
Générer un Job identifiant les valeurs en doublon d'une colonne analysée
Lorsque vous utilisez la perspective Profiling pour analyser une colonne dans une table de base de données pour fournir des statistiques simples sur le nombre de valeurs distinctes, uniques et en doublon, vous pouvez générer ultérieurement un Job prêt à l'emploi pour supprimer les valeurs en doublon dans la colonne spécifiée.
Avant de commencer
Procédure
-
Cliquez sur le nom de la colonne analysée dans laquelle vous souhaitez séparer les valeurs uniques et en doublon, puis cliquez sur Simple Statistics pour développer la section des statistiques simples.

-
Dans la liste Label, cliquez-droit sur Distinct Count, Unique Count ou Duplicate Count et sélectionnez Identify duplicates dans le menu contextuel.
La perspective Integration s'ouvre dans le Studio Talend et affiche le Job généré avec les composants correspondants.
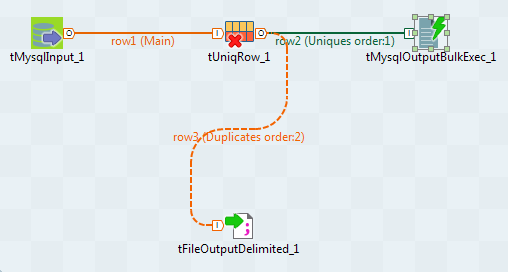
Le composant d'entrée de base de données et le composant tUniqueRow sont déjà configurés selon votre connexion et la colonne que vous analysez.
Les deux composants de sortie sont des composants de fichier, dans ce Job prêt à l'emploi, mais vous pouvez les remplacer par des composants de sortie de bases de données pour écrire les valeurs en doublon et distinctes directement dans la base de données souhaitée.
-
Pour configurer les deux composants de sortie :
-
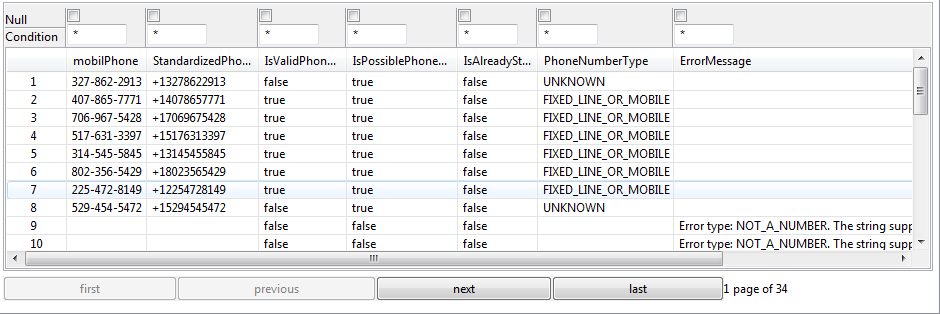
Si nécessaire, cliquez-droit sur tFileOutputdelimited dans le Job généré et sélectionnez Data Viewer.
Un aperçu des données standardisées s'ouvre dans Studio Talend.
-
Si nécessaire, cliquez-droit sur tFileOutputdelimited dans le Job généré et sélectionnez Data Viewer.