
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Support du Runtime Databricks 13.x avec Spark Universal 3.4.x | Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur des clusters de jobs et des clusters universels Databricks sur Google Cloud Platform (GCP), AWS et Azure, à l'aide de Spark Universal avec Spark 3.4.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 13.x de Databricks. 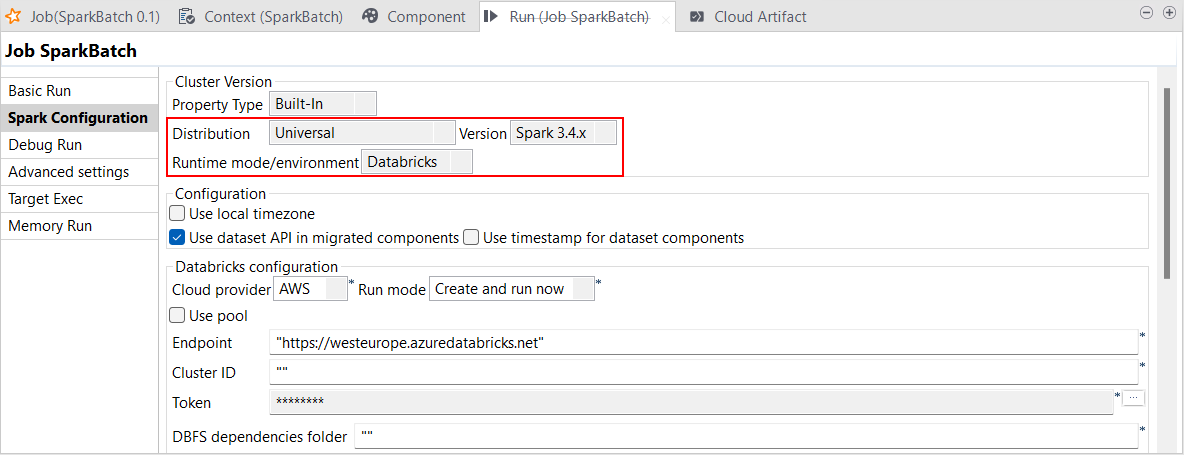 |
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de CDP Private Cloud Base 7.1.9 | Le Studio Talend supporte à présent CDP Private Cloud Base 7.1.9 avec Spark Universal 3.3.x dans les Jobs Spark Batch et Spark Streaming. |
Tous les produits Talend avec Big Data nécessitant souscription |
| Nouveau composant tIcebergCatalog dans les Jobs Standards | Le composant tIcebergCatalog est à présent disponible dans les Jobs Standards, vous permettant de configurer un catalogue personnalisé avec Hive ou Hadoop. Une nouvelle case Set catalog est également disponible dans la vue Basic settings (Paramètres simples) du tIcebergTable, vous permettant de spécifier un catalogue dans lequel créer la table. 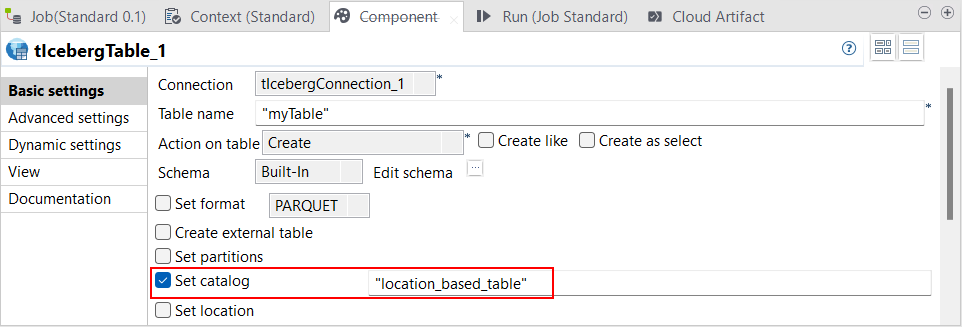 |
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de l'instruction INSERT OVERWRITE dans le tIcebergOutput, dans les Jobs Standards | Le tIcebergOutput supporte à présent l'instruction INSERT OVERWRITE dans les Jobs Standards. La nouvelle case Use insert overwrite (Utilise INSERT OVERWRITE) vous permet de remplacer toutes les données d'une table Iceberg, via l'option All rows from source table (Toutes les lignes de la table source), ou de remplacer les données d'une table Iceberg par le résultat d'une requête personnalisée à l'aide de l'option Use a custom query (Utiliser une requête personnalisée).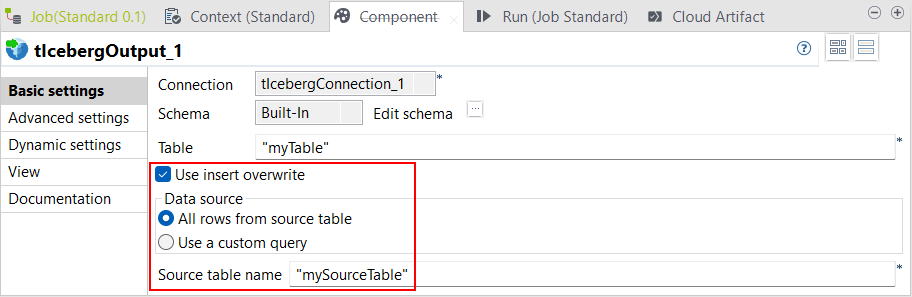 |
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de l'authentification via Azure Active Directory pour HDInsight | Le Studio Talend supporte à présent l'authentification via Azure Active Directory dans vos Jobs Spark Batch et Spark Streaming avec le stockage ADLS Gen2 et Azure. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Le Studio Talend est compatible avec :
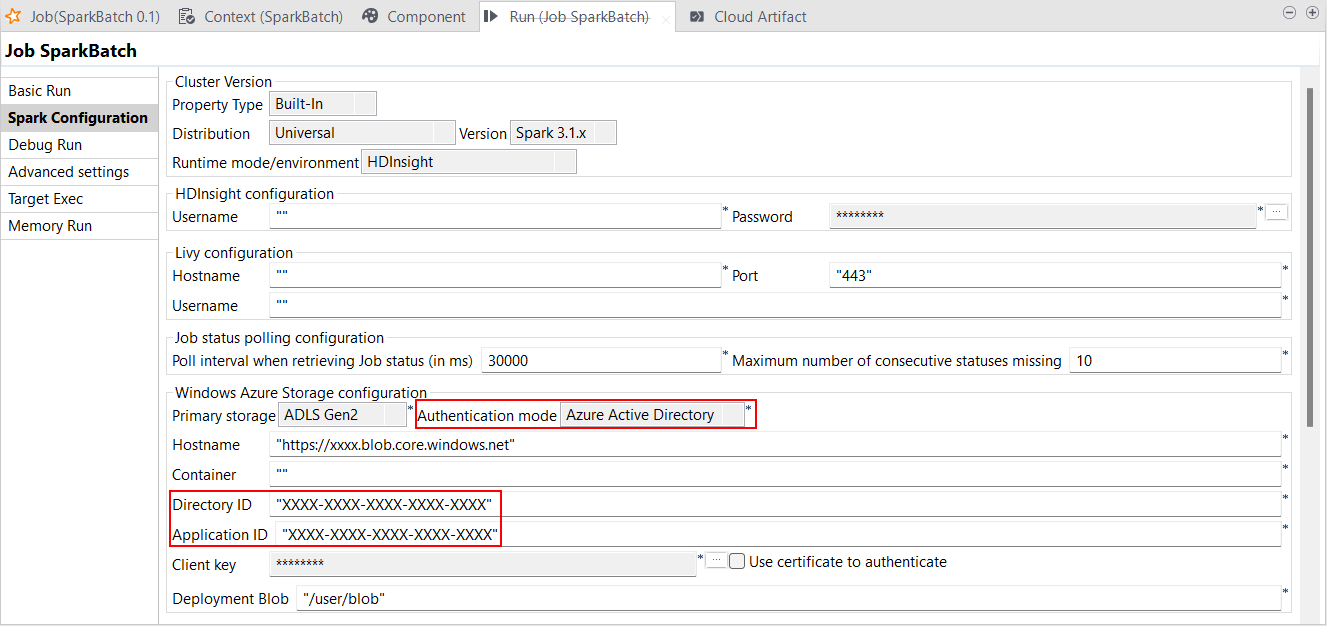 |
Tous les produits Talend avec Big Data nécessitant souscription |