Utiliser des variables de contexte avec Cloudera
Dans ce scénario, vous devez choisir où exécuter vos Jobs Spark parmi les Runtimes Cloudera on-premises 7.1.7 avec Spark 3.2.x et 7.1.9 avec Spark 3.3.x.
Vous pouvez également choisir un mélange de distributions Cloudera on-premises (7.1.x) et Cloud (7.2.x).
Cette fonctionnalité est activée avec la fonctionnalité de variables de contexte du Studio Talend et avec le mode de distribution de Qlik Spark Universal 3.3.x (le plus récent des distributions Cloudera).
Avant de commencer
- Consultez la documentation Cloudera (uniquement en anglais) (en anglais) pour voir si vos distributions cibles sont compatibles avec Spark 2, Spark 3 ou avec les deux à la fois.
- Depuis Cloudera Manager, téléchargez la configuration du client pour chaque service Hadoop utilisé (HDFS, Hive, HBase...). Pour plus d'informations, consultez Downloading Client Configuration Files (uniquement en anglais) (en anglais), dans la documentation Cloudera.
Créer une métadonnée de connexion à un cluster Hadoop
Procédure
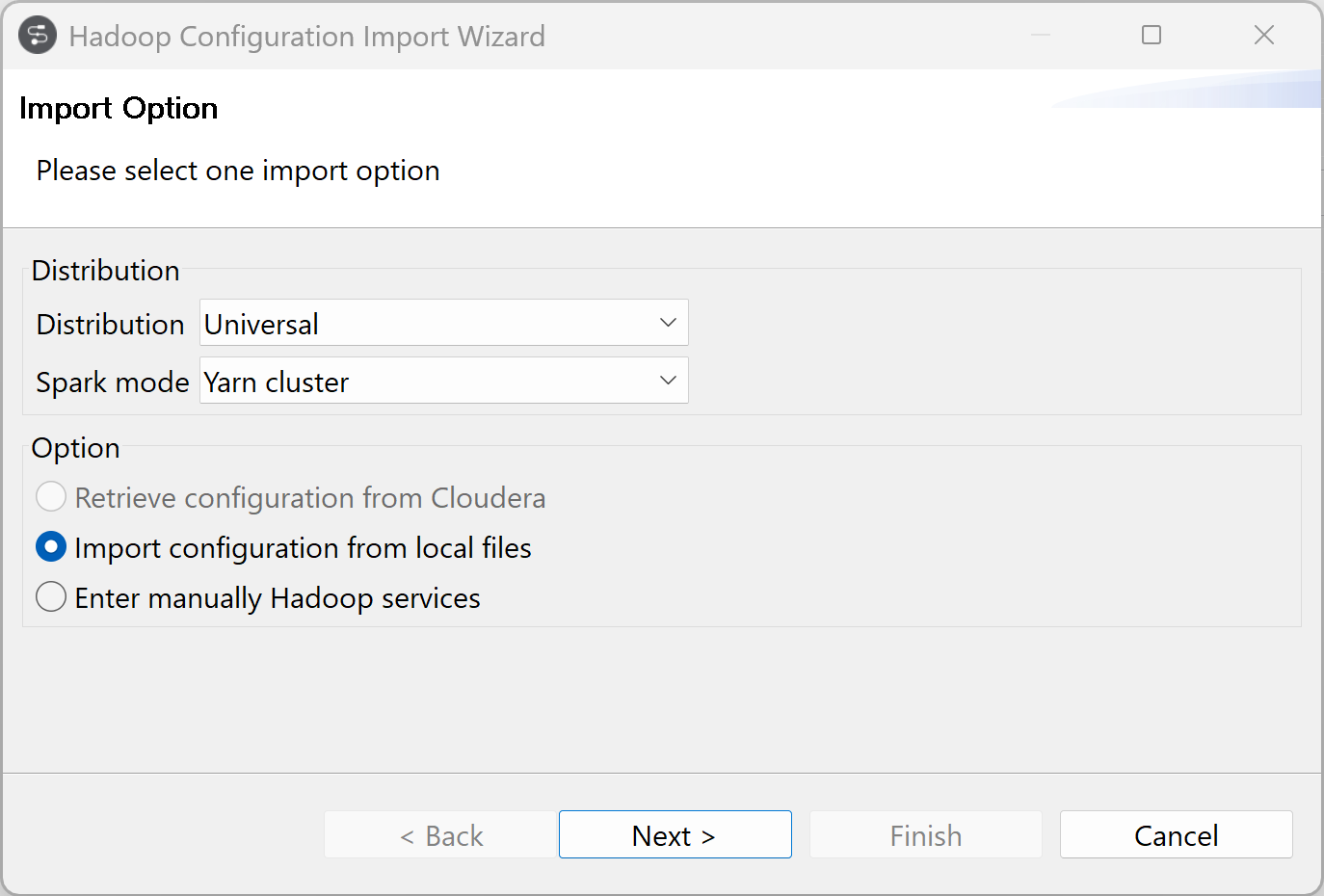
-
Sélectionnez votre distribution, Universal dans cet exemple, et sélectionnez le mode Spark, Yarn cluster (Cluster YARN) dans cet exemple.
Importer une configuration Hadoop
Procédure
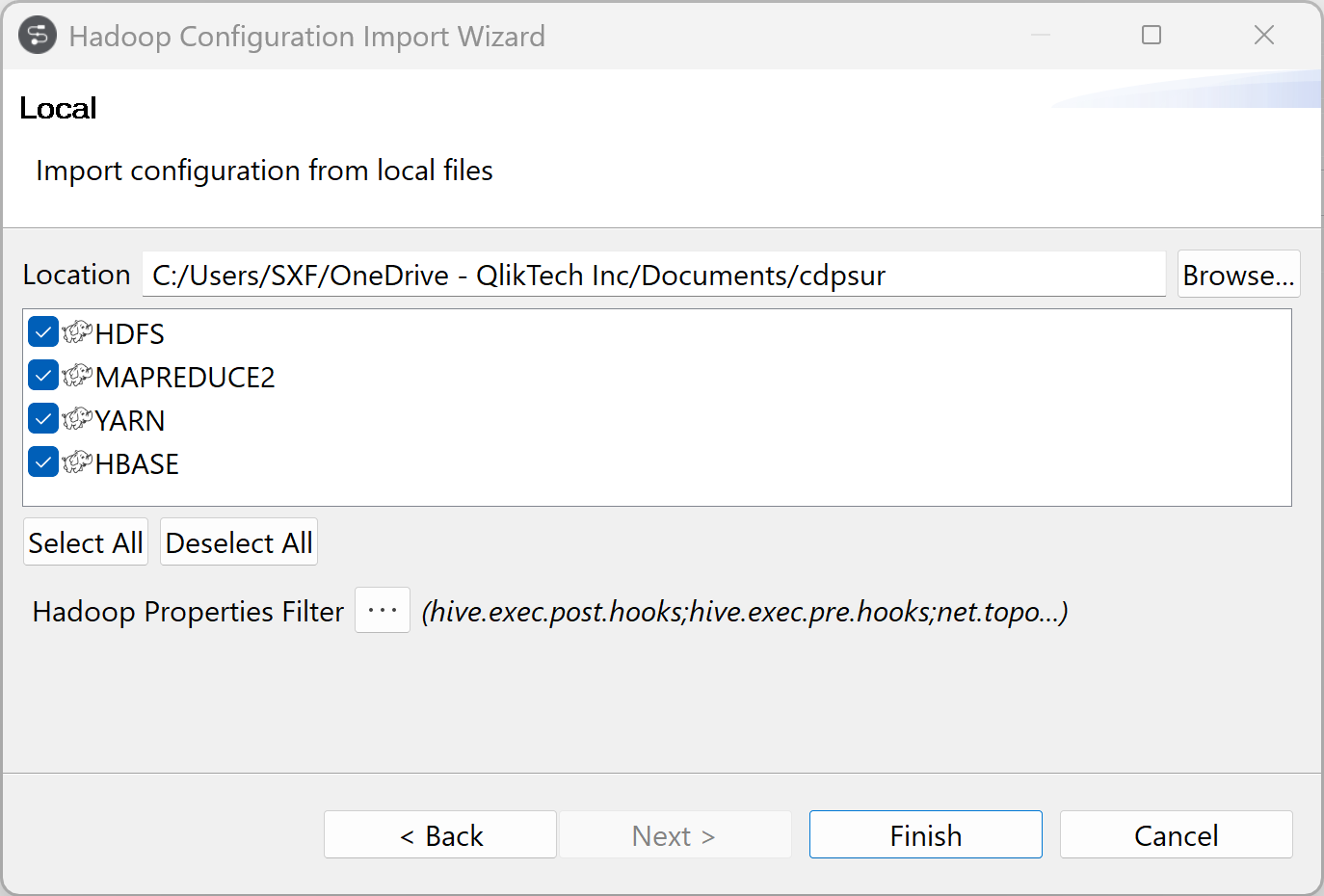
-
Spécifiez l'emplacement de vos configurations clients et cliquez sur Finish (Terminer).
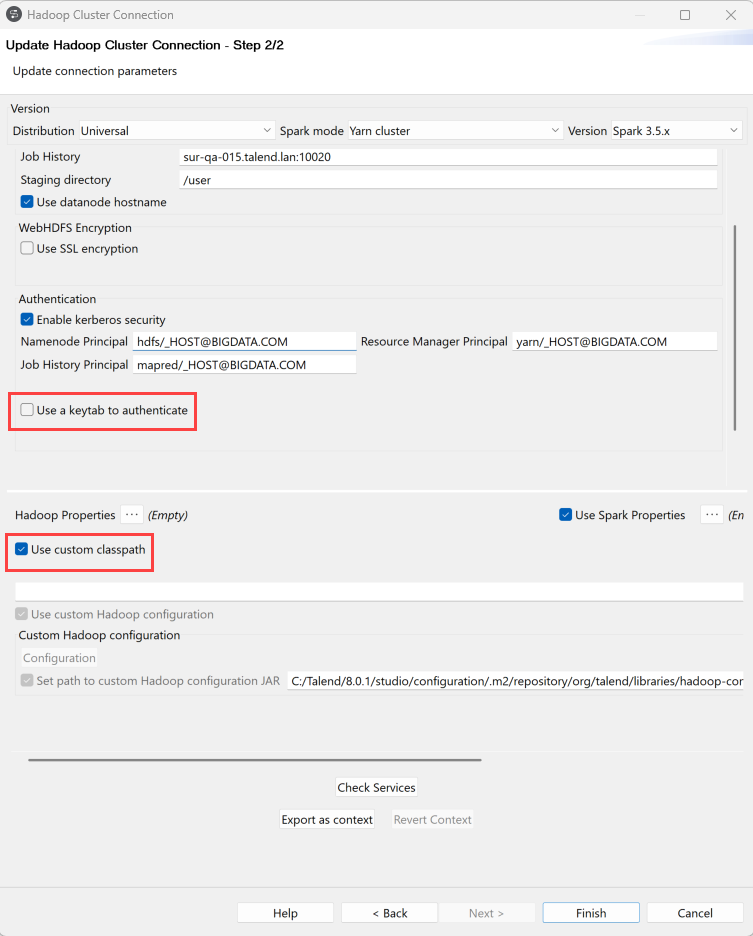
-
Dans l'onglet Update connection parameters (Mettre à jour les paramètres de connexion), les paramètres par défaut sont déjà renseignés.
Cependant, si besoin, vous pouvez :
- cocher la case Use a key tab to authenticate (Utiliser un Keytab pour s'authentifier), pour vous authentifier à un cluster Hadoop,
- cocher la case Use custom classpath (Utiliser un classpath personnalisé) pour définir le classpath Cloudera à exécuter. Dans ce cas, spécifiez les bibliothèques Spark 2 ou Spark 3.
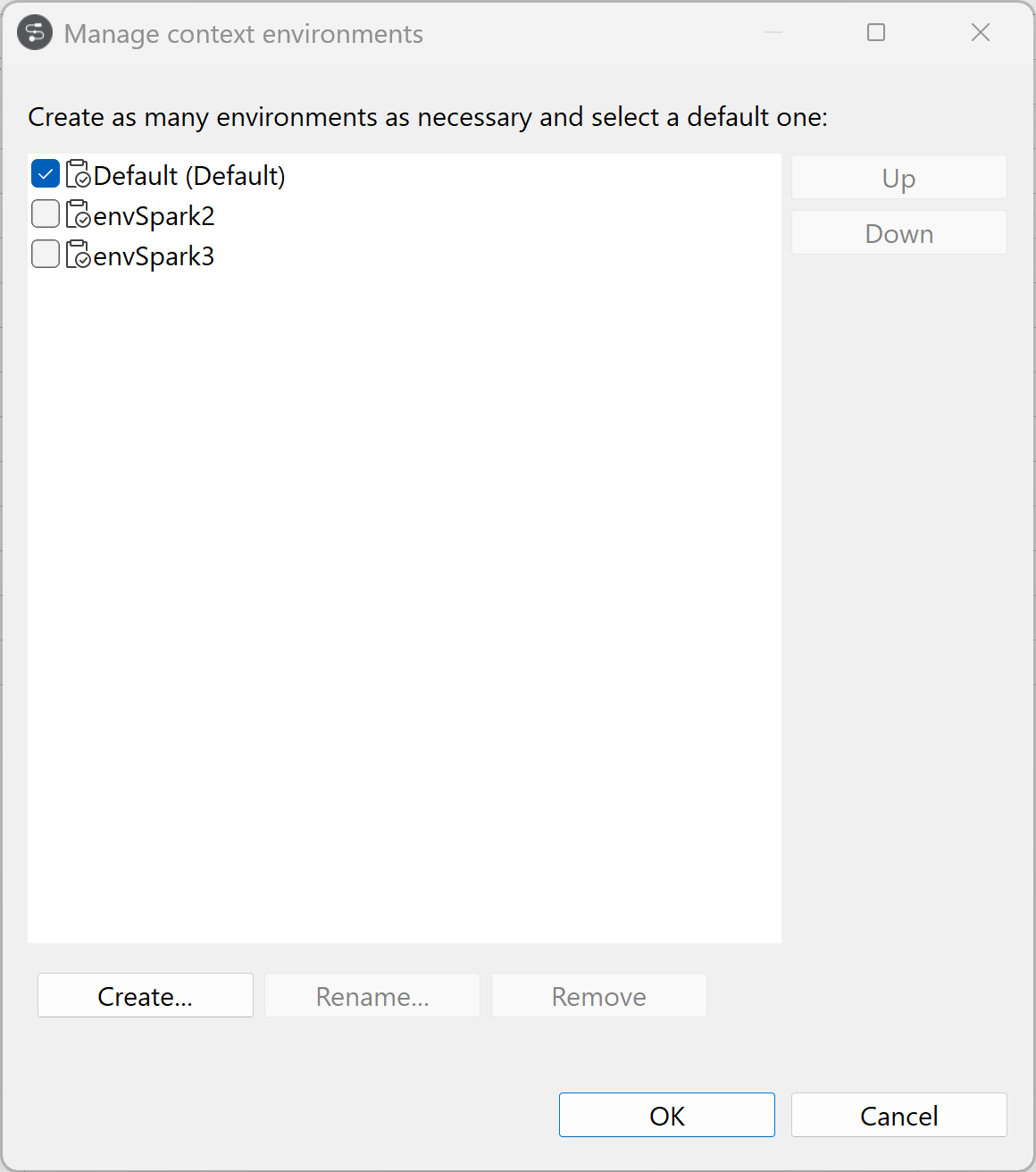
Contextualiser la métadonnée de connexion
Vous pouvez utiliser un seul cluster avec différents paramètres, grâce aux valeurs de contexte.
Procédure
-
Cliquez sur Manage environments (Gérer les environnements) pour créer autant d'environnements que nécessaire et en sélectionner un par défaut.
Dans cet exemple, cliquez sur Create (Créer) pour ajouter un environnement Spark 2 et un environnement Spark 3.