
新しい機能
アプリケーションインテグレーション
| 機能 | 説明 |
|---|---|
| リポジトリー内でのREST APIコントラクト詳細の閲覧のサポート | リポジトリーのツリービュー内でREST APIの定義エントリを展開し、Talend Studioを離れることなく、APIコントラクトの全体構造を閲覧できるようになりました。展開されたコントラクトノードには、次が表示されます。
|
ビッグデータ
| 機能 | 説明 |
|---|---|
| Spark 3.5.xでCDP Private Cloud Base 7.3.2をサポート | Cloudera Private Cloudモードにおいて、Spark 3.xを搭載したSpark Universalを使用し、CDP Private Cloud Base 7.3.2クラスター上でSparkジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 CDP Private Cloud Base 7.3.2でKuduを使用する場合は、Kuduバージョン1.17を選択してください。 ![Spark Batchジョブの[Spark Configuration] (Spark設定)ビュー。](/talend/ja-JP/release-notes/8.0/Content/Resources/images/cdp-732-spark-universal-3-x.png) |
| Spark BatchジョブにおけるSpark Universal 4.x対応のDatabricks 17.3 LTSのサポート | AWSおよびAzureのジョブクラスターまたは汎用Databricksクラスターにおいて、Spark Universal(Spark 4.x 搭載)を使用してSpark Batchジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはDatabricks 17.3 LTSバージョンと互換性を持つようになります。 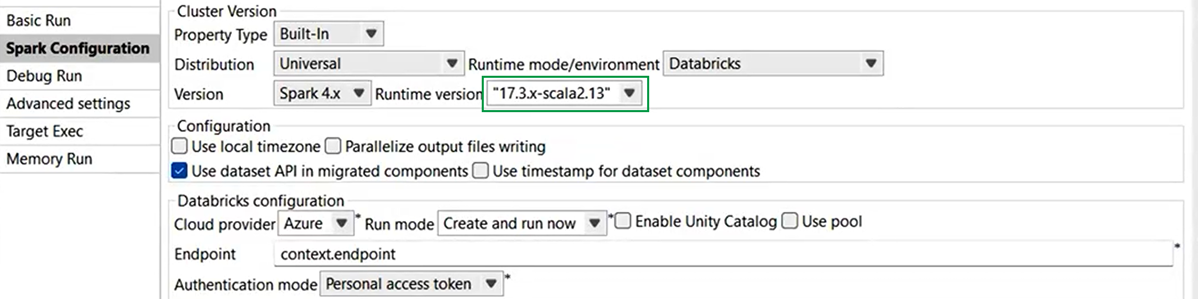 |
継続的インテグレーション
| 機能 | 説明 |
|---|---|
|
Talend CI Builderをバージョン8.0.32にアップグレード |
Talend CI Builderをバージョン8.0.32にアップグレード このマンスリーバージョン以降、Talend CI Builderの新しいバージョンがリリースされるまでCIコマンドやパイプラインスクリプトでTalend CI Builder 8.0.32を使用します。 |
データ統合
| 機能 | 説明 |
|---|---|
| Standard JobsにおけるtKafkaOutputのトランザクションモードのサポート | tKafkaOutputコンポーネントがトランザクションモードをサポートするようになり、Kafkaトランザクションを使用してExactly-once配信、失敗時のロールバック、グループ化されたメッセージのコミットが可能になりました。 |
| 標準ジョブにおけるtQlikOutputのディレクトリアップロードモードのサポート | tQlikOutputコンポーネントがディレクトリアップロードモードをサポートするようになり、指定したローカルディレクトリ内の有効なファイルをすべてQlik Cloudへアップロードできるようになりました。サブディレクトリ内のファイルは対象外となります。 |
Data Mapper
| 機能 | 説明 |
|---|---|
| DSQLマップエディターでの@emitアノテーションのサポート | DSQLマップで、@emitアノテーションを利用できるようになりました。このアノテーションは、指定された条件に基づいて出力フィールドを生成するかどうかを制御します。代入文の前に配置され、conditionパラメーターを必須とします。条件が真(true)と評価された場合、出力フィールドが生成されます。偽(false)と評価された場合は、そのフィールドは出力から除外されます。 この例では、評価フィールドは、値を持つ場合にのみ出力に含まれます。 |
| DSQLマップにおけるgetMapPropertyファンクションのサポート | DSQLマップで、getMapPropertyファンクションを利用できるようになりました。このファンクションは、cMapコンポーネントを含むルートでエクスチェンジのインバウンドヘッダーにアクセスする場合や、tHMapを含むジョブで実行プロパティとして自動設定されるコンテキスト変数にアクセスする場合に有用です。 |
| tHMapFileにおけるDatasetライブラリのサポート | tHMapFileコンポーネントがDatasetライブラリをサポートし、より優れた最適化とパフォーマンスを実現しました。 |
| tHMapFileにおけるSpark 4のサポート | tHMapFileコンポーネントをSpark 4で使用できるようになりました。 |
データクオリティ
| 機能 | 説明 |
|---|---|
| Spark BatchジョブにおけるSpark Universal 4.x対応のDatabricks 17.3 LTSのサポート | Spark 4.xを搭載したSpark Universalを使用することで、AWSおよびAzure上のDatabricksジョブクラスターや汎用クラスターにおいて、Data Qualityコンポーネントを用いたSparkバッチジョブを実行できるようになりました。詳細については、ビッグデータセクションを参照してください。 |
|
tSchemaComplianceCheckにおけるJSONスキーマのサポート |
標準のtSchemaComplianceCheckコンポーネントが、JSONスキーマに基づくデータ検証をサポートするようになりました。 |