
Nouvelles fonctionnalités
Intégration d'application
| Fonctionnalité | Description |
|---|---|
| Support de la navigation des détails des contrats d'API REST dans le référentiel | Vous pouvez désormais développer les entrées de définitions de l'API REST dans la vue en arborescence Repository (Référentiel) pour parcourir la structure complète de vos contrats d'API sans quitter le Studio Talend. Le nœud de contrat développé affiche les éléments suivants :
|
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de CDP Private Cloud Base 7.3.2 avec Spark 3.5.x | Vous pouvez désormais exécuter vos Jobs Spark sur un cluster CDP Private Cloud Base 7.3.2 à l'aide de Spark Universal avec Spark 3.x en mode Cloudera Private Cloud. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lors de l'utilisation de Kudu avec CDP Private Cloud Base 7.3.2, sélectionnez Kudu version 1.17.  |
| Support de Databricks 17.3 LTS avec Spark Universal 4.x dans les Jobs Spark Batch | Vous pouvez désormais exécuter vos Jobs Spark Batch sur des clusters de Jobs et des clusters universels Databricks, sur AWS et Azure, à l'aide de Spark Universal avec Spark 4.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec Databricks 17.3 LTS. 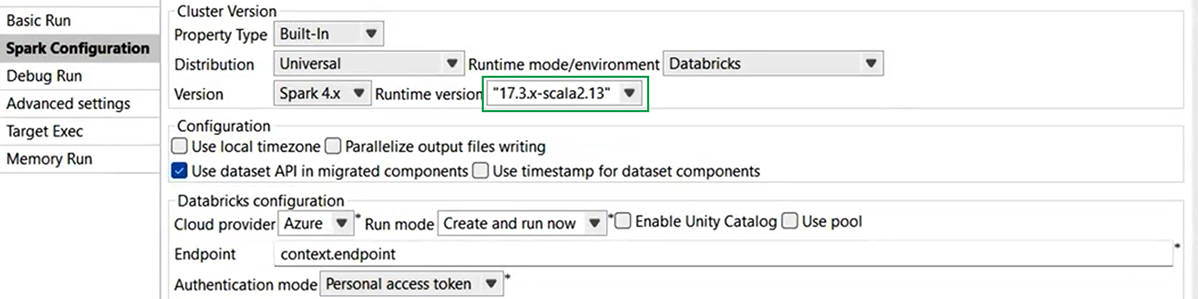 |
Intégration continue
| Fonctionnalité | Description |
|---|---|
|
Mise à niveau du CI Builder (Builder d'intégration continue) Talend à la version 8.0.32 |
Le CI Builder (Builder d'intégration continue) Talend a été mis à niveau à la version 8.0.32 Utilisez le Builder Talend d'intégration continue 8.0.32 dans vos commandes d'intégration continue ou dans vos scripts de pipelines, à partir de cette version mensuelle et jusqu'à la sortie d'une nouvelle version du Builder Talend d'intégration continue. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
| Support du mode transactionnel pour le tKafkaOutput dans les Jobs standards | Le composant tKafkaOutput supporte désormais le mode transactionnel pour utiliser des transactions Kafka pour une distribution exactly-once (une seule fois), un rollback en cas d'échec et des commits de messages groupés. |
| Support du mode de chargement du répertoire pour le tQlikOutput dans les Jobs standards | Le composant tQlikOutput supporte désormais un mode Directory Upload (Chargement du répertoire) pour charger tous les fichiers valides d'un répertoire local sélectionné dans Qlik Cloud. Les fichiers des sous-répertoires sont ignorés. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Support de l'annotation @emit dans l'éditeur de map DSQL | L'annotation @emit est désormais disponible dans les maps DSQL. Cette annotation contrôle si un champ de sortie est produit ou non en fonction d'une condition spécifiée. Elle est placée avant une instruction d'attribution et nécessite le paramètre condition. Si la condition est évaluée sur true, le champ de sortie est produit ; si elle est évaluée sur false, le champ est omis de la sortie. Dans cet exemple, le champ rating est inclus dans la sortie uniquement lorsqu'il a une valeur : |
| Support de la fonction getMapProperty dans les maps DSQL | La fonction getMapProperty est désormais disponible dans les maps DSQL. Cette fonction est utile dans les Routes incluant le composant cMap, pour accéder aux en-têtes d'échanges entrants et dans un Job incluant le tHMap pour accéder aux variables de contexte automatiquement définies comme des propriétés d'exécution. |
| Support de la bibliothèque Dataset dans le tHMapFile | Le composant tHMapFile supporte désormais la bibliothèque Dataset, permettant une meilleure optimisation et de meilleures performances. |
| Support de Spark 4 dans le tHMapFile | Vous pouvez désormais utiliser le composant tHMapFile avec Spark 4. |
Qualité de données
| Fonctionnalité | Description |
|---|---|
| Support de Databricks 17.3 LTS avec Spark Universal 4.x dans les Jobs Spark Batch | Vous pouvez désormais exécuter des Jobs Spark Batch utilisant des composants Qualité des données sur des clusters de Jobs et des clusters Databricks universels, sur AWS et Azure, à l'aide de Spark Universal avec Spark 4.x. Pour plus d'informations, consultez la section Big Data. |
|
Support du schéma JSON dans le tSchemaComplianceCheck |
Le composant tSchemaComplianceCheck standard supporte désormais la validation des données par rapport à un schéma JSON. |