
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für Databricks Runtime 13.x mit Spark Universal 3.4.x | Sie können Ihre Spark Batch- und Streaming-Jobs jetzt in jobbasierten wie auch in multifunktionalen Databricks-Clustern in Google Cloud Platform (GCP), AWS und Azure unter Rückgriff auf Spark Universal mit Spark 3.4.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Databricks 13.x kompatibel. 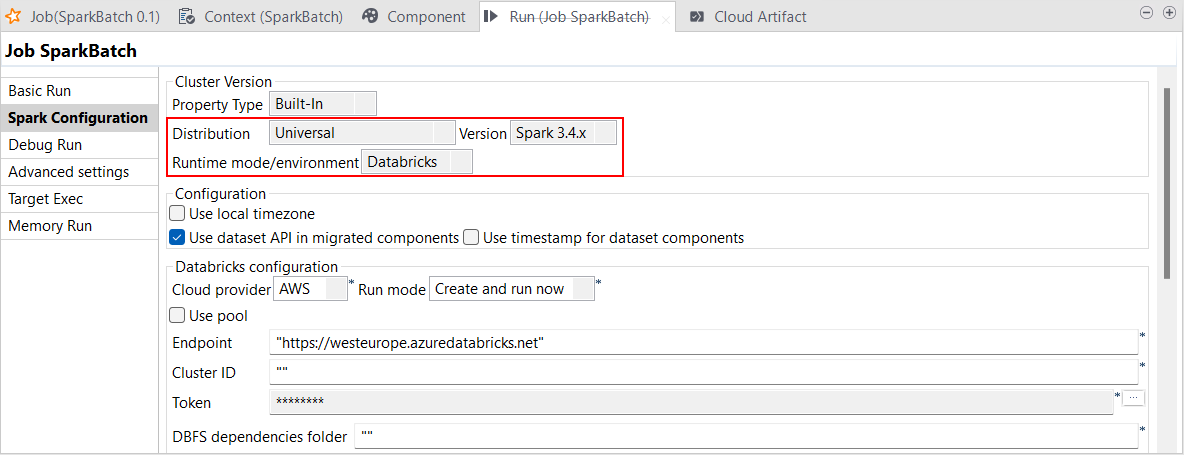 |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für CDP Private Cloud Base 7.1.9 | Talend Studio unterstützt jetzt CDP Private Cloud Base 7.1.9 mit Spark Universal 3.3.x in Spark Batch und Spark Streaming Jobs. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Neue tIcebergCatalog-Komponente in Standard-Jobs | Die tIcebergCatalog-Komponente ist jetzt für Ihre Standard-Jobs verfügbar und ermöglicht Ihnen das Konfigurieren eines benutzerdefinierten Katalogs mit Hive oder Hadoop. In tIcebergTable ist in der Ansicht Basic settings (Grundlegende Einstellungen) ein neues Kontrollkästchen Set catalog (Katalog festlegen) verfügbar, mit dem Sie einen Katalog angeben können, der zum Erstellen der Tabelleninformationen verwendet wird. 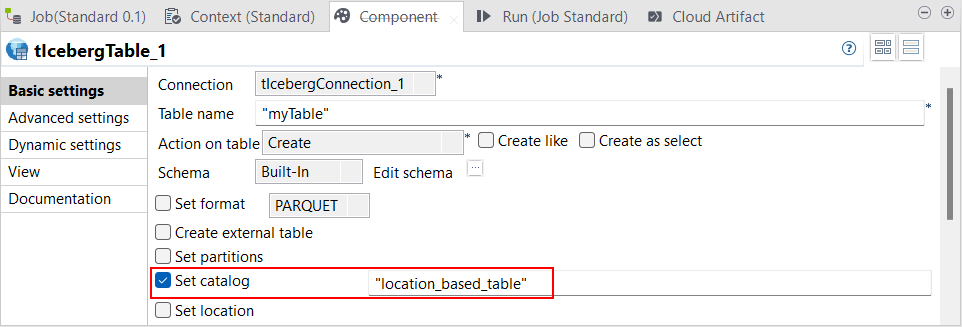 |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für INSERT OVERWRITE in tIcebergOutput in Standard-Jobs | tIcebergOutput unterstützt jetzt die Funktion INSERT OVERWRITE in Standard-Jobs. Mit dem neuen Kontrollkästchen Use insert overwrite (Einfügen und überschreiben verwenden) können Sie entweder alle Daten einer Iceberg-Tabelle mit der Option All rows from source table (Alle Zeilen aus der Quelltabelle) ersetzen, oder Sie können Daten in einer Iceberg-Tabelle mit dem Ergebnis einer benutzerdefinierten Abfrage mit der Option Use a custom query (Benutzerdefinierte Abfrage verwenden) ersetzen.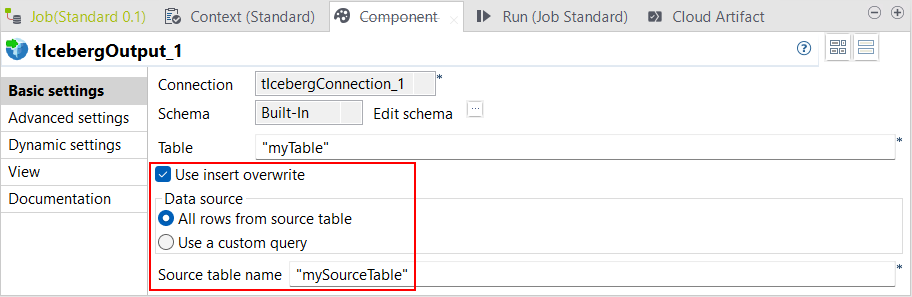 |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für die Azure Active Directory-Authentifizierung für HDInsight | Talend Studio unterstützt jetzt die Azure Active Directory-Authentifizierung in Ihren Spark Batch und Spark Streaming Jobs sowohl mit ADLS Gen2- als auch mit Azure-Speicher. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Talend Studio ist kompatibel mit:
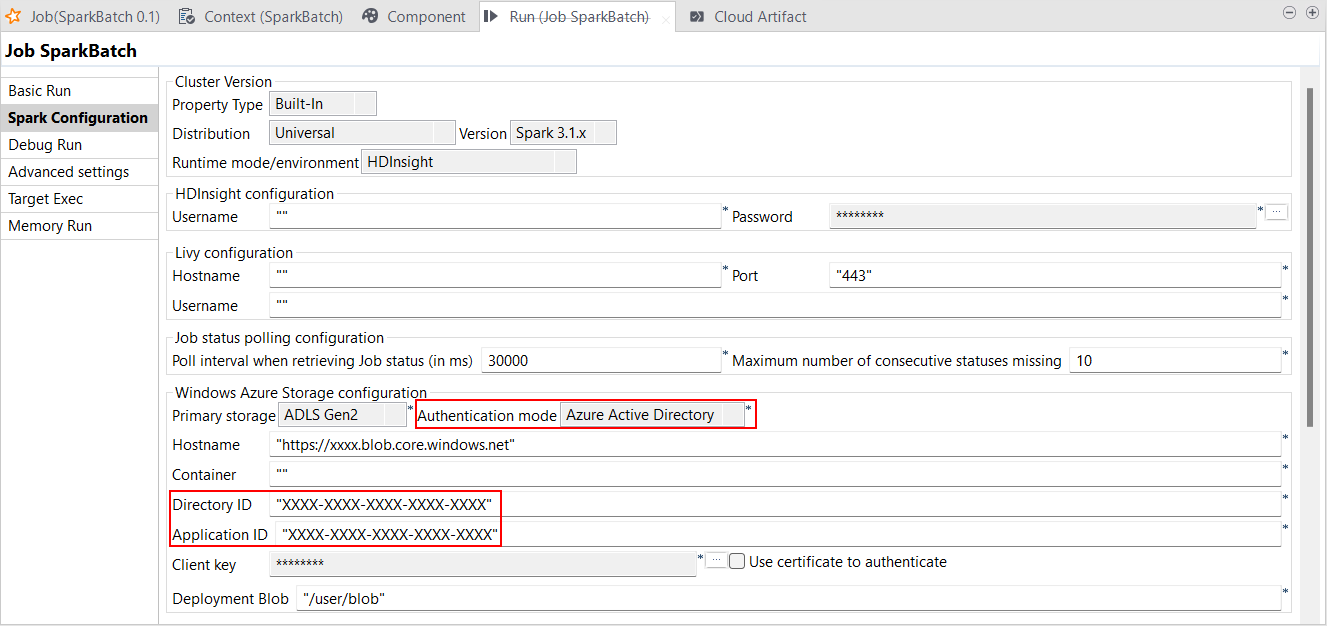 |
Alle abonnementbasierte Produkte von Talend mit Big Data |