
Nouvelles fonctionnalités
Intégration d'application
| Fonctionnalité | Description |
|---|---|
| Nouvelle configuration des microservices pour écraser l'activation et la configuration de l'authentification | Vous pouvez à présent utiliser les paramètres dans des fichiers de propriétés supplémentaires afin d'écraser la configuration de l'authentification pour les types BASIC (basique) et JWT Bearer Token (Jeton Bearer JWT) dans les composants cREST et tRESTRequest. Cette configuration de sécurité et l'activation de l'endpoint Prometheus dans le fichier des propriétés peuvent être écrasées via l'utilisation du paramètre adéquat dans le Commandline, lors de l'exécution du microservice. Pour plus d'informations, consultez Exécuter un microservice. |
| Nouveau composant de Route disponible pour Azure Service Bus | Le composant cAzureServiceBus est à présent disponible dans les Routes, vous permettant d'envoyer des messages vers, ou de consommer des messages depuis Azure Service Bus. |
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de Dataproc 2.2 avec Spark Universal 3.x | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Google Dataproc, à l'aide de Spark Universal avec Spark 3.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec les versions 2.1 et 2.2 de Dataproc.
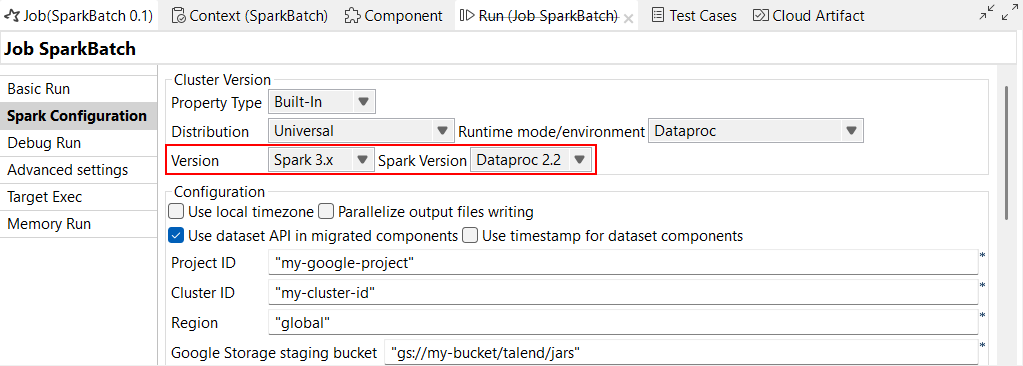 |
| Support de CDP Private Cloud Base 7.3.1 avec Spark Universal 3.x | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster CDP Private Cloud Base 7.3.1 avec la JDK 17, à l'aide de Spark Universal avec Spark 3.x en mode Yarn cluster (Cluster YARN). Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Avec la version bêta de cette fonctionnalité, les Jobs utilisant des composants Iceberg et Kudu ne fonctionnent pas. 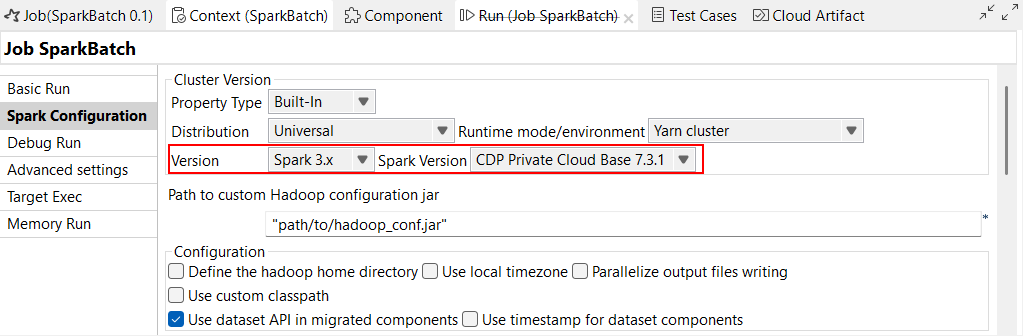 |
| Amélioration du composant tS3Configuration pour supporter les buckets multiples avec AssumeRole AWS | Vous pouvez à présent ajouter un rôle à plusieurs buckets dans votre Job, via l'option Assume Role (Endosser un rôle) dans le composant tS3Configuration. |
| Support de l'évolution du schéma dans le tIcebergTable dans les Jobs Spark Batch | De nouvelles actions sont à présent disponibles dans la propriété Action on table (Action sur la table) du composant tIcebergTable : Add columns (Ajouter des colonnes), Alter columns (Modifier des colonnes), Drop columns (Supprimer des colonnes), Rename columns (Renommer des colonnes) et Reorder columns (Réorganiser des colonnes).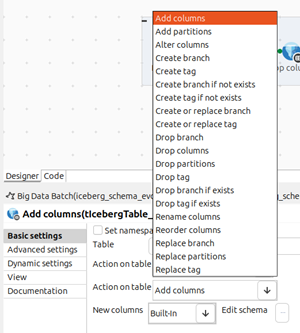 |
Intégration de données
| Fonctionnalité | Description |
|---|---|
|
Support des fonctionnalités d'API OData pour SAP dans les Jobs Standards |
Nouveaux composants SAP disponibles pour lire et écrire des données dans un service Web SAP OData :
|
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Éditeur de maps DSQL | Le support de l'éditeur de maps DSQL est à présent généralement disponible (GA). Le nouvel éditeur de maps DSQL vous permet de créer une map basée sur le langage Data Shaping Query Language. Comme pour les maps standards, vous pouvez créer des maps DSQL pour mapper un ou plusieurs fichier·s d'entrée à un ou plusieurs fichier·s de sortie, à l'aide des représentations supportées par les maps standards. Pour plus d'informations, consultez Différences entre les maps standards et DSQL. |
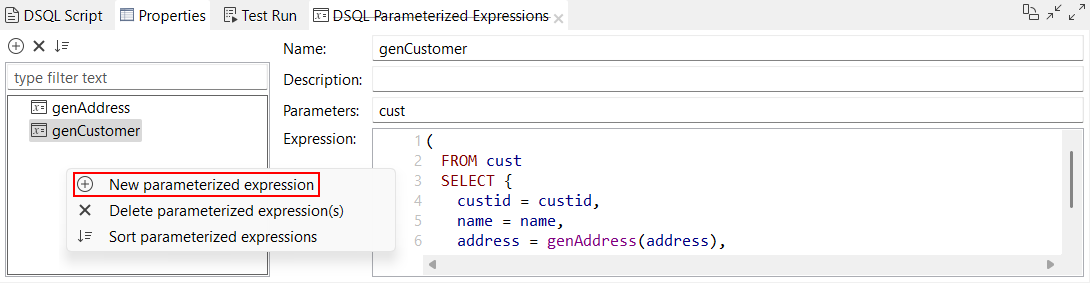
| Nouvelles options pour créer une expression paramétrée | De nouvelles options sont à présent disponibles dans l'éditeur de maps DSQL afin de créer une expression paramétrée :
|
| Nouvelle option pour stocker les résultats Test Run (Exécution de test) sur le système de fichiers dans les maps DSQL | Une nouvelle option, Execute Test Run to File (Lancer l'exécution de test vers fichier), est à présent disponible dans la vue Test Run (Exécution de test) de votre éditeur de maps DSQL. Elle vous permet d'enregistrer les résultats en sortie de votre map DSQL dans votre système de fichiers.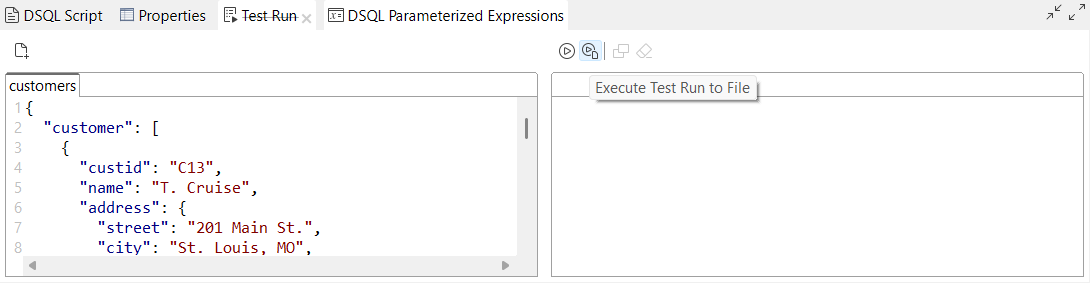 |
Qualité de données
| Fonctionnalité | Description |
|---|---|
| Valider des données à l'aide de règles de validation dans Qlik Talend Data Integration | Le nouveau composant tDQRules Standard vous permet de connecter le Studio Talend à Qlik Talend Data Integration et d'utiliser les règles de validation. |