
Neue Funktionen
Anwendungsintegration
| Funktion | Beschreibung |
|---|---|
| Unterstützung für das Durchsuchen der REST API-Vertragsdetails im Repository | Sie können jetzt REST API-Definitionseinträge in der Baumstrukturansicht Repository erweitern, um die vollständige Struktur Ihrer API-Verträge zu durchsuchen, ohne Talend Studio zu verlassen. Der erweiterte Vertragsknoten zeigt:
|
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für CDP Private Cloud Base 7.3.2 mit Spark 3.5.x | Sie können Ihre Spark-Jobs jetzt in einem CDP Private Cloud Base 7.3.2-Cluster unter Verwendung von Spark Universal mit Spark 3.x im Modus Cloudera Private Cloud ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie Kudu mit CDP Private Cloud Base 7.3.2 verwenden, wählen Sie Kudu Version 1.17 aus.  |
| Unterstützung für Databricks 17.3 LTS mit Spark Universal 4.x in Spark Batch-Jobs | Sie können Ihre Spark Batch-Jobs jetzt in jobbasierten und in multifunktionalen Databricks-Clustern in AWS und Azure unter Verwendung von Spark Universal mit Spark 4.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Databricks 17.3 LTS kompatibel. 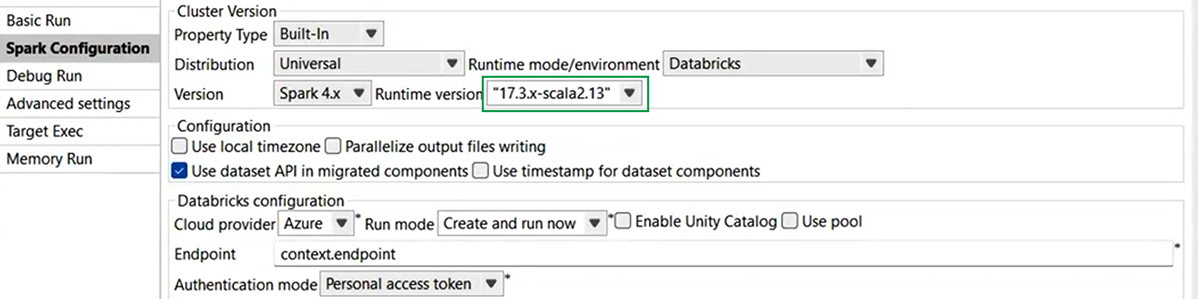 |
Kontinuierliche Integration (CI = Continuous Integration)
| Funktion | Beschreibung |
|---|---|
|
Upgrade von Talend CI Builder auf Version 8.0.32 |
Talend CI Builder wird auf Version 8.0.32 aktualisiert. Verwenden Sie ab dieser monatlichen Version Talend CI Builder 8.0.32 in Ihren CI-Befehlen (Continuous Integration: Kontinuierliche Integration) oder Pipeline-Skripten bis zur Veröffentlichung einer neuen Version von Talend CI Builder. |
Datenintegration
| Funktion | Beschreibung |
|---|---|
| Unterstützung für den transaktionalen Modus für tKafkaOutput in Standard-Jobs | Die Komponente tKafkaOutput unterstützt jetzt den transaktionalen Modus für die Verwendung von Kafka-Transaktionen für genau einmalige Zustellung, Rollback bei Fehler und gruppierten Nachrichtenübergaben. |
| Unterstützung für den Verzeichnis-Upload-Modus für tQlikOutput in Standard-Jobs | Die Komponente tQlikOutput unterstützt jetzt einen Verzeichnis-Upload-Modus zum Hochladen aller gültigen Dateien aus einem ausgewählten lokalen Verzeichnis an Qlik Cloud. Dateien in Unterverzeichnissen werden ignoriert. |
Data Mapper
| Funktion | Beschreibung |
|---|---|
| Unterstützung für die Annotation @emit im DSQL Map Editor | Die Annotation @emit ist jetzt in DSQL-Maps verfügbar. Diese Annotation steuert, ob ein Ausgabefeld basierend auf einer angegebenen Bedingung erzeugt wird. Sie wird vor einer Zuweisungsanweisung platziert und erfordert den Parameter condition Wenn die Bedingung als true ausgewertet wird, wird das Ausgabefeld erzeugt; bei false wird das Feld in der Ausgabe ausgelassen. In diesem Beispiel wird das Feld rating nur in die Ausgabe eingeschlossen, wenn es einen Wert enthält: |
| Unterstützung für die Funktion getMapProperty in DSQL-Maps | Die Funktion getMapProperty ist jetzt in DSQL-Maps verfügbar. Diese Funktion ist in Routen mit der Komponente cMap nützlich, um auf eingehende Exchange-Header zuzugreifen, sowie in Jobs mit tHMap, um auf Kontextvariablen zuzugreifen, die automatisch als Ausführungseigenschaften festgelegt werden. |
| Unterstützung für die Datensatzbibliothek in tHMapFile | Die Komponente tHMapFile unterstützt jetzt die Datensatzbibliothek für bessere Optimierung und Leistung. |
| Unterstützung für Spark 4 in tHMapFile | Sie können jetzt die Komponente tHMapFile mit Spark 4 verwenden. |
Datenqualität
| Funktion | Beschreibung |
|---|---|
| Unterstützung für Databricks 17.3 LTS mit Spark Universal 4.x in Spark Batch-Jobs | Sie können die Spark Batch-Jobs jetzt mithilfe von Datenqualitätskomponenten in jobbasierten und in multifunktionalen Databricks-Clustern in AWS und Azure unter Verwendung von Spark Universal mit Spark 4.x ausführen. Weitere Informationen finden Sie im Abschnitt „Big Data“. |
|
Unterstützung für das JSON-Schema in tSchemaComplianceCheck |
Die Standardkomponente tSchemaComplianceCheck unterstützt jetzt das Validieren von Daten anhand eines JSON-Schemas. |