
ビッグデータ
|
機能 |
説明 |
対象製品 |
|---|---|---|
| Spark Universal 3.4.xでDatabricksランタイム13.xをサポート | Google Cloud Platform (GCP)、AWS、Azureで、Spark 3.4.xと共にSpark Universalを使い、Databricksのジョブクラスターと汎用クラスターでSpark BacthジョブやStreamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはDatabricks 13.xのバージョンと互換性を持つようになります。 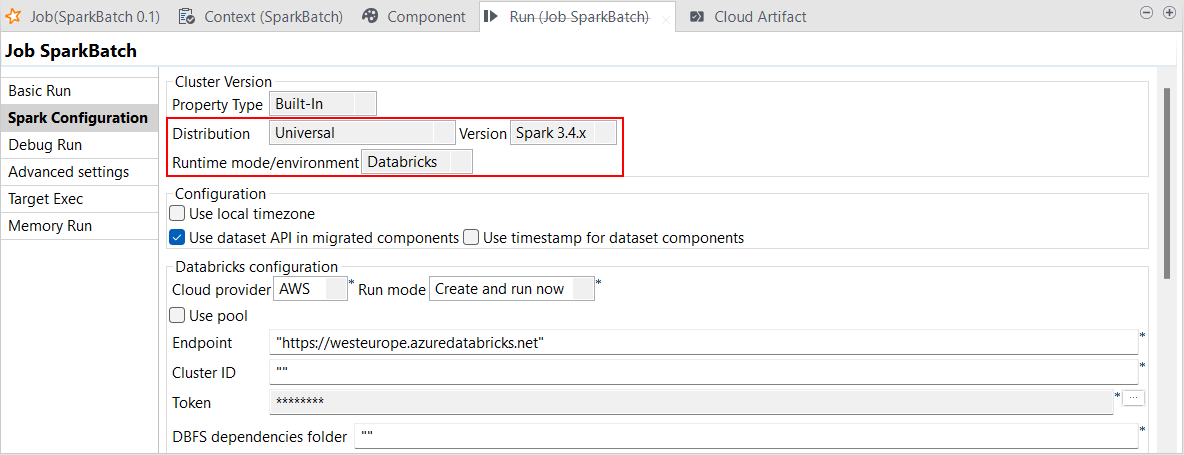 |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| CDP Private Cloud Base 7.1.9をサポート | Spark BatchとSpark Streamingジョブに関し、Talend StudioでSpark Universal 3.3.xを伴うCDP Private Cloud Base 7.1.9がサポートされました。 |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| 標準ジョブでtIcebergCatalogという新しいコンポーネント | 標準ジョブでtIcebergCatalogコンポーネントが利用可能になり、HiveまたはHadoopでカスタムカタログを設定できるようになりました。 また、tIcebergTableの[Basic settings] (基本設定)ビューにある[Set catalog] (カタログを設定)に新しいチェックボックスが追加され、テーブルの作成に使用するカタログを指定できるようになりました。 ![tIcebergTableの[Basic settings] (基本設定)ビューが開き、[Set catalog] (カタログを設定)オプションが選択されている状態。](/talend/ja-JP/release-notes/8.0/Content/Resources/images/ticebergtable-catalog.png) |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
| 標準ジョブでtIcebergOutputでINSERT OVERWRITEをサポート | 標準ジョブのtIcebergOutputで、INSERT OVERWRITE機能がサポートされました。新しく追加された[Use insert overwrite] (INSERT OVERWRITEを使用)チェックボックスを使えば、[All rows from source table] (ソーステーブルからのすべての行)オプションでIcebergテーブルのデータをすべて置き換えたり、[Use a custom query] (カスタムクエリーを使用)オプションでIcebergテーブルのデータをカスタムクエリーの結果で置き換えたりできます。![tIcebergOutputの[Basic settings] (基本設定)ビューが開き、[Use insert overwrite] (INSERT OVERWRITEを使用)チェックボックスが選択されている状態。](/talend/ja-JP/release-notes/8.0/Content/Resources/images/ticebergoutput-insertoverwrite.png) |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |
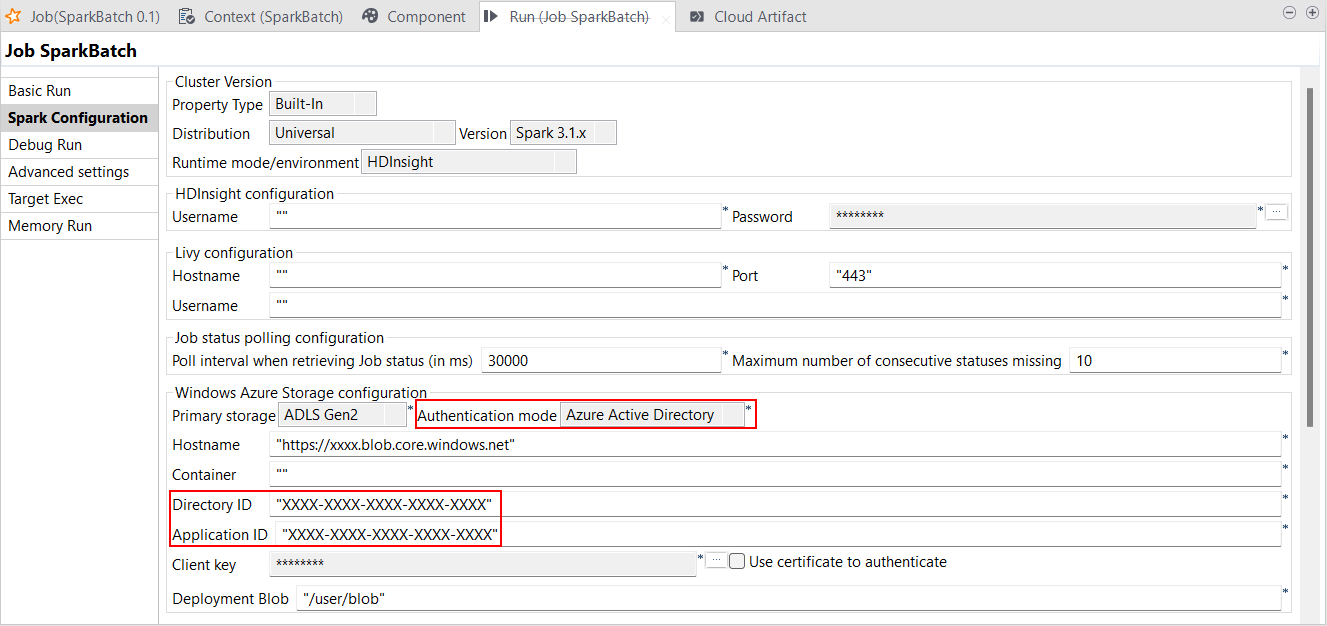
| HDInsightでAzure Active Directory認証をサポート | Talend Studioで、ADLS Gen2とAzureストレージの両方を使ったSpark BatchジョブとSpark StreamingジョブでAzure Active Directory認証がサポートされました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 Talend Studioは次のDatabricksバージョンと互換性があります:
 |
サブスクリプションベースであり、ビッグデータを伴うTalendの全製品 |