
Neue Funktionen
Anwendungsintegration
| Funktion | Beschreibung |
|---|---|
| Neue Microservice-Konfiguration zum Überschreiben der Authentifizierungsaktivierung und -konfiguration | Sie können jetzt Parameter in einer zusätzlichen Eigenschaftendatei verwenden, um die Authentifizierungskonfiguration für BASIC- und JWT Bearer Token-Typen in cREST- und tRESTRequest-Komponenten zu überschreiben. Diese Sicherheitskonfiguration und die Prometheus-Endpunktaktivierung in der Eigenschaftendatei kann überschrieben werden, indem Sie den relevanten Parameter in der Befehlszeile verwenden, wenn Sie den Microservice ausführen. Weitere Informationen finden Sie unter Ausführen eines Microservice. |
| Neue Routenkomponente für Azure Service Bus verfügbar | Die cAzureServiceBus-Komponente ist jetzt in Routen verfügbar, sodass Sie Nachrichten an den Azure Service Bus senden bzw. von diesem empfangene Nachrichten nutzen können. |
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für Dataproc 2.2 mit Spark Universal 3.x | Sie können Ihre Spark-Jobs jetzt in einem Google Dataproc-Cluster unter Verwendung von Spark Universal mit Spark 3.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Dataproc Version 2.1 und 2.2 kompatibel.
 |
| Unterstützung für CDP Private Cloud Base 7.3.1 mit Spark Universal 3.x | Sie können Ihre Spark-Jobs jetzt in einem CDP Private Cloud Base 7.3.1-Cluster mit JDK 17 unter Verwendung von Spark Universal mit Spark 3.x im Yarn-Cluster-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Mit der Beta-Version dieser Funktion funktionieren Jobs mit Iceberg- und Kudu-Komponenten nicht. 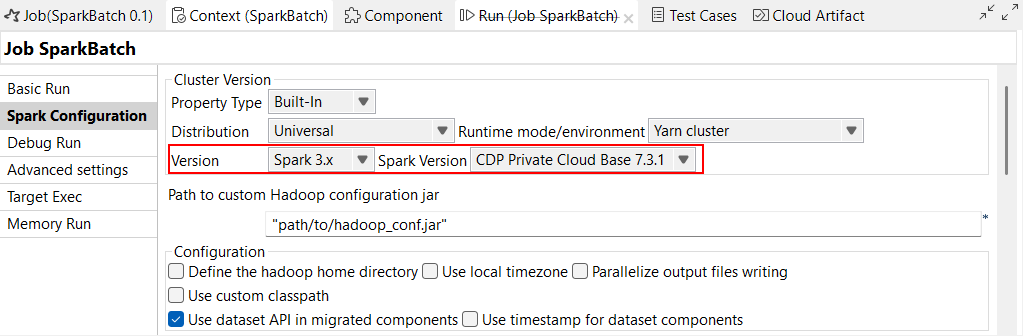 |
| Verbesserung der tS3Configuration zum Unterstützen von mehreren Buckets mit AWS Assume Role | Sie können jetzt eine Rolle zu mehreren Buckets in Ihrem Job mit Assume Role (Rolle annehmen) in der tS3Configuration-Komponente hinzufügen. |
| Unterstützung für Schemaentwicklung in tIcebergTable in Spark-Batch-Jobs | Neue Aktionen sind jetzt in der Eigenschaft Action on table (Aktion mit Tabellen) in der tIcebergTable-Komponente verfügbar: Add columns (Spalten hinzufügen), Alter columns (Spalten ändern), Drop columns (Spalten löschen), Rename columns (Spalten umbenennen) und Reorder columns (Spalten neu anordnen).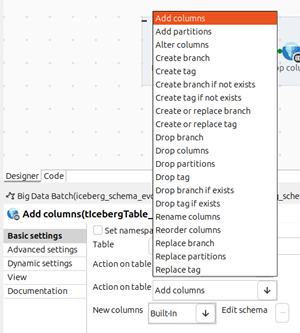 |
Datenintegration
| Funktion | Beschreibung |
|---|---|
|
Unterstützung für OData API-Funktionen für SAP in Standard-Jobs |
Neue SAP-Komponenten ermöglichen jetzt das Lesen und Schreiben von Daten in einem SAP OData-Webdienst:
|
Data Mapper
| Funktion | Beschreibung |
|---|---|
| DSQL-Map-Editor | Die Unterstützung für den DSQL-Map-Editor ist jetzt allgemein verfügbar (GA). Der DSQL-Map-Editor ermöglicht die Erstellung von Maps basierend auf Data Shaping Query Language. Sie können genau wie Standard-Maps auch DSQL-Maps erstellen, um eine oder mehrere Eingabedateien einer oder mehreren Ausgabedateien zuzuordnen. Dabei werden alle von den Standard-Maps unterstützten Darstellungen verwendet. Weitere Informationen finden Sie unter Unterschiede zwischen Standard- und DSQL-Maps. |
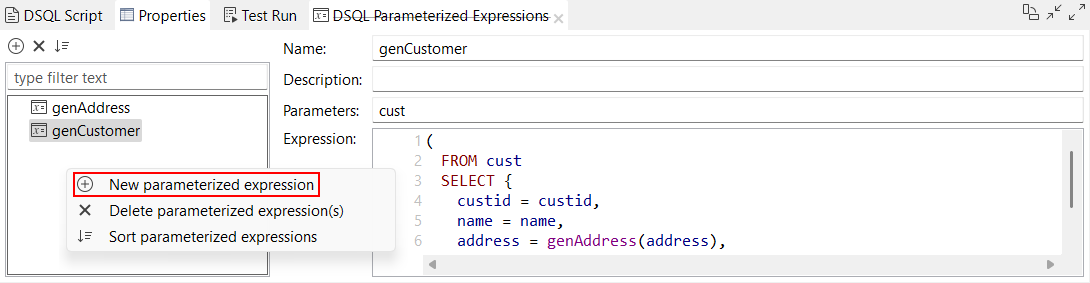
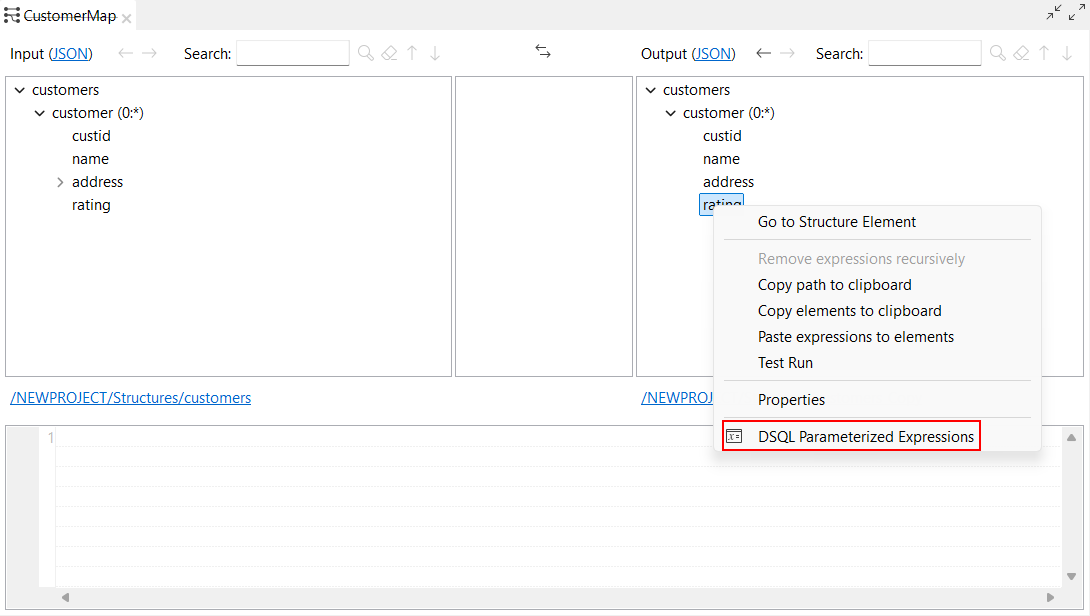
| Neue Optionen zum Erstellen eines neuen parametrisierten Ausdrucks | Neue Optionen sind jetzt im DSQL-Map-Editor zum Erstellen eines neuen parametrisierten Ausdrucks verfügbar:
|
| Neue Option zum Speichern der Ergebnisse von Test Run (Testausführung) im Dateisystem in DSQL-Maps | Die neue Option Execute Test Run to File (Testausführung in Datei ausführen) ist jetzt in der Ansicht Test Run (Testausführung) im DSQL-Map-Editor verfügbar. Damit können Sie die Ausgabeergebnisse Ihrer DSQL-Map im Dateisystem speichern.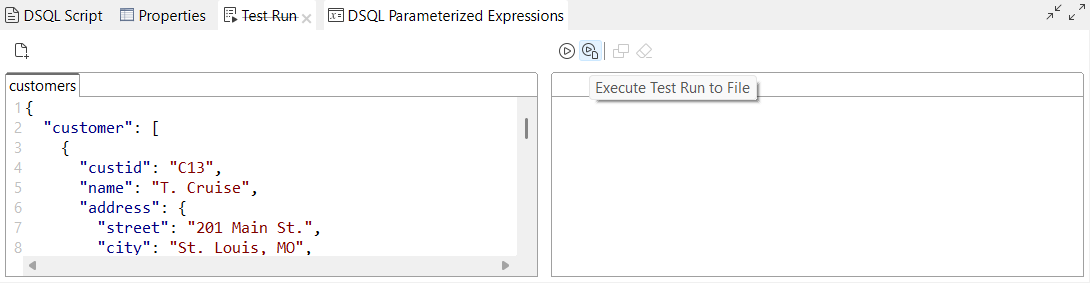 |
Datenqualität
| Funktion | Beschreibung |
|---|---|
| Validieren von Daten mithilfe von Validierungsregeln aus Qlik Talend Data Integration | Mit der neuen Standardkomponente tDQRules können Sie Talend Studio mit Qlik Talend Data Integration verbinden und Validierungsregeln verwenden. |