row > FLOW接続を使用してtPineconeClientを最後のtLogRowに接続します。
コンポーネントの設定
このタスクについて
手順
-
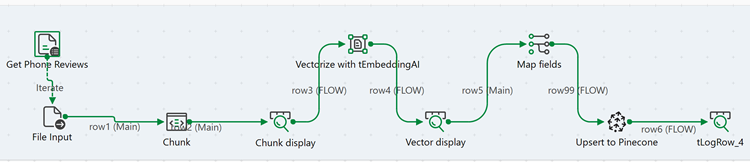
[基本設定]タブで、次のパラメーターを設定します。
- [スキーマを編集]をクリックし、スキーマに組み込み(リスト)のカラムがあることを確認します。
- [プラットフォーム]リストから[Azure OpenAI]を選択します。
- [モデル名]フィールドで[...]ボタンをクリックし、[text-embedding-3-small]を選択します。
- [トークン/APIキー]フィールドで[...]ボタンをクリックし、Azure OpenAI APIキーを入力して[OK]をクリックします。
- [Azureエンドポイント]フィールドに、Azure OpenAIのエンドポイントを入力します(例: https://your-resource-name.openai.azure.com/)。
- [組み込み用のカラム]リストで、[チャンク]を選択します。
このコンポーネントは、各電話レビューのテキストチャンクごとにベクターの組み込みを生成します。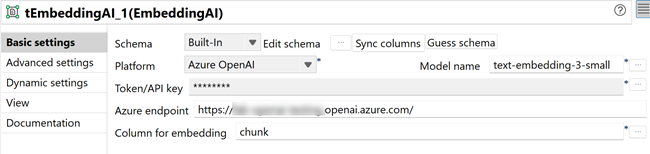
-
マップエディターで、次の列を持つ出力スキーマを作成します。
- id (文字列)
- vector(リスト) - 組み込み入力カラムにマッピングします
- text (文字列)
このマッピングにより、すべてのメタデータがtPineconeClientに正しく転送されていることが確認されます。idおよびvaluesカラムは、Pineconeでのアップサート操作に必須です。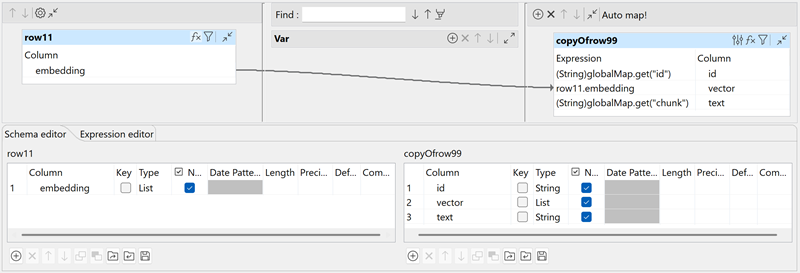
-
[基本設定]タブで、次のパラメーターを設定します。
- [スキーマを編集]をクリックし、スキーマにupsertedCount(Int)のカラムがあることを確認します。
- [APIキー]フィールドで[...]ボタンをクリックし、Pinecone APIキーを入力して[OK]をクリックします。
- [ホスト]フィールドに、Pineconeインデックスのホストを入力してください(例: "your-index-name.svc.environment.pinecone.io")。
- [操作]リストで[アップサーと]を選択し、ベクター化された電話レビューデータをPineconeインデックスにロードします。
- [ネームスペース]フィールドにネームスペース名(例: phones)を入力するか、空欄のままにしてデフォルトのネームスペースを使用します。
ジョブを実行
手順
- Ctrl + Sを押してジョブを保存します。
- F6を押してジョブを実行します。
タスクの結果
このジョブは、電話レビューファイルを読み込み、テキストを分割し、Azure OpenAIを使用して組み込みを生成し、tMapを介してメタデータの転送を確認し、ベクター化されたデータをPineconeにアップサートしてセマンティック検索に利用します。
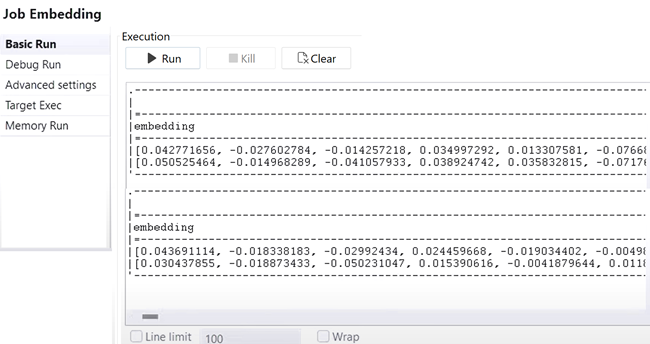
Pineconeに保存されている電話レビューの組み込みデータによりセマンティック検索クエリが可能になり、ユーザーは厳密なキーワード一致ではなく、意味とコンテキストに基づいて関連性の高いレビューを見つけることができます。テキストをチャンキングすることで、より正確な検索結果と優れた分析機能が実現します。